
MVCC 的实现:活跃事务列表和时间戳
你是否有疑问,为什么有的系统用一个活跃事务列表(e.g., PG 的 Snapshot,MySQL 的 ReadView)来实现 MVCC,有的系统(e.g., Spanner,TiDB,CockroachDB)用时间戳(Timestamp)来实现 MVCC?这两种技术的优缺点是什么样的,各自适合什么样的场景?本文就来回答一下这些鸟问题。
插播一段絮絮絮叨叨叨的话:我写这篇文章的起因是有同事问了我类似的问题,我大聪明似的联想到我的读者可能也会有类似的问题,就打算写他娘的一篇文章看看能不能骗到一些流量。此外,还有一个原因是最近工作太忙了,没时间好好写东西,但是不写吧又手痒,就打算在周末晚上水一篇文章。
MVCC 的关键
MVCC(Multi Version Concurrency Control) 是一种用来提升数据库事务并发能力的技术,几乎所有的数据库都用到了它。
MVCC 的愿景是:让天下没有冲突的读写操作(阿里巴巴请不要告我,我没抄袭~)
要实现这个愿景,只有数据对象在物理上支持多版本,也就是写操作总是写(创建)新版本,读操作读先前的版本,让读和写分别操作不同的版本,才能做到。(否则读写同一个版本,必须加锁保证数据一致性。)

这个事情看似简单,细想一下就会发现有不少关键问题要解决。主要有:
- 多版本的存储。如何维护版本之间的顺序让读操作可以正确的选择版本?如何存储版本的状态(事务的状态)?事务回滚的时候是立刻 undo 清理掉 aborted 的版本,还是暂且保留待后续垃圾回收?
- 快照的生成。如何低开销的生成一个数据的快照?快照如何排除掉无效的版本(包括 aborted 版本(上图的 v2, aborted),过期的 committed 版本(上图的 v1, committed))和未来的版本(上图的 v4, pending),然后选出来一个正确的版本(v3, committed)?(这里我们暂不考虑 time-travel snapshot。)
关键问题就是要找到问题的关键。活跃事务列表和时间戳这俩货都找到了问题的关键,解决了这些关键的问题(绕你一下~),我们接下来先就挨个看一下这两种方案在各家数据库中的不同实现。
活跃事务列表

上图是 Postgres 的活跃事务列表实现概览,包括多版本存储,事务状态存储,以及包含活跃事务列表的快照。
Postgres 为每个事务分配一个 txn-id,这个 txn-id 从一个单调递增的计数器申请而来。
它的数据存储用的是 heap 表,可以粗略(不考虑空间清理与复用的话)看做是一种 append-only storage。insert 会往文件中追加数据并把 insert 事务的 txn-id 记到 tuple 的 txn-id 字段,update 会先在老版本数据上打一个删除标记(把 update 事务的 txn-id 记到老版本 tuple 上的 delete txn-id 字段),然后再追加一条新版本数据,并让老版本上的指针指向新版本,最终每个 tuple 都会形成一个 old-to-new 的版本链表。对于 写入存储后 aborted 的数据,postgres 不会在事务 abort 的时候直接清理,而是会保留一段时间,直到垃圾回收的时候清理掉。
Postgres 有一个持久化的全局的事务状态表(CLOG),记录着所有事务状态的一个子集。为什么是一个子集而不是全集?因为随着数据库的一直运行,事务数量越来越多,存储的开销增加了,就需要清理掉一些不需要的事务状态。哪些事务状态不需要呢?Postgres 维护着一个水位线(已被垃圾回收处理过的最大的 txn-id),每次垃圾回收完这个水位线以下的 abort 数据都会被清理掉,只留下 committed 的数据。由于水位线一下的所有事务状态都是确定性的 commit,我们就不需要专门在事务状态表里面记录了它们的状态了,事务状态表就可以把水位线以下的事务状态全部清理了。此外,对于 heap 表中水位线以下的 committed 数据,垃圾回收线程会把它们的事务号改为一个专门的 frozen 事务号,读操作读到 frzone 事务号直接特判为 commited,不必去事务状态表查询以节省开销。
如何生成快照?Postgres 把生成快照瞬间的活跃事务列表拷贝到事务的私有内存里,并记录下快照瞬间全局已分配的最大的 txn-id(记做 xmax)。为什么不要快照不需要拷贝 committed 和 aborted 的事务状态?因为这些事务的状态已经是确定性的了,不会被其他事务更改,所有事务可以共享事务状态表中的这一不可变的部分,不需要快照拷贝下来。
用快照读取一行数据的流程中,如何排除掉无效/未来的版本找到正确的版本呢?
- 排除未来的版本:如果这行数据上记录的 txn-id 大于 xmax(拿快照的时候这个事务还没出生呢),或者在活跃事务列表里面,那么它就是未来的版本,忽略。
- 排除无效的 aborted 版本:如果这行数据上记录的 txn-id 在事务状态表是 aborted,忽略。
- 排除无效的 commited 版本:如果这行数据上有 delete txn-id,且 delete txn-id 的对于快照来说是 committed,那么这行数据就是一个无效的 committed 数据(被删除了),要忽略,然后沿着版本链找正确的版本。
(备注:实际的规则比上面这些还要复杂一点。)
排除这些无效的版本后,我们就能找到正确的版本了。
以上就是 Postgres 活跃事务列表方案的多版本存储和快照生成的实现。
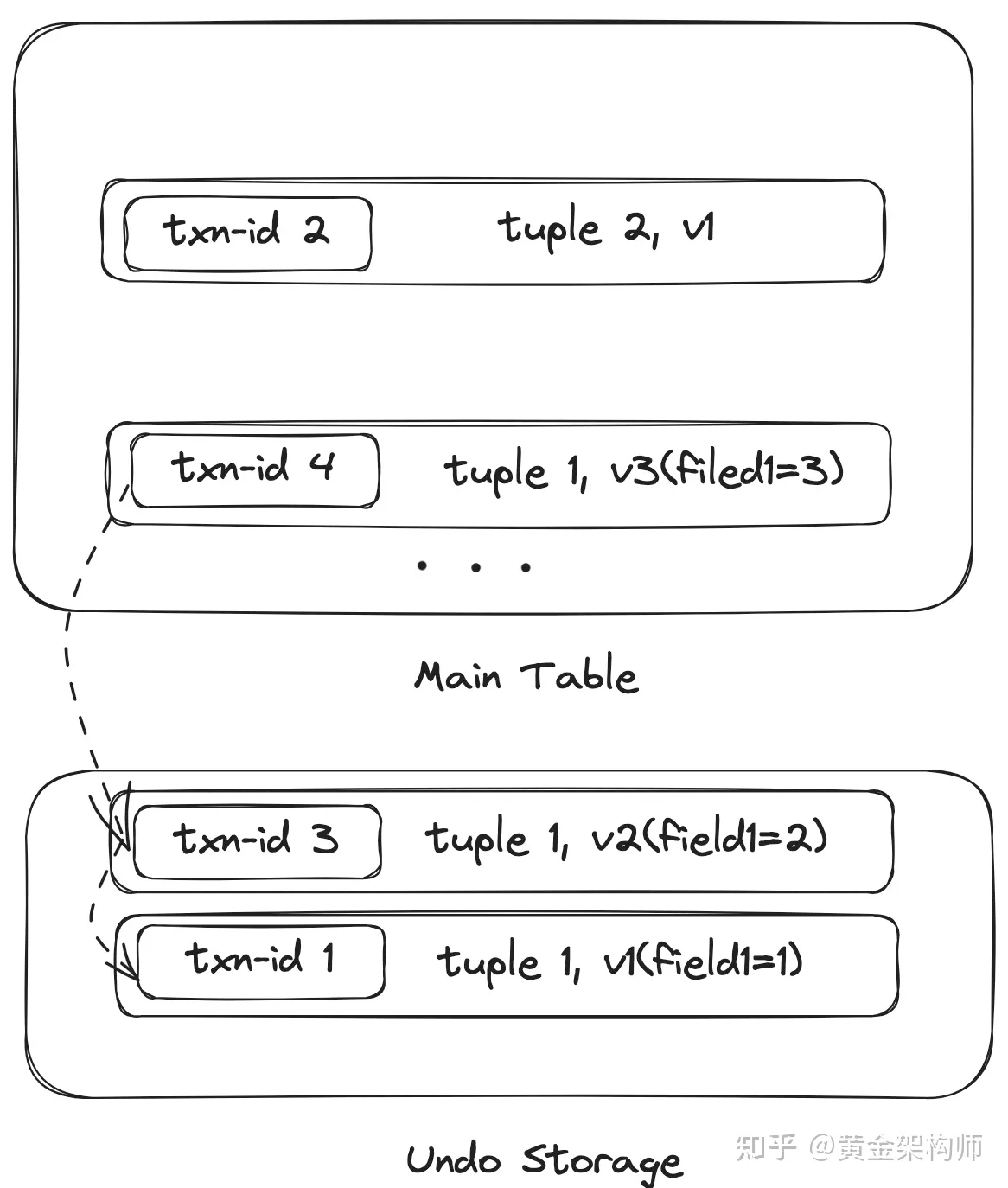 上图是 MySQL(InnoDB) 的多版本存储概览。
上图是 MySQL(InnoDB) 的多版本存储概览。
MySQL 同样是为每个事务分配一个 txn-id。但与 PG 的 append-only storage 不同,MySQL 的数据存储是一种 delta storage。所谓 delta storage,指的就是对 main table 中数据的更新,会把被更新的字段(这就是 delta 部分)备份到专门的存储(undo storage)里面,然后把老版本原地更新为新版本,同时维护新版本指向旧版本的指针。这个做法相比 PG 来说,对读性能更加友好一些,因为老版本不会造成 main table 的数据膨胀,增加读放大。
对于 abort 的事务,MySQL 的处理与 PG 不同,MySQL 是更纯正的 ARIES recovery 算法的继承者(事务不仅记录 redo 日志,还会记录 undo 日志),事务回滚时,会直接把 abort 的版本 undo 一下,直接清理掉。因此数据存储中可以认为不存在 aborted 的版本。这个做法相比 Postgres 来说,在事务状态存储方面简单了很多,aborted 事务的状态不需要较长期地维护。
MySQL 如何生成快照?和 PG 一样,也是在快照瞬间把活跃事务列表拷贝到私有内存里面,实现上大同小异,就不详细介绍了,感兴趣的可以自行查阅相关资料。
小结
本文介绍了 MVCC 的活跃事务列表的实现方案,介绍了 Postgres 和 MySQL 在这个方案下如何实现的多版本存储和快照的生成,下一篇文章将介绍一下 MVCC 的时间戳实现方案,结合一下 TiDB,CockroachDB 等数据库的相关实现,最终会给一个这两个方案的优缺点分析报告。
不讨人厌的广告
我是黄金架构师(知乎和微信公众号同名),数据库产品经理兼职搞一点研发,数据库和大数据领域持续创作者。
如果您觉得这篇文章对您有用,劳烦帮忙点赞分享下,非常感谢您的支持! 如果您还没有关注我,那我给您跪下了,赶紧关注我,我(非常认真地)谢谢你啊!
参考
无,全凭脑子(易失性内存)现编(尤其是 MySQL 的部分),如有错误,欢迎指正~
留下评论