
几张图弄懂 Z-order clustering
你是玩大数据的,你发现主流的湖仓存储都支持 Z-order clustering,你 TM 的还不知道这个是什么玩意儿。我 TM 的花了半个小时,画了 TM 的几张图,九浅一深地给你说明下,什么叫 TM 的 Z-order clustering。
Lexical-order Clustering
在弄明白什么是 Z-order clustering 之前,我们得先弄明白什么是 Lexical-order clustering。
Lexical-order(aka linear ordering) clustering,用人话讲就是把一张表中的数据按照某一列或多列的字母表顺序排好序(多列就先按第一列排,再按第二列排,以此类推),再把排好序的数据按照数据量切分成一段段的,塞到一个个文件中。湖仓存储额外维护文件级别的排序列的 max/max 值统计信息,当我们根据排序列做查询时,如果发现文件的排序列 max/max 值构成的区间对不上我们的查询条件,我们就可以把这类文件直接过滤掉,只读需要读的文件,实现加速查询性能的目的。
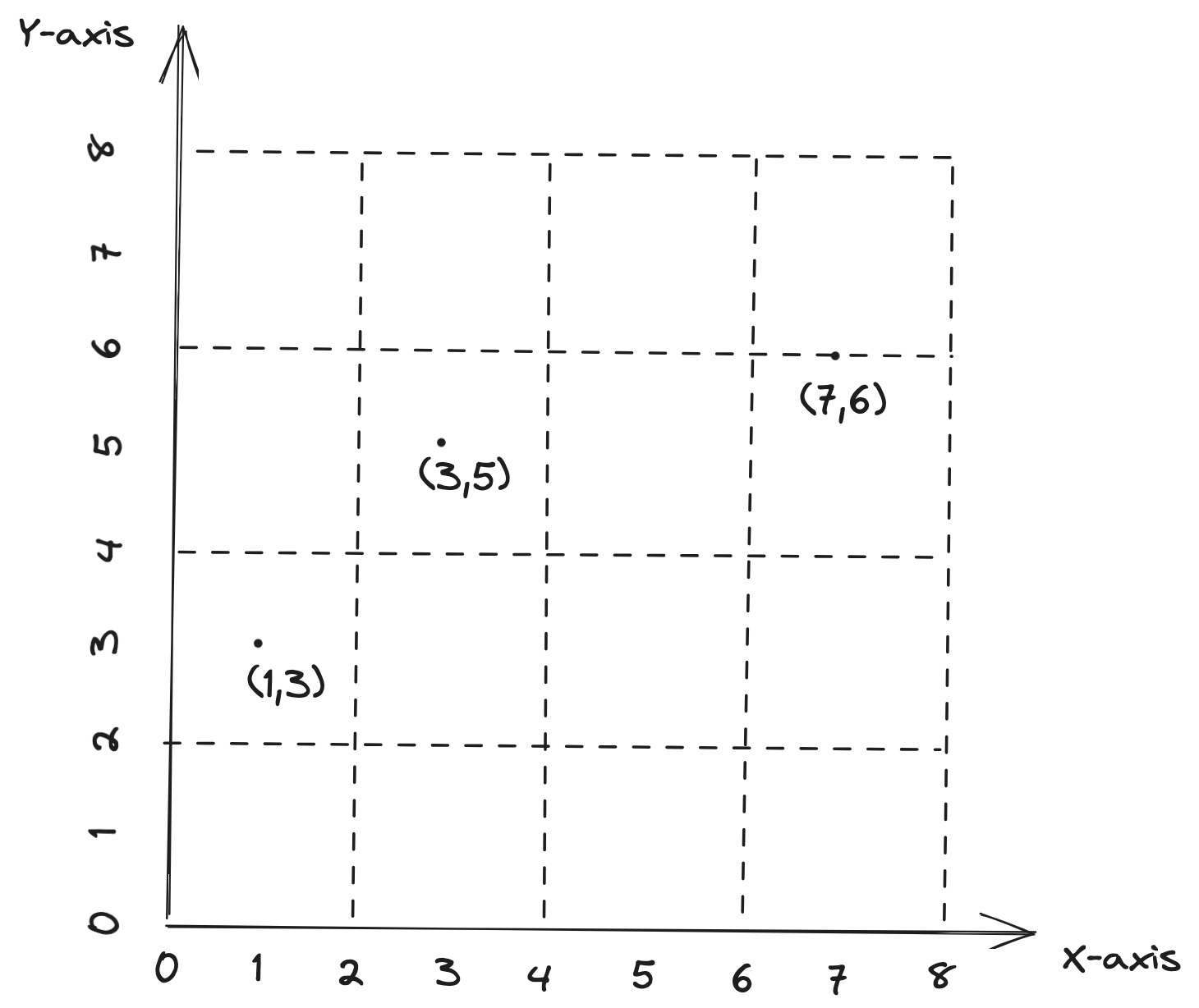
我们看一下例子。假设一张表有 x 和 y 两列,x ∈ [0, 8],y ∈ [0, 8],x 和 y 都是 integer。这张表的数据我们用可以用 x-y 坐标系来表示(如上图所示),x 轴和 y 轴分别对应 x 和 y 列的值域,数据(也就是一些点,e.g., (3,5))分布在坐标轴上(为简化,只画了少量几个点)。对于这张表的数据,我们按照 (x, y) 两列来做 lexical-order clustering,按差不多的大小切分后,形成如下 4 个文件(File 1-4):

不难看出:
- 如果我们的查询按照 x 列来查询,比如查找 x = 5 的数据,我们可以根据这 4 个文件 x 列的 min-max 统计信息,发现 x = 5 的数据只存在于 File 3 中,我们只读取这 1 个文件即可。
- 如果我们的查询按照 y 列来查询,比如查找 y = 5 的数据,这下悲剧了,根据这 4 个文件 y 列的 min-max 统计信息,我们发现 y = 5 的数据在 File 1-4 都存在,我们需要读全部的 4 个文件。
佛说,一念天堂,一念地狱,其实说的就是我们按照 (x, y) 来做 lexical-order clustering,一会想着按 x 查一下,速度快得飞起,像飞升到了天堂,一会想着按 y 查一下,速度慢的抠脚,像坠入了地狱。
你可能会想,按 (x, y) 做 cluster 不行,那按 (y, x) 来做 cluster 呢(数据先按 y 排序,再按 x 排序)?结果是类似的,会形成按 y 查询天堂,按 x 查询地狱的尴尬局面。
TM 的,有没有一种办法,可以让我们即要又要,按 x 和按 y 查询都快速呢?目前我不知道两全其美的办法,只知道一个中庸之道(按 x 和按 y 查询都还行)的解法:Z-order clustering。且看下文介绍。
Z-order Clustering
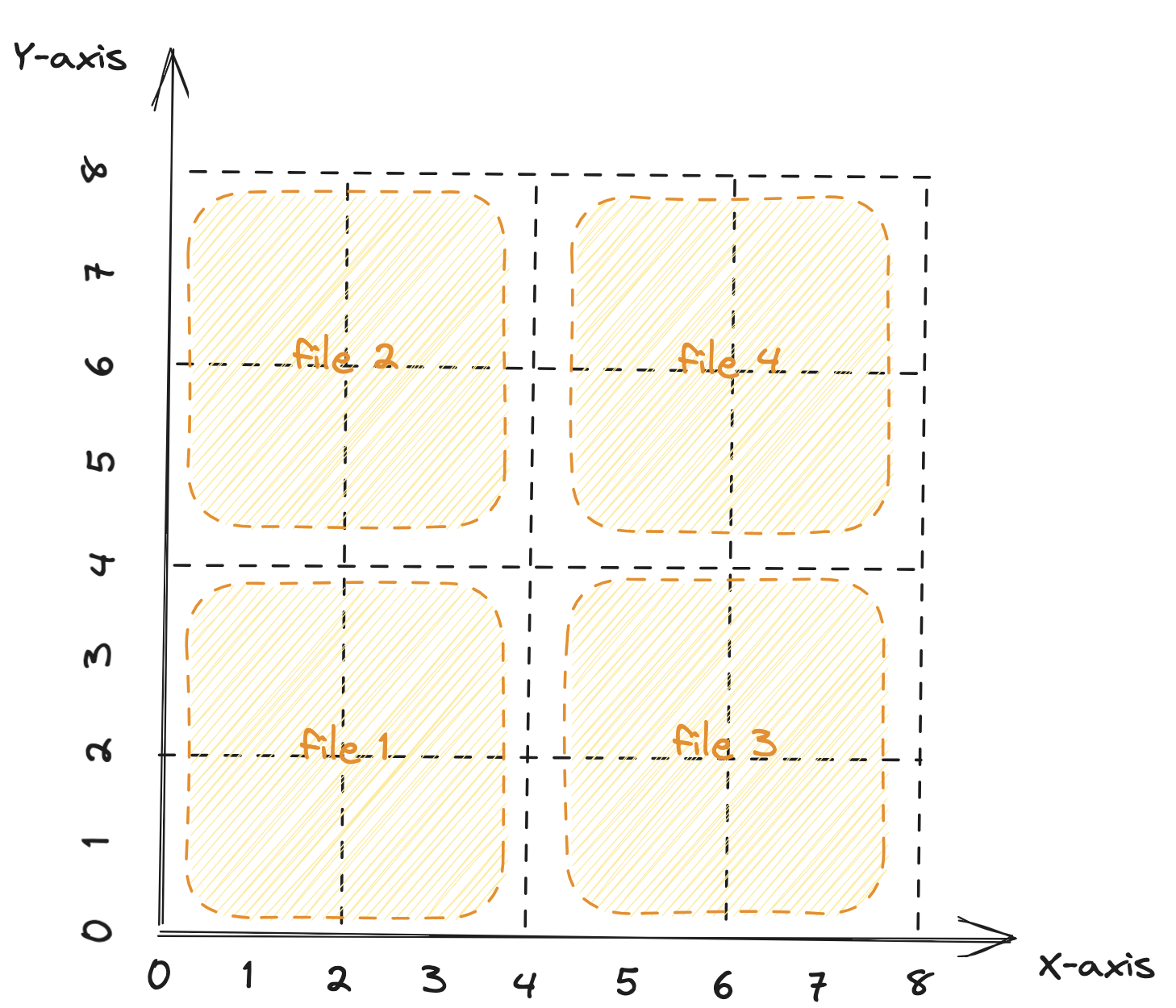
先看一下 Z-order clustering 的效果。我们用 Z-order clustering 处理一下上文中的数据后,大致就成了上图这幅样子。虽然整张表的数据还是被切分成 4 个差不多大小的文件,但是这次不是单纯的以 x 轴来做切分来,而是以 x 轴,y 轴都做切分,形成了 4 个正方形区域(正方形只是为了示例简化,实际什么鬼形状都可能)。
现在,我们按照 y 列查询,查找 y = 5 的数据,我们惊喜的发现只需要读 File 2 和 4 总共 2 个文件了,与原来的读 4 个文件相比,性能提升 1 倍。 不过,细心的你应该已经发现了,尽管我们按照 y 列查询快了,按照 x 列的查询却慢了。查找 x = 5 的数据,我们需要读 File 3 和 4 两个文件,与原来读 1 个文件(File 3)相比,性能降低 1 倍。
这就是 Z-order clustering 的中庸之道:让按照不同列的查询都以差不多慢的速度运行!不好意思,说错了,应该是:让按照不同列的查询都以差不多快的速度运行。
这就够了,总有一些场景能用的上。比如地图场景,按经度和纬度查询,二者要兼顾到;再比如电信场景,按 caller phone number 和 calee phone number 查询,同样要兼顾。
那么这个玩意儿的的原理是什么呢?抽象一点的说法:Z-order 是一种「降维打击」的算法(类似于《三体》中的二向箔),通过将高维的数据编码(降低)到一维,同时在编码后一维的数据上保持高维数据(多个维度)的局部性,使得我们对编码后的一维数据进行排序,在一定程度上保留了高维的所有维度上的有序特征。于是,我们对编码排序后的一维数据做 clustering,高维的多个维度都可以兼顾到,那么按不同维度进行查询,就差不多地快了。
TM 的,说的太抽象了,很难让人懂,我们不妨先看一下下面这个例子,然后再回头来看看上面这段话。

上图中的例子(from wikipidea,略有修改)和我们上文中的例子一样,也是二维的数据,有 x 列和 y 列,仅值域略有不同,它的 x 和 y ∈ [0, 7]。图中还额外给出了 x 和 y 列的值的 bit 编码(e.g., 0->000, 1->001)。
Z-order 编码是一种多列交错 bit 位的编码方式,例如, 数据 (x=0b111, y=0b000) 会被编码为 Z-value (z=0b101010),以此类推。在上图中, x 的 bit 编码为蓝色,y 的 bit 编码为红色,Z-value 的 bit 编码交错式地取自 y 和 x 两列。
对这些编码好的 Z-value 做排序,形成的顺序就是上图红色箭头的顺序,局部是一个 Z 形状,一个个局部的 Z 连起来,就组成了全局的顺序,Z-order 也因此得名。

或许你已经发现了,在经过 Z-order 编码排序后,我们如果把排好序的数据在适当的位置切分一下(切分成四个区间:[0b000000, 0b001111], [0b010000, 0b011111], [0b100000, 0b101111], [0b110000, 0b111111],区间起点和终点已用绿色下划线标注),就能形成我们上文中提到的 4 个正方形区域了。
Z-order clustering 应用到上文中的图上,大致就是下面这个样子:
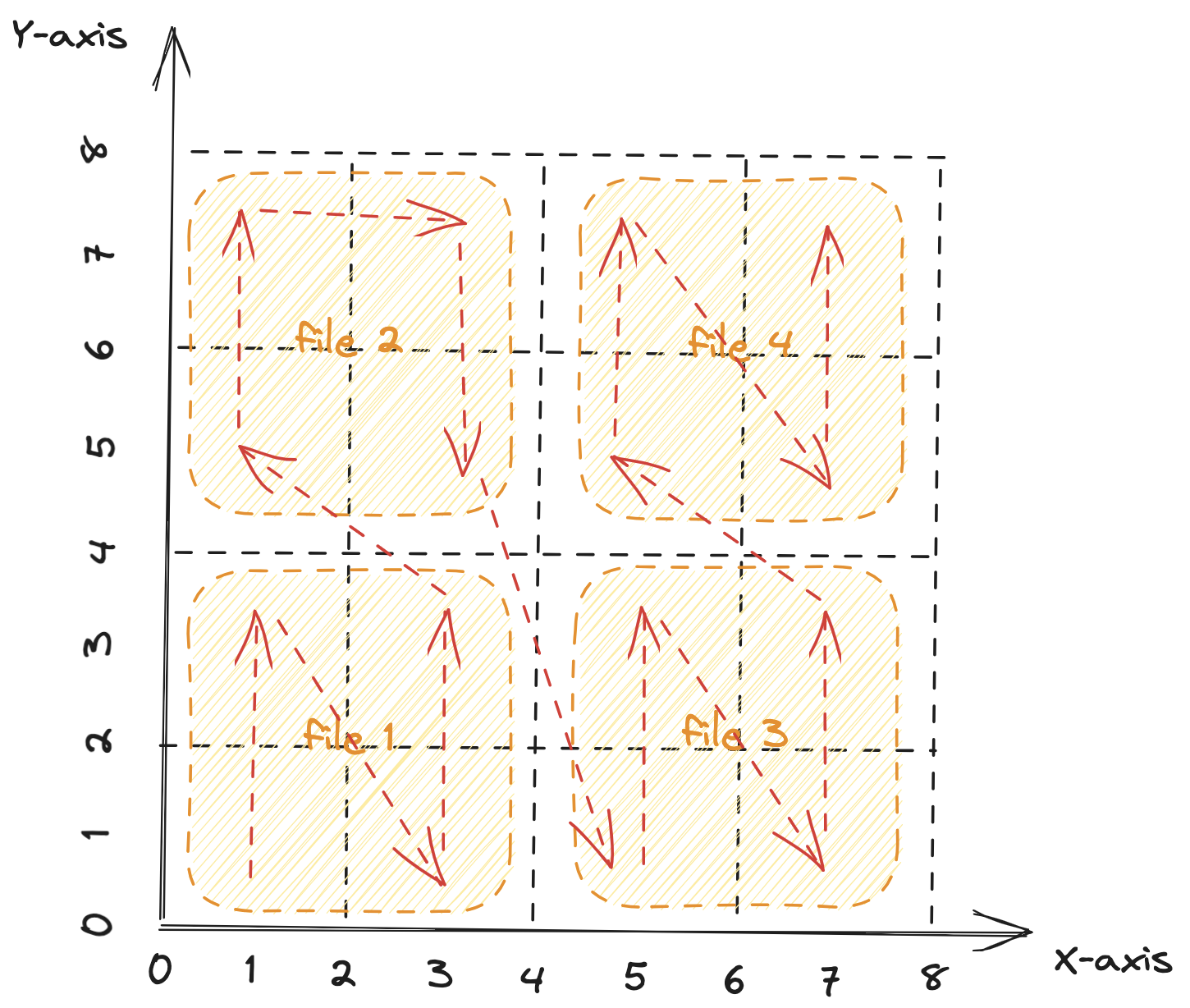
至此,我们通过 Z-order clustering,重新组织了数据文件,做到了按 x 和按 y 查询差不多快。目标达成!
更高的维度
上文的例子全部是二维的(只有 x, y 两列)例子,这里给一幅图体会下 Z-order 在更高维度(三维)下的模样:

应用场景
以 x, y 两列为例:
- 如果你 TM 的只用一列做查询,那么就用这一列做 lexical-order clustering 就够了。
- 如果你 TM 的用 x,y 两列做查询,但 x 列的基数很小(不同的值非常少),那么按 (x, y) 两列做 lexical-order clustering 也足够了。因为在 x 列的基数很少的情况下,y 列会形成少量几个局部有序区间,这种情况下按 y 列查找速度也是比较快的。
- 如果你 TM 的用 x,y 两列做查询,且 x 列和 y 列的基数都很大,那么你可以用 Z-order clustering 来让按 x 和按 y 列的查询都做到差不多地快。
- 如果你 TM 的不知道用 x 查询的多,还是用 y 查询的多,也不知道 x 和 y 的基数怎么样,我的建议是:回家考公务员,你适合当领导!
后记
最近文章有点暴躁,大家见谅下,若造成不良后果我全责。
广告时间
欢迎关注我的知乎和公众号:黄金架构师。
留下评论