
RocksDB 如何优化 LevelDB 的写入流程 (一)
本文的主要内容:
- 介绍 LevelDB 的写入流程。
- 介绍 RocksDB 对 LevelDB 写入流程的部分优化(下一篇文章再补充其他优化)。
Naive 写入流程
在了解 LevelDB 和 RocksDB 的写入流程之前,我们先来看看 naive 的 LSM-tree 写入流程是怎么样的。
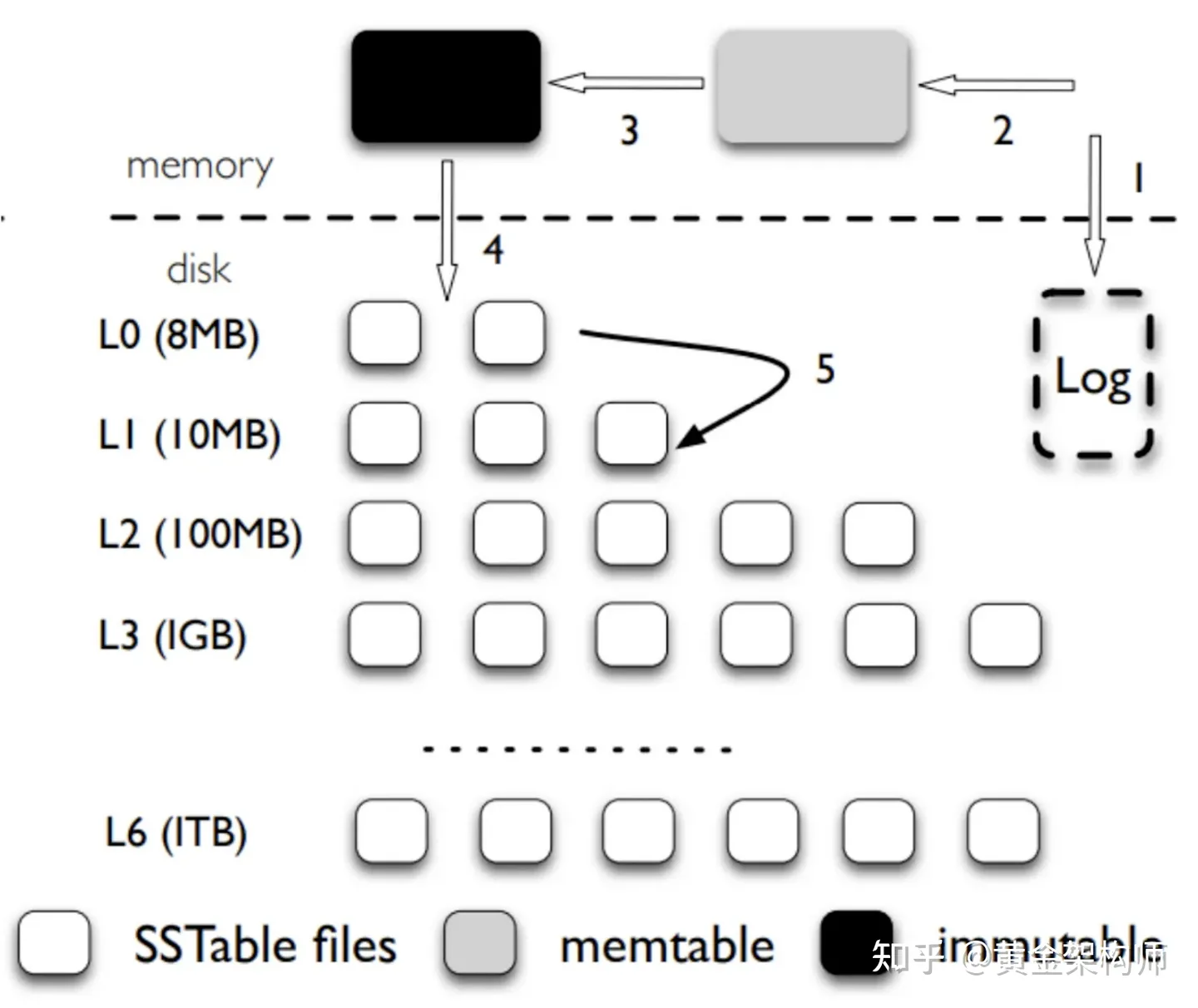
假设我们要往一个支持持久化的 LSM-tree 写入一个 KV,至少需要经过几步呢?我想最简的步骤大概是这样的:
- 把这个 KV 追加写到 WAL 日志,并强制刷盘(保证持久化)。
- 把这个 KV 写入到 memtable。
如有允许并发的话,上述两个步骤还需要用临界区来保护一下,让它们串行执行,以此保证日志与数据的一致性。
不出意外的话这个做法的性能会不出意外的差。上述两个步骤,步骤 1 是瓶颈的大头,因为刷盘操作昂贵,以 HDD 为例,HDD 刷盘时延 5ms,1 秒只能刷 200 次,换句话说,LSM-tree 的写操作会被步骤 1 限制到 200op/s(加并发也没用,HDD 不支持并发)。步骤 2 是瓶颈的小头,主要是一些 CPU 上的操作,要是优化好步骤 1 后没事干了,可以再考虑一下优化步骤 2。
那么 LevelDB 的写入流程是怎么样的呢?它做了哪些优化?
LevelDB 写入流程
TL;DR: LevelDB 对 naive 的写入流程做了 batch 写 WAL 优化(或者叫 group commit,其实也是老掉牙的技术了,不是什么新鲜玩意儿)。
了解 LevelDB 的人都知道它有一个 WriteBatch 的概念,WriteBatch 表示一批 KV,LevelDB 允许以 WriteBatch 为单位写入(批量写入),而不是以单个 KV 为单位一个一个写入,这已经是一层 batch 的优化。不过需要注意,这个优化是需要 RocksDB 的用户来协作(构造 WriteBatch)的。倘若用户故意不协作(恶意单个单个的干),或者协作后性能还达不到要求怎么办?LevelDB 写入流程里面第二层的 batch 就适时登场了。
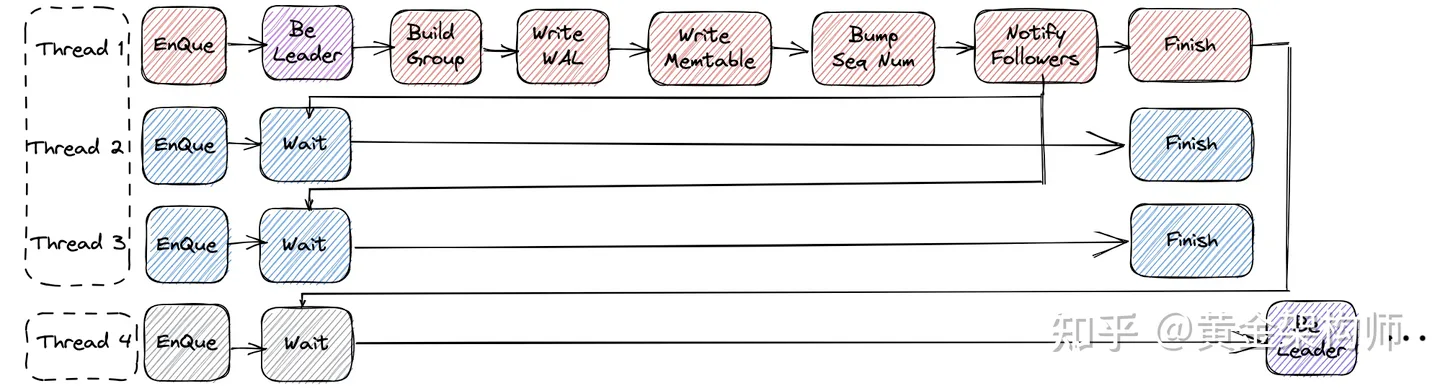
LevelDB 的写入流程如上图所示,我将之归纳为「三步走」战略(向你党惯用法靠拢):
- 步:紧急集合!这一步将形成出一个 batch。并发的写线程(Thread 1,2,3)入队集合,第一个到的(Thread 1)由于行动迅速被选为组长(Group Leader),这一组的人形成了一个 batch(准确的说是 batch of batches,因为它是 batch of WriteBatches。)。有些反映迟钝的人(Thread 4)来的慢了,只能去下一组了。
- 步:看我表演!这个新小组的组长喜欢亲力亲为,让其他人都先休息一会(Wait),自己一个人来干所有人的活,先收集所有人的东西(Build Group),然后干活(batch Write WAL,一个一个写 memtable),最后发布一下干活公告(Bump Sequence Number),告诉外界我们的活干完了,你们可以欣赏「我们」的成果了。
- 步:原地解散!组长干完活了,通知一下大家,告诉大家解散。还会顺便通知下个组的组长,轮到你(倒霉)了(后一个组等前一个组干完活通知后才开干,这意味着「干活」是一个组之间互斥的事情,是串行搞的)。
点评一下这个流程的优点:相对于 naive 的流程,WAL 刷盘的代价被均摊,一次刷盘能持久化多个写操作而不是一个,理论上性能可提升数倍到数十倍不止(取决于并发线程数,换句话说,取决于 batch 的效率)。
缺点(优化的空间):
- 写 metable 仍然是串行一个一个写的,太慢了有待提升。
- 写 WAL + metable 这两个步骤整体上作为一个原子操作(即上面的「干活」),多个组之间是串行执行的,并发度有待提升。
补充:为一些不熟悉 LevelDB 的读者说明一下为什么有 Bump Sequence Number 这一步骤。LevelDB 是支持原子提交(Atomic Commit 或者说 Atomic Read)协议的,一个 WriteBatch 中的所有 KV 要么全提交(全被其他事务看到)要么全失败(全被其他事务看不到)。这就是通过:
- 读操作会取最新的 sequence number 作为快照,只能读到 < sequence number 以下的写入。
- 写入流程中写完整个 WriteBatch 后才整体推进 sequence number (而不是写完 WriteBatch 中的一个 KV 就推进一下 sequence number)
实现的。上面 batch 的流程更进一步,写组长会在写完 batch of WriteBatches 才推进所有 WriteBatch 累计后的 sequence number。
RocksDB 优化
优化 1:并发(写 memtable)
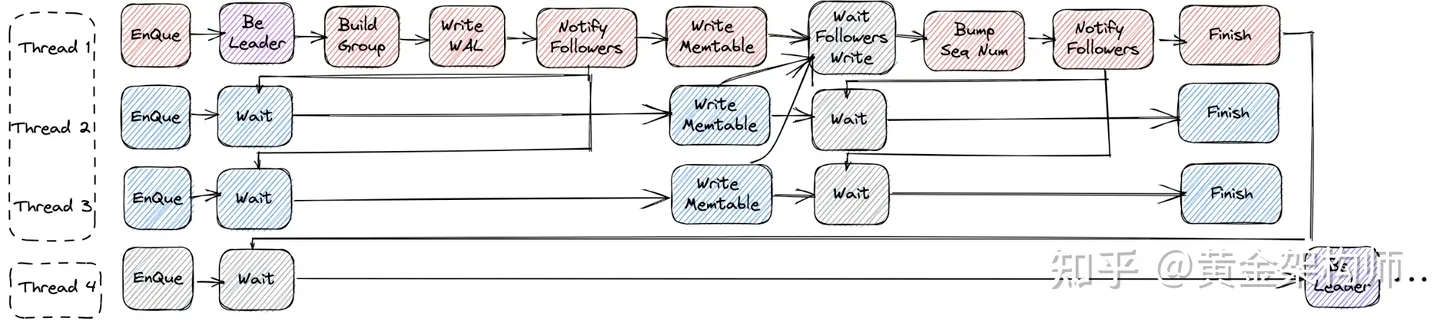
针对串行写 memtable 的问题,RocksDB 支持了并发写 memtable。
为了支持并发写,RocksDB 先是实现了 memtable 数据结构(Skiplist)的并发写,打好了基础。
引入并发写 memtable 后,RocksDB 写入流程的三步走大概如下:
- 步:紧急集合。这一步和 LevelDB 没什么不同。
- 步:齐头并进。这是与 LevelDB 最大的不同之处。RocksDB 的写组长在写完 WAL 后,会去通知一下所有的组员(Notify Followers),大家同时各写各的 memtable,组长等所有人都写完后(Wait Followers Write),再更新一下干活公告。
- 步:原地解散。这一步也和 LevelDB 没什么不同。
点评一下,这个优化增加了写 memtable 的并发度,进一步提升了写入的吞吐量。
不过我们仍然可以看到,写 WAL + memtable 整体上仍是多组之间串行执行的,在并发度上还有进一步的提升空间。
优化 2:Pipeline(写 WAL + memtable)
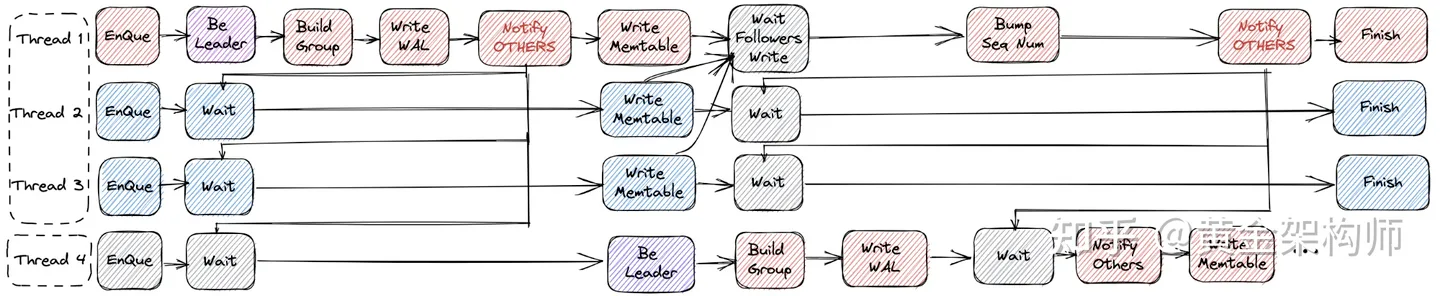
RocksDB 又引入了 Pipeline Write 来解决写 WAL + memtable 整体串行执行的问题。
引入 Pipeline Write 后,RocksDB 的写入流程大致如下:
- 步:紧急集合。同上。
- 步:齐头并进 + 透风报信。这里的不同之处在于,写组长写完 WAL 后,提前透风报信(NOTIFY OTHERS)给下一个组的写组长,我写完 WAL 了,你们现在立刻马上可以开始写 WAL 了。我们组接下来要一起写 memtable 了,我们写完 memtable 后再来给你报信,你们组再立刻马上开始写 memtable。
- 步:原地解散。同上。
我们再搞一个简单的图示来「图文并茂」地说明一下写入流程在时间上的并行情况,引入 Pipeline Write 之前是这样的:
1 组: wal->mem
^
2 组: wal->mem
^
3 组: wal ...
之后是这样的:
1 组: wal->mem
^
2 组: wal->mem
^
3 组: wal ...
药效看起来很明显。于是在这么漂亮的时间上的流水线并行的加持下,写入的吞吐量不得不再次得到提升。
小结
针对 LSM-tree 写入流程中写 WAL 慢的问题,LevelDB 对写入 WAL 做了 batch 的性能优化。
RocksDB 在 LevelDB 的基础上,对 LSM-tree 写入 memtable 做了并发的优化,对写入 WAL + memtable 整体做了 pipeline 的优化。
嗯,LevelDB 不错,RocksDB 更是青出于蓝而胜于蓝。
未完待续
上面的写入流程看似已经「白壁无疵」了,其实还是有吹毛求疵的空间的,下篇文章我们再介绍进一步的优化。
不讨人厌的广告
我是黄金架构师(知乎和微信公众号同名),数据库产品经理兼职搞一点研发,数据库和大数据领域持续创作者。
如果您觉得这篇文章对您有用,劳烦帮忙点赞分享下,非常感谢您的支持! 如果您还没有关注我,那我给您跪下了,赶紧关注我,我(非常认真地)谢谢你啊!
参考
- https://github.com/facebook/rocksdb/wiki/Pipelined-Write
- https://omkarbdesai.medium.com/an-analysis-of-running-different-configurations-of-leveldb-655b13e2e79a (LevelDB 架构图从这里拿来的)
留下评论