
Apache Kudu:Apache Hudi 的刀下亡魂 (一)
我宣布,Apache Kudu 项目,死了!

经过我的诊断(我曾修习过《洗冤集录》,《检验格目》等传统法医典籍,故有资格),它是死于 Apache Hudi 及其朋党之手,被活活砍死的!
本文是一篇法医报告,分析一下 Kudu 为什么被 Hudi 砍!死!了!。
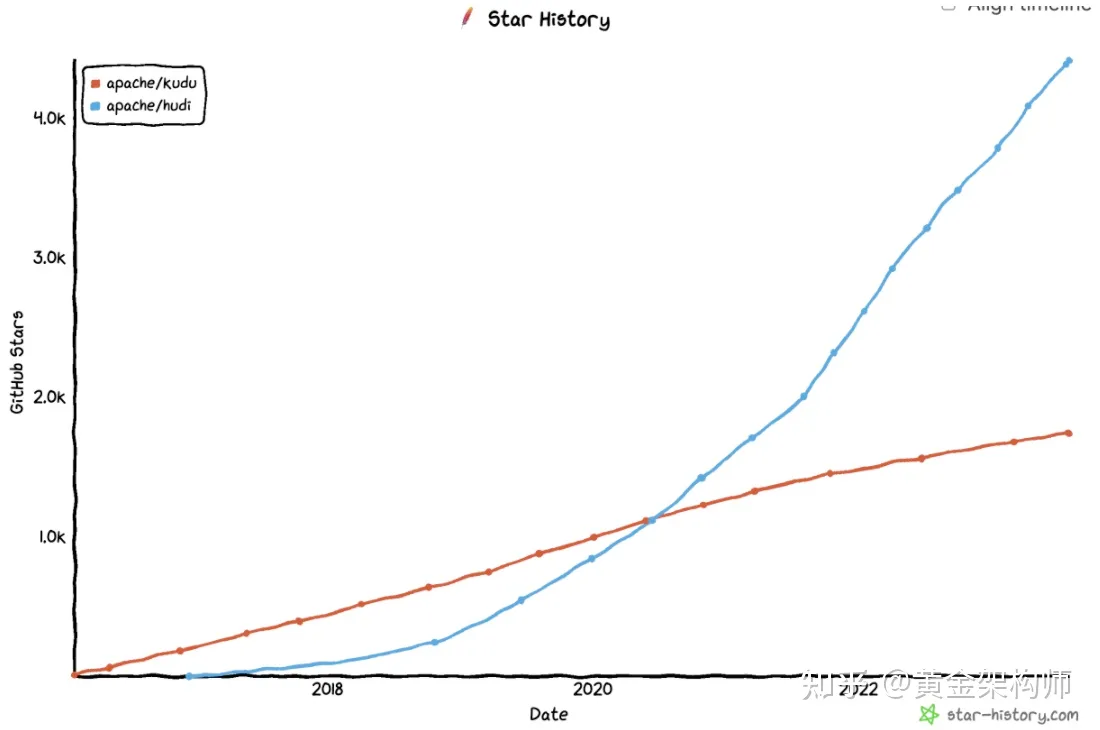
免责声明:本报告乃本法医一家之言,读者「信不信由你」,如若将本报告呈于法庭审理,后果自担。
诞生
我们先来了解一下 Kudu 和 Hudi 诞生的背景。
Kudu 和 Hudi 是一母同胞。它们的「母亲」是基于 HDFS 构建的 Hive-like 数据仓库(e.g., Hive, Impala, Presto, HAWQ)。
这类数据仓库在典型批处理场景(包括跑批任务,交互式分析)下表现的还不错,但在实时场景,包括数据的实时摄入(流式的写入,大量 upsert 的场景;对数据新鲜度有影响),和查询的实时响应(尤其是点查或者小范围查询,其实也算是一种批处理)这两种场景下表现得难堪大用。后文为图简便,用 upsert 和点查代指这两种场景。
这种表现的一部分原因是由于它们的存储底座 HDFS 的特性导致的。HDFS 是一个「能力有限」的分布式文件系统,它只支持追加写文件,不支持随机的更新文件的某一段内容,因此,更新已有文件的一段内容,只能把整个文件拷贝并修改,再替换原有的文件。既然 HDFS 的更新成本如此高昂,这些 Hive-like 数据仓库想支持高效的 upsert,那就是非常不容易的了。于是这些数仓干脆躺平了,只支持数据的批量加载与更新,放弃支持流式地 upsert 了。
(笔者注:其实让 HDFS 支持随机更新并不难,但 HDFS 就是不做,并甩下一句:「爷傲奈我何」。)
另一方面,这类数据仓库也不支持细粒度(record-level)的索引,点查询和 upsert(要先点查是否存在再决定更新或插入)的性能自然也比较差。(尽管这些数据仓库有粗糙索引(每个文件中主键 min-max 统计信息)帮忙,但粗糙索引一是依赖 clustering,二是粗糙索引往往自身不做索引,读取需要全部扫描,在大数据体量下粗糙索引也会很大,扫描一遍不可避免的带来大量的时延)。
如果说 HDFS 的「能力有限」是导致它们如此表现的一部分原因的话,那另一部分原因则是这些 Hive-like 数仓系统没有绞尽脑汁的思考的复盘如何克服 HDFS 的这个缺陷,搞明白底层逻辑,形成新的顶层设计,完善方法论,发力实时场景,完善生态,(此处省略 10w 字。。。)
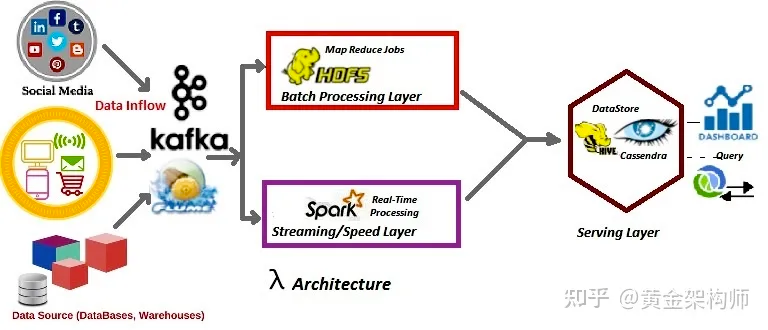
由于 Hive-like 数据仓库只能支撑批处理场景,因此实时场景需要其他小伙伴的帮忙:
- 流计算引擎(e.g., spark/flink)做实时的流计算,并将结果同步到 HBase 之类的低延迟存储。– 流计算先于数据摄入到数据仓库就算好了,规避了 upsert 的问题。Hbase 支持低延迟访问,规避了点查的性能问题。(注:虽然 HBase 也是基于 HDFS 的,但它有「绞尽脑汁」的思考复盘过。)
- 流计算引擎会将上游的数据攒批后(或者不要流计算引擎,直接批量消费 Kafka 数据),写入 Hive-like 数据仓库。– 这均摊了拷贝并更新 HDFS 文件的代价,不过牺牲了数据的新鲜度(数据新鲜度一般是小时或者更差的级别),批处理的场景无法从 Hive-like 数据仓库享用到新鲜的数据,除非把增量数据暂存到 HBase 或其他系统,联邦查询一下。
我们通过引入流计算引擎和低延迟的存储来弥补 Hive-like 数据仓库的不足,以应对完整的业务场景。然而这套方案下来还是让人感到痛苦,这套方案
- 维护的组件过多,技术栈复杂,不好维护,我们不得不问,能不能少一两个组件?
- HDFS 上的数据,新鲜度不够,我们想要实现高新鲜度的批处理/交互式分析,还得联邦查询一下其他系统,这太蛋疼了!
- HDFS 上的数据,缺乏细粒度的索引无法实现低延迟的查询,实时分析方面做得还是太差。
Kudu 和 Hudi 在这个背景下诞生,它们的重要任务(之一)就是解决这些问题。
Kudu 简介
Kudu 性格比较刚,它为了解决这些问题,采用了「改朝换代」的方案,敢教日月换新天。
简单解释它的方案,就是 Kudu 认为,HDFS 太挫了,随机更新不行,分布式文件系统访问时延又高,我直接掀桌子,不玩了。

Kudu 不像其他人,它没有搞基于 HDFS 的 shared storage 架构,而是搞了一个 shared nothing 架构,试图自己实现支持高效 upsert/点查的存储引擎以取代 HDFS,问鼎大数据生态的存储底座。

Kudu 的架构如上图所示。Kudu 集群由两个子集群组成。
- 数据集群。一个基于 Raft 实现的分布式事务型列存引擎。集群中的数据被分片成一个个 tablet,每个 tablet 是一个 raft group。熟悉 TiKV 的小伙伴可以简单理解成一个列存版本的 TiKV。
- 元数据集群。负责集群的元数据(table schema,tablet distribution)信息存储,以及集群的一些管理调度工作(如 tablet rebalance)。注意,元数据集群只在一个专用 tablet 上,不支持分片,scalibility 稍微有点受限。
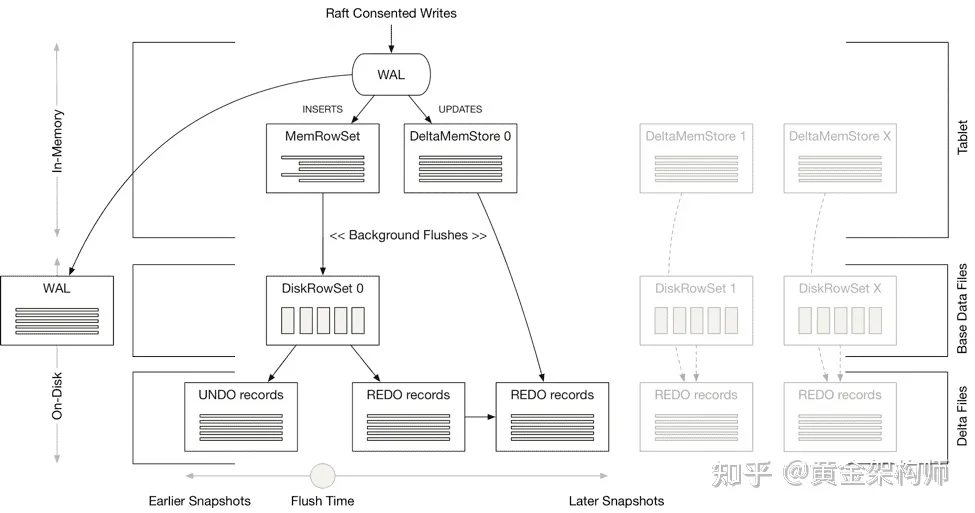
我们具体到单个 tablet 内部看一下。
Kudu 的存储采用的是 delta-main 的列存架构(可简单理解成一个只有 memtable 和 L0 的 LSM-tree)。
Kudu 增量数据的插入会写入到内存中面向写优化的行存(基于 MassTree 实现)的 MemRowSet,然后持久化 WAL 日志就算完成了。后续周期性地刷盘新生成一个新的面向读优化的列存 DiskRowSet(文件)。准确点说 DiskRowSet 是行列混存,也就是所谓的 PAX 格式。DiskRowset 中的数据被切分成一个个几百 K 的 block,block 内部按列存储。
对于特定 DiskRowSet 的更新,会先写入到它在内存中对应的 DeltaMemStore,同样持久化 WAL 日志就成。后续周期性地刷盘成为这个 DiskRowSet 的 REDO records(文件)。
Kudu 的读取需要合并 DiskRowSet 和 REDO records。
为了优化读性能,Kudu 还用到了以下手段:
- Compaction。周期性对 DiskRowSet 和 REDO records 文件做 compaction,以避免读取时需要合并 DiskRowSet 和多个 REDO records 文件。
- 文件级别索引。Kudu 中的表都是有主键的。然而,DiskRowSet 是按照时间周期性的刷盘的,DiskRowset 之间并没有按照主键排序。针对主键的查询,我们是没法知道它在那个 DiskRowSet 中的。于是 Kudu 增加了 DiskRowSet 文件级别的 min-max 统计信息,以及每个文件配备一个主键的 bloomfilter,用来在根据主键查询的场景快速过滤掉无用的 DiskRowSet。
- Record 级别索引。在生成 DiskRowSet 的时候,同时创建一个 DiskRowSet 内的 B-tree 索引。当我们根据手段 2 跳到 DiskRowSet 文件后,接下来就可以根据 DiskRowSet 内部的 B-tree 索引进一步定位到 block,大大提升根据主键的查询性能。
- Block cache。Kudu 的数据 block 比较小,为了优化查询性能,数据 block 会缓存在内存中,这类似于 HBase 的 block cache。
最后提一下,考虑到 Time Travel 和 Restore 需求,Kudu 还会为 DiskRowSet 保留旧版本数据到 UNDO records(文件)。
这里答一下问题,为什么 Kudu 解决了高效的 upsert 和点查问题?
- 对于 upsert,Kudu 的写入是写到内存行存 memtable,并记录 WAL 日志。如果 Kudu 用 SSD 存储的话,就能做到百微秒级级时延了,比 Hive-like 数仓的不知道高效多少个数量级。
- 对于点查,Kudu 有着文件级别和 tuple 级别从粗到细两种索引,性能出色。(畅想一下,要是 Kudu 再支持一下二级索引,TP 场景也能搞一搞,HTAP 指日可待?其实叫 HATP 更合适一些,因为 Kudu 中一等公民显然是 AP,二等公民才是 TP。)
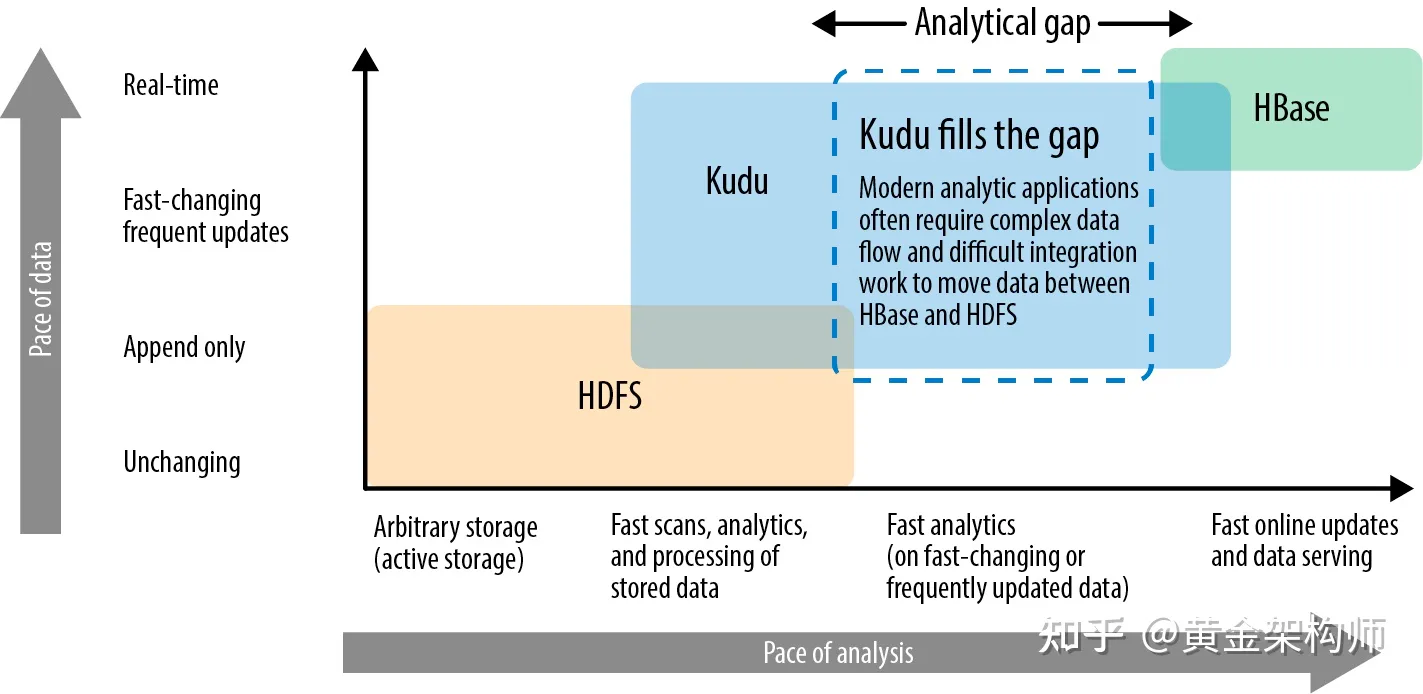
当然,Kudu 做到了这些不是没有付出代价的,它的代价就是牺牲了一些大范围 scan 的性能,因为它在很多方面对点查的性能做了让步(如采用较小的 block size,破坏了列数据的局部性,削弱了按列压缩的能力,导致 scan 性能降低)。最终,我们看到的 Kudu,其实就是一个具备 HDFS 和 HBase 双重特性的产品,两方面能力都能兼顾一些(屏幕前的你小子可不要理解成两方面能力都差一些!)。
未完待续
由于时间关系(我这里已经是周日晚上 10 点了),本文暂时先写到这里(尽管我内心万般不愿),下周我会更新一下本文续集,介绍一下 Hudi,顺便向各位汇报一下 Kudu 的死因。
广告
各位读官如果觉得写得还不错,烦请关注一下我的知乎和微信公众号吧,搜索「黄金架构师」即可。谢谢支持~
我会持续创作数据库/大数据/云计算领域内容,定不负您小手点的那一下关注。
参考
- https://kudu.apache.org
- https://www.oreilly.com/library/view/getting-started-with/9781491980248/ch01.html
留下评论