
从 SIGMOD 22 论文看 Redshift 的最新进展
Redshift 是 cloud-native 数据仓库的鼻祖,是值得我们持续重点关注的数据库产品之一。前段时间,Redshift 团队在 SIMMOD ‘22 上发表了一篇论文介绍 Redshift 的最新进展,本文来跟进解读一下。
在进入本文正文之前,我们先来简单回顾下初代 Redshift。初代 Redshift 产品发布于 2013 年,论文发表于 2015 年。从技术的角度看,初代 Redshift 与一些传统(on-premises)数仓差异不大,它的真正创新之处把传统的 MPP 数仓挪了个窝,搬到了云上,搞成了所谓的 cloud-native。俗话说的好,「人挪死,树挪活」,Redshift 这个换了个环境的 MPP 数据库立刻呈现出旺盛的生命力,像生物入侵一样,迅速地侵占传统数据库厂商的地盘,切下一块块蛋糕。

我认为,cloud-native 赋能给初代 Redshift 相对于传统数仓的两点显著优势:
- 成本低。云的规模经济效益 + 按量付费模式使得建设数仓的总体成本大幅下降。同时,建设数仓所需的硬件设施支出模式由资本型支出(Capital Expenditure)转变为运营型支出(Operating Expenditure),使得总体成本更加可控。AWS 在自己的博客中宣称:「We designed Amazon Redshift to deliver 10 times the performance at 1/10th the cost of the on-premises data warehouses that are commonly used today」。(这是和 Hive 比较的出来的结论?不知和 Vertica,Teradata 比怎么样?)
- 体验佳。Redshift 优化了大量交付运维调优工作的效率。先说数据库交付,传统数据库的交付需要大量前期工作(e.g., 商务协商,部署,POC 等),交付时间按月计,在 Redshift 这里可以做到分钟级开通(按量付费模式,开通不花钱)并部署一个可用集群,还送你一些免费额度去让你去体验。再说数据库运维,Redshift 集群扩容,备份恢复等工作都是控制台用鼠标点两下就搞定。最后说数据库调优,Redshift 大大简化了调优参数,客户只需要关心简单的几个参数就可以了,进一步为客户省心省力。(交付,运维,DBA 瑟瑟发抖,快失业了。。。)
初代 Redshift 一直保持 cloud-native 带来的领先优势直到 2014 年(没记错的话),这一年一家云中立的数据仓库厂商提供的数仓产品 Snowflake 崭露头角。如果说 Redshift 是 cloud-native 的话,Snowflake 简直就是 cloud-born——完全从零开始专门为云环境设计的一款数据仓库,相比 Redshift,Snowflake 对云的特性的利用更加彻底,计算存储分离的架构,按需付费的模式,近乎无限扩展的能力,更爽地 SaaS 体验(相比 Snowflake,Redshift 自称的 SaaS 其实更像是一个 PaaS,实际上客户还是要关心一些技术问题)。Snowflake 这么嚣张,Redshift 自然不会坐视不理,SIGMOD ‘22 的这篇论文介绍了 Redshift 在过去这些年所做的诸多工作,告诉我们 Redshift 是如何捍卫自己的鼻祖地位的。(接下来,终于要到本文的主题了。。。)
本文接下来的主要内容,会先简单总结一下 Redshift 团队在初代 Redshift 之后所做的工作,然后再挑几个感兴趣的方面展开聊一下。
Redshift 团队在初代 Redshift 之后所做的工作,我按照我的认知分类列成了以下几点:
- Cloud-native(包括弹性,Scalability,易用性等)
- 基于 RA3 (with redshift managed storage) 实例的存储计算分离架构,热数据缓存在计算节点的 attach 的 SSD 上(SSD 由 RMS 托管,与计算节点是分离的,下文会介绍 RMS),全量数据存储在 S3,计算和存储可独立扩展(vs Snowflake 存储计算分离架构)
- 支持 Auto-scaling Clusters,即根据 workload 的需要自动扩容额外的计算集群来增加算力
- 支持 Compute Isolation Clusters,可以用来隔离 ETL 和 BI 集群的 workload(vs Snowflake Virtual Warehouse)
- 支持 Data Sharing(vs Snowflake Marketplace, Databricks Delta Sharing)
- 结合 AWS Glue 实现 Serverless(vs Google BigQuery,Azure Synapse,甚至应该包括 AWS 自家的 Athena)
- 支持自动运维与调优(非 AI 方法)。e.g., 自动 analyze/vacuum,自动优化用户表的 distribution key/sort key,自动检测硬件故障并替换故障节点
- 支持与 AWS 宇宙无缝对接,包括 S3,Aurora,Lambda,Glue,Segmaker,Kinesis 等。
- Real-time analysis
- 结合 AWS Kinesis 实现秒级实时分析(vs Spark/Flink + Delta/Hudi/Iceberg,Apache Kudu)
- 支持联邦查询 AWS 上的 RDS 数据库(e.g., Aurora)中的实时数据(vs Spark/Flink + Delta/Hudi/Iceberg,Apache Kudu)
- Lakehouse
- 支持通过 Spectrum 插件访问 S3 data lake 上的数据(vs Databricks Lakehouse)
- AI(AI4DB & DB4AI)
- 支持 Auto Workload Management,预测查询消耗的资源,依据排队论调度查询及调整并发度
- 结合 AWS Segmaker 支持 in-database inference 和 remote inference,既可以用 SQL 手动创建/训练/部署模型,也可以利用 Sagemaker Autopilot 自动去做。模型以 UDF 的形式存在,分析师可通过 SQL 直接调用
- 新硬件
- 基于 AQUA 的存储侧硬件加速计算实现计算下推。有两个作用:a) 计算下推到存储侧能减少数据在网络中传输,尽量避免网络带宽瓶颈。b) AQUA 基于 AWS 自研的 Nitro 系统/芯片,FPGA 等技术实现,能够在成本可控的情况下大幅提升计算性能(Redshift 宣称通过 AQUA 可以达到 3 倍于其他三家云数仓的 price performance。其他三家是谁论文里面没有明说,我猜 Snowflake,Azure Synapse 和 Google BigQuery 应该是各占一席)。
- 查询编译与执行
- 支持 code generation(生成 C++ 代码)和向量化 Scan 提升执行性能。通过 CaaS(Compilation as a Service) ,一个编译缓存服务,减小 SQL 编译带来的的开销。
- 多模
- 支持 SUPER 类型存储非结构化/半结构化数据,可以通过 PartiQL(一种 SQL 扩展)直接查询。
系统架构
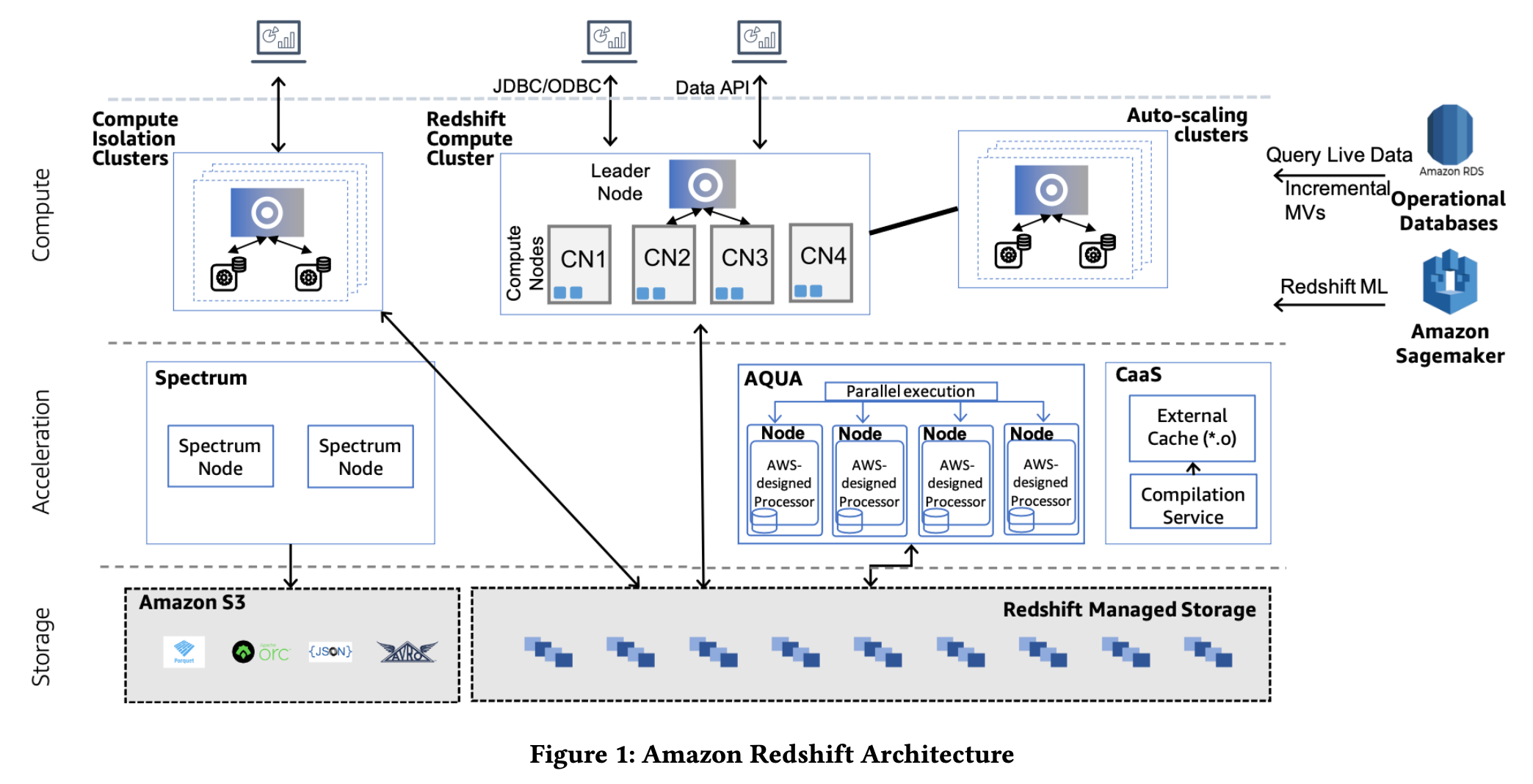
逻辑上看,Redshift 分为了三层:
- Compute
- 首先,最基本的部署配置,只会有一个 Redshift Compute Cluster(下文统一叫这个集群为主集群),包含一个 Leader Node(存元数据,与客户端交互,查询编译),多个 Compute Node(查询执行)。
- 其次,在主集群负载过高的情况下,Redshift 会自动扩容出额外的计算集群 Auto-scaling clusters 增加算力。用户查询会从主集群的 Leader Node 给 dispatch 过来(按我的理解,需要用到的主集群 Leader 节点上的元数据也会 dispatch 过来)。
- 最后,为了实现不同 workload 的隔离,可以创建一大堆的 Compute Isolation Clusters。Compuate Isolation Cluster 甚至可以和主集群从属于不同的 AWS 账号,实现跨客户的 Data Sharing。
- (补充:Compute 层可以联邦查询 RDS 以及远程调用 Sagemaker 中的模型。)
- Acceleration
- Spectrum Node 是 Spectrum 插件起的一堆用来查询 S3 data lake 上的数据的节点,可独立扩展。
- AQUA 用来做存储侧硬件加速计算,上面说过,这里就不解释了。
- CaaS 编译缓存服务,上面说过,这里就不解释了。
- Storage
- RMS(Redshift Managed Storage):Compute Node(RA3 实例)会 attach 到 RMS 上,RMS 管理一堆本地 SSD(我简单理解这个类似 SAN 存储放到了云上) 来 cache 数据,并且管理数据在 SSD 和 S3 之间的来回移动(cache eviction,prefetching,commit 等工作),这些工作对上层的 Compute Node 是透明的。RMS 会存储用户数据和事务的元数据。
- S3 既可以被 Spectrum Node 直接访问,也可以被 Compute Node 通过 RMS 间接访问。
TODO: 展开聊一下上文说好的「感兴趣的方面」
本文此处内容有缺失,待日后有时间再补充。由于本文会同步发布在知乎上,如果有知乎读者希望此处内容尽快得到补充,请帮忙在知乎点赞,THX。
总结
整体看下来,Redshift 给我的感觉就像是一把瑞士军刀,性能不错,功能也十分全面,当下市场上热炒的一些数仓功能该有的都有了(有的功能即便 Redshift 自身没有,也无缝衔接自家产品实现了,e.g., 结合 Kinesis 实现实时分析)。如果非要挑一挑不足之处,倒也可以说上一个:Redshift 还不能支持无限(超高)并发,主集群 Leader 节点的元数据访问会成为单点瓶颈。Redshift 中的每条查询都得访问主集群 Leader 节点上的元数据,包括 a) 主集群执行的查询,b) Auto-scaling clusters 执行的查询要先访问主集群 Leader 节点的元数据然后 dispatch 下去,c) Compute Isolation Cluster 集群也会通过代理服务访问主集群 Leader 节点的元数据。然而,Redshift 并不像 Snowflake 那样,所有的租户共用一个「大」的数据库实例,它是每个租户都使用自己的数据库实例(虽然 Compute Isolation Cluster 会共用实例,不过这种 Cluster 应该数量有限),所以主集群 Leader 节点的并发数应该不会非常高,不会容易遇到这个瓶颈。
参考
本文作者:hhwyt
本文链接:https://hhwyt.xyz/2022-06-12-sigmod2022-redshift
版权声明:本博客所有原创文章均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
留下评论