
从 SIGMOD 23 看 RocksDB 的存算分离实践
改造 RocksDB 使其支持存算分离,这类工作之前就有团队做过,e.g., RockSet 的 RocksDB-cloud。眼看云时代的存储计算分离是大势所趋(从 share nothing 转向 share storage),RocksDB 官方再也按捺不住自己的大刀了,亲自下场,先搞了一个 RocksDB on Distribute File System(DFS) 试试水(支持 S3 也为期不远?),并在 SIGMOD 23 上发了一篇文章《Disaggregating RocksDB: A Production Experience》,分享自己的一些「分离」经验。今天我们就来快速鉴定一下这篇文章有没有东西,亦或者是「有点东西,但东西不多」。

为什么要搞存储计算分离呢,我一般回答这个问题总会提到成本!成本!成本!存算的池化,资源的共享,能够降低成本。然这篇文章给出的回答是提升 CPU 和 SSD 的利用率。(笑了,虽然说是同一件事,但表达的方式不同,还是我格局大一点,这帮搞存储的眼里只有 SSD :))
文中提到,通常机器上的 CPU 和 SSD 资源都是不平衡的,有的由于读带宽限制导致存储空间吃不满,有的存储空间吃满了却又浪费很多的 I/O 或 flash erase cycles。很多服务还会预留很多 buffer 空间然后占着茅坑不拉屎(这是我说的,非原文)。CPU 资源也太死了不方便分享转移。存算分离能解决这个问题,计算存储大家在池子里分享转移,资源利用率大大提升。
除了这个优点,还提到了其他的一些优点(DFS 带来的):
- 减少副本数。原本是本地三副本需要 3 个 RocksDB 节点,现在数据放到了 DFS 上,本地只需要 2 个 RocksDB 节点就可以实现至少同等的可用性,一个干活,一个待机。这两种模式都能容忍一个节点挂掉不影响正常工作。
- 快速的 failover。由于数据在 DFS 上,即便 RocksDB 节点都挂了,也可以快速的启新的 RocksDB 节点继续它的工作,操作同一份 DFS 上的数据,不需要漫长的数据拷贝过程来构建副本。
- 简化应用的存储管理工作。存储全权交给 Tectonic 团队管理,出任何问题诸多应用团队均可事不关己。
- 存储层共享的一些具体的好处。例如可以把 compaction offload 到专用的 compaction 集群。
这个项目所用存储是元宇宙非死不可(Meta Platforms, Inc. (NASDAQ: META),曾用名:Facebook)) 公司的分布式文件系统:Tectonic。关于这个文件系统,也曾发表过文章介绍:《Facebook’s Tectonic Filesystem: Efficiency from Exascale》。考虑到下文的阅读体验,这里我迫不得已简单地介绍一下这个系统。
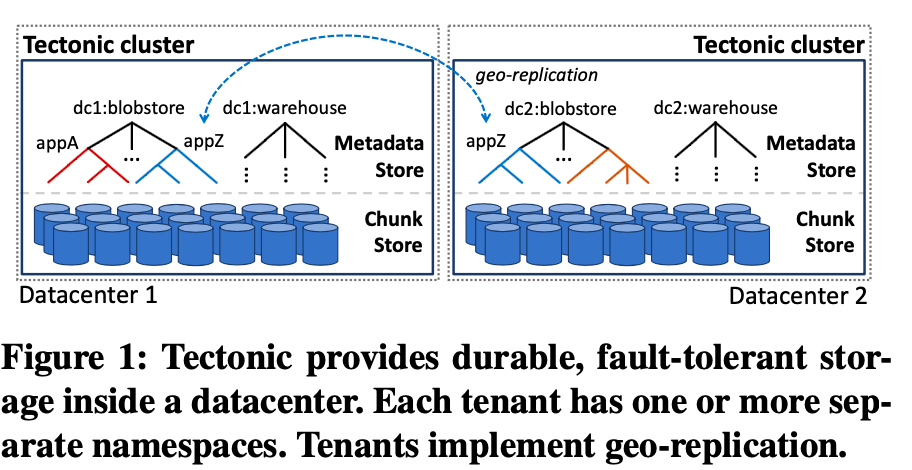

Tectonic 文件系统可以简单看成是一个增强版的 HDFS,面向 write-once read-many 的 workload 设计,支持 append 不支持 in-place update。二者同样都是 single-writer 的设计,即同一个文件同一个时刻只能有一个人写,可以有多个人读。
从架构上来看:
- Metadata Store 功能上对应 HDFS 的 NameNode,用来存储元数据(e.g., 目录树结构)。Tectonic 中的数据层次从高到低:namespace -> file -> block -> trunk。读写的最小单元是 trunk,数据冗余(多副本或纠删码)的最小单元是 block。
- Chunk Store 功能上对应 HDFS 的 DataNode,用来存储用户数据。
- 客户端通过 Client Library 和 Tectonic 交互。读写流程和 HDFS 类似,都是要先问 Metadata Store 要到 trunk(HDFS 的 block) 的位置,然后去对应的 Chunk Store(DataNode) 读写。
- Background Servicess 就是一个管控平台。
相对 HDFS 增强的方面(仅列举我知道的):
- Metadata Store 实现上采用了分布式 KV 存储,支持数据分区,可以水平无限扩展。在 scalibility 这一点可以说是吊打 NameNode。
- 支持多租户,较好的实现了多租户的资源隔离,性能特化。
- 灵活的冗余机制。支持 per-call,block-level 的冗余设置,可灵活选用副本或纠删码机制来保证数据的持久化(简单来说,就是写请求调用的时候设置一下我要写的这个 block 如何做冗余持久化)。为了实现这个 feature,Tectonic 的冗余逻辑是 client-driven 的,包括复制和纠删码的逻辑都在客户端。
此外,和 HDFS 一样,Tectonic 本身是 datacenter-local 的, 不支持 geo-replication。如果想实现 geo-replication,需要在多个数据中心各自部署一套 Tectonic 集群,应用层自己在此之上来实现 geo-replication。
讲完了 Tectonic,准备工作已经差不多了,我们赶紧回到正题。
先来简单鸟瞰一下 RocksDB on Tectonic 的系统架构。
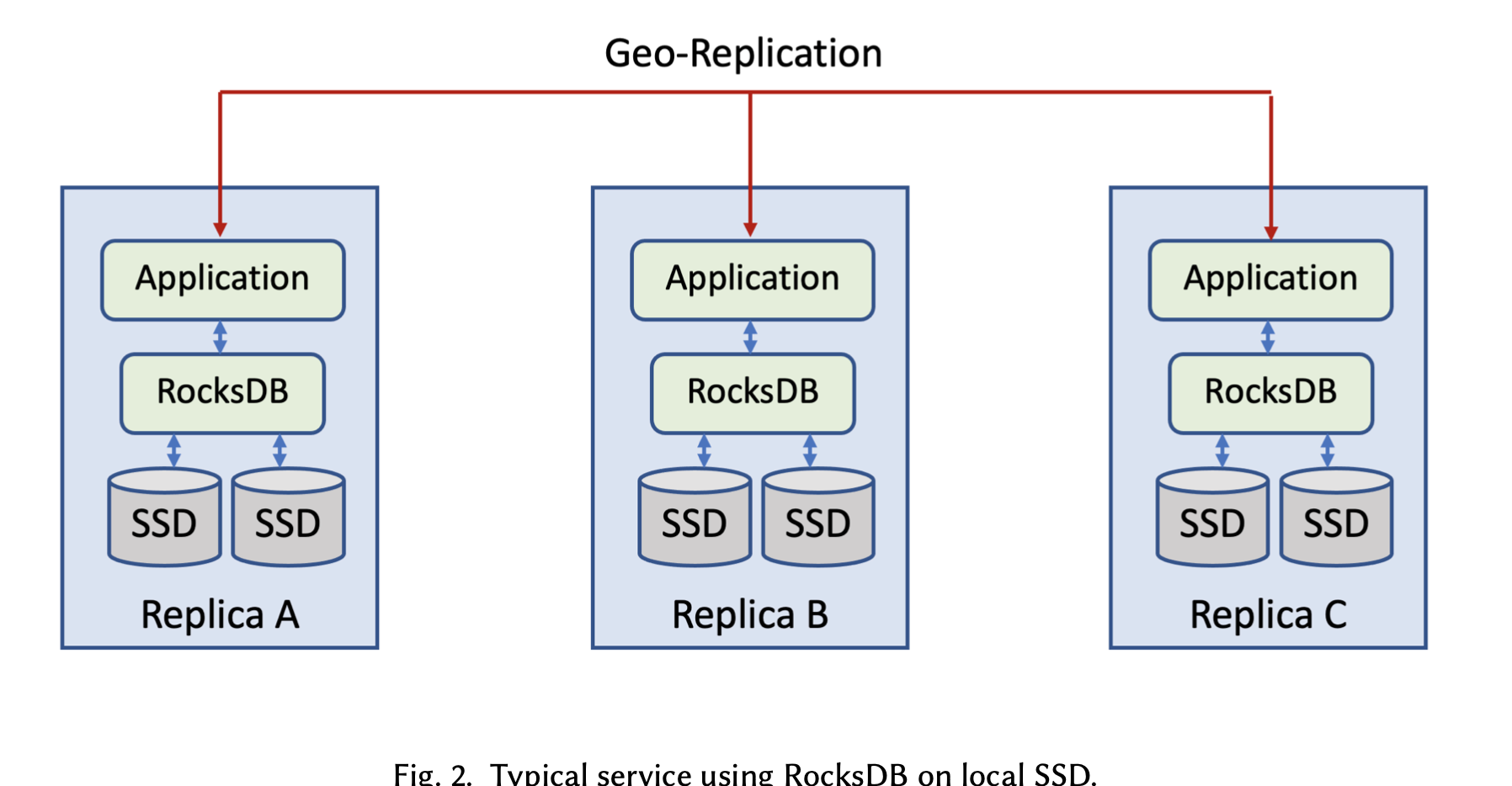

上面两幅图分别描述了存算不分离和存算分离部署两种形态。在 geo-replication 部署模式下,3 副本部署在不同的数据中心。存算不分离架构,每个副本上的 RocksDB 使用本地的 SSD 来存数据。存算分离的架构,每个副本上的 RocksDB 使用本数据中心的 Tectonic 集群来存数据,这个架构中,RocksDB 所在的节点成为了「计算节点」,Tectonic 集群中的节点是存储节点。由于 Tectonic 是 single-writer 的,多个互为副本的计算节点,只能有一个人写数据。理论上其他人可以读数据,但目前尚未支持,其他人只是干看着。
文中列出了需要解决的四个方面的挑战:
- 性能。 底下的存储由 SSD 变成了分布式文件系统,多了网络的开销,势必会带来一些时延。性能方面,这里的目标是小的 Get/Put (KBs to hundreds of KBs) 的 P99 时延小于 5 ms,MultiGet 的 P99 时延在几十 ms。且看下文介绍如何达成这个目标。
- 低开销的数据冗余。上文提到,Tectonic 的数据冗余(多副本或纠删码)机制都在客户端实现,这会给计算节点带来更多的网络开销,如何使用不同的方式来高效持久化 SST 和 WAL 是一个问题。
- Multi-writer 下数据完整性问题。上文提到, RocksDB on Tectonic 是 single-writer 的设计。那什么情况下会出现 mutli-writer 呢?只有一种异常情况下会出现,即一个计算节点挂了,我们让另外一个计算节点替代它干活,如果后续前一个计算节点实际没挂活过来了,两个计算节点就会操作同一份数据,形成 multi-writer 的局面,这种情况下会导致数据完整性被破坏。
- 远程 IO 适配。远程 IO 相比本地 IO 出错更频繁,需要更优雅的处理方式。
接下来看一下通过哪些手段解决了这些挑战。
优化性能的手段
第一是尾延时(tail letency)的优化工作。
主要的思路是如果远程 IO 在一个存储节点上超时了,就尝试切换到另外一个存储节点。
对于读请求,如果采用副本冗余方案,这个思路用起来很直接,先读一个副本,超时了就读另外一个副本。如果采用纠删码冗余方案,会多一些代价但也可以用上。在纠删码方案中,读(direct read)一个存储节点上的 trunk 超时,我们这个时候就做一个 reconstruction read,即把这个 trunk 所在的 block 中的其他 trunk,以及它们的校验 trunk 都读出来,直接算出来那个超时 trunk 的内容,这样就能跳过这个 trunk 的实际读取。代价就是读其他的 trunk 会带来更多的并行 IO。
对于小的写请求(append 写一个或多个 trunk,换句话说,写 sub-block),需要复制到多个存储节点(即便是纠删码方案,也需要复制到多个存储节点,为了性能,纠删码是 lazy 做的,只有持续 append trunk 写满一个 block,才会触发 block-level 的纠删码编码)。为了优化尾延时,这里只需要等 quorum 个存储节点写入成功就返回客户端成功。此外,写请求处理超时和读请求类似,如果超时,就选择另外一批存储节点来写。
由于读写请求超时阈值已经没办法通过人来调参了,这里会记录历史的时延统计信息,据此来动态的调整这个阈值,实现自调优。
对于大块写请求(写入一个全新的 block),由于不需要像 append 一样,必须写入到先前写入定下来的特定存储节点,所以这种请求可以做特殊优化。为了避免写请求废了老大劲把数据传到了 Chunk Store 开始写数据,然而 Chunk Store 资源不够一直不能写,时延无限增加的情况出现,全新 block 的写分成了两个阶段:1. 准备阶段。问一下哪些存储节点有充足的资源(CPU,memory, network-bandwith),让它们预留一下资源。2. 真正写入。发数据过去,写下数据。
第二是 metadata cache 的工作。 RocksDB 有很多 list 目录,检查文件存在,查看文件大小的元数据访问调用。考虑到 Tectonic 上的目录文件是 single-writer 访问的,同一时刻只有一个计算节点上的一个进程访问和修改,很容易就能为这些元数据访问实现一个 cache。
第三是 local flash cache 工作。 访问 Tectonic 上的数据需要远程 IO,时延很高。仅仅靠 RocksDB 原来的内存 block cache 是不够的,一旦 cache miss,性能就会很差。很自然的就想到在本地的 SSD 上再搞一份 cache,提升 IO 的期望时延。这个 cache 又叫 Secondary Cache。
Secondary Cache 在基于 RocksDB on Tectonic 的 ZiipyDB 案例中,将 read IOPS 提升了 50-60%,read latency 提升了 30-40%,效果显著。
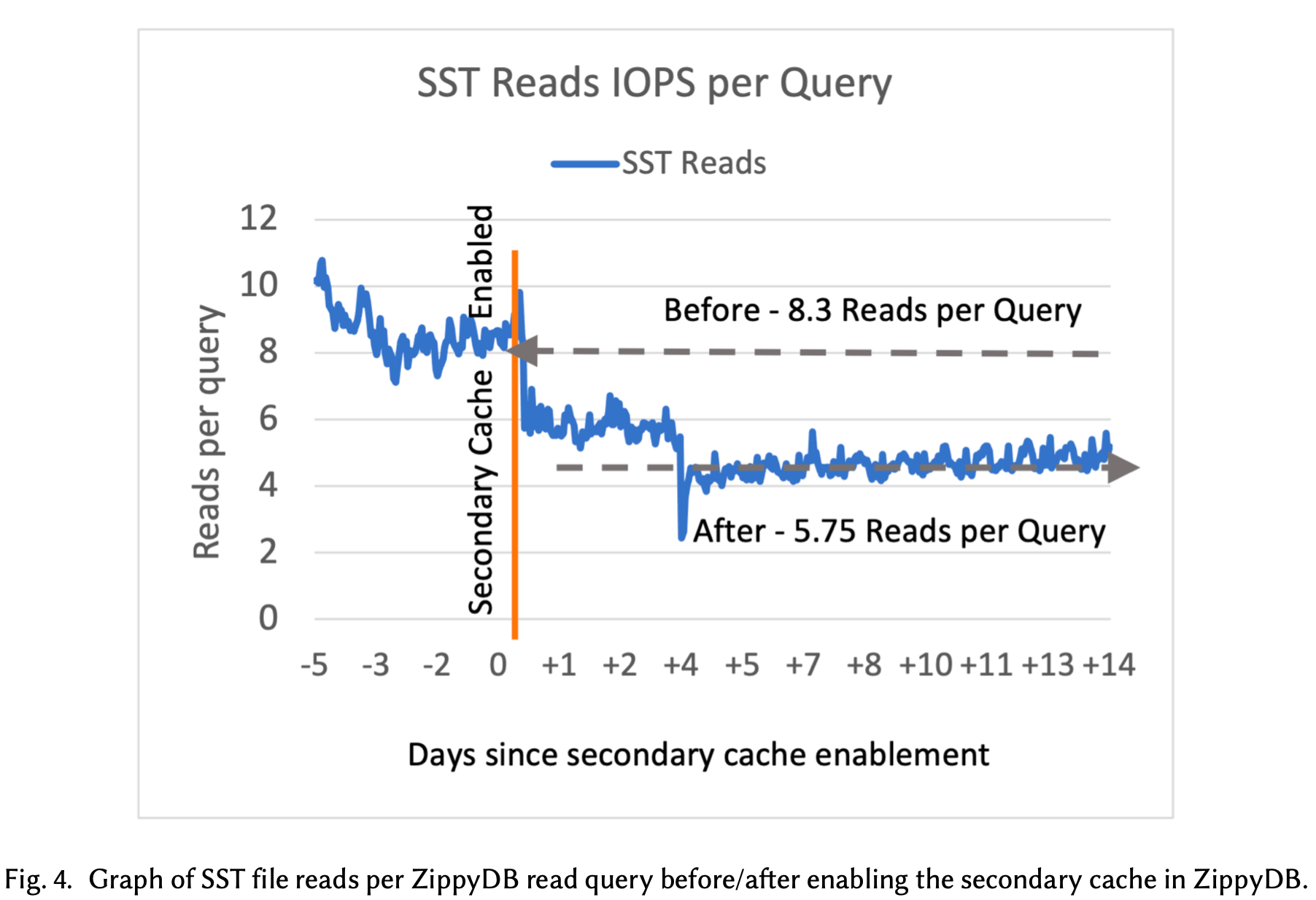
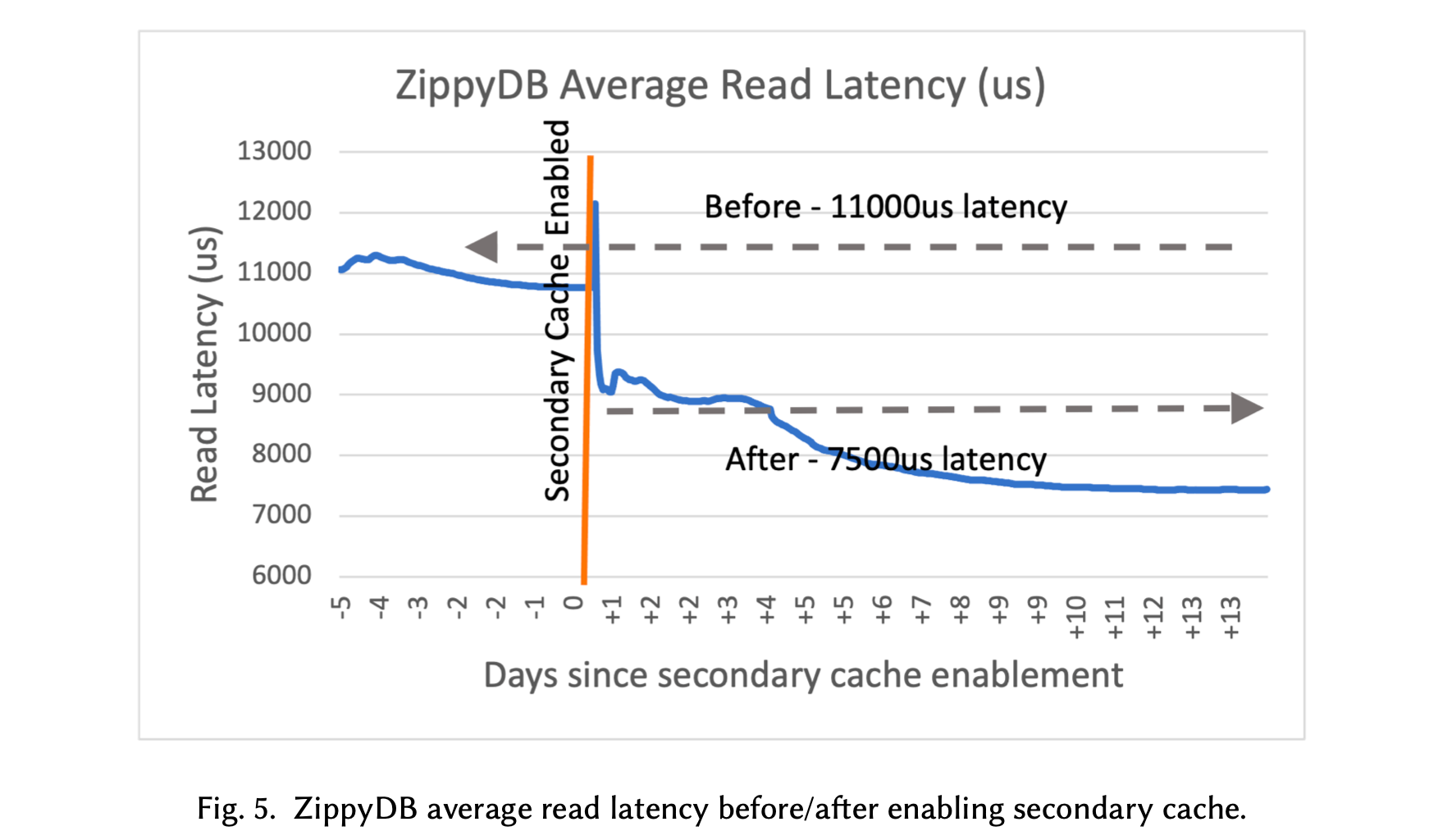
第四是 IO 相关的优化工作。 这里有一些老生常谈的优化,例如提升 compaction 的 read IO size 调大(4MB or 8MB),write buffer size 调大(64MB 或更大),还有像 adaptive readahead(readahead 大小从一个初始大小开始,每次 double 直到最大值,谨小慎微,防止浪费珍贵的网络带宽),parllel IO 等工作,这些工作没什么特殊之处,就不过多介绍了。
低开销的数据冗余
Tectonic 的数据冗余逻辑,包括多副本机制下的复制,纠删码机制下的编码,以及异常情况下的数据 reconstrunction,这些都是在 Tectonic 的客户端,也就是计算节点做的,相对于 RocksDB on SSD 来说会增加很多计算节点的网络带宽消耗,所以需要尽可能的减少一下这些开销。
SST file 的需求是高度持久化,以及尽量少消耗存储和带宽,所以使用 8+4 纠删码来实现数据冗余,即 8 个 data trunk 配 4 个纠错 trunk。纠删码导致多使用了 50% 的存储和带宽。此外,根据不同持久化 SLA 的要求,部署需要 6 或者 12 个存储节点。
WAL file 的需求是低尾延时和小 append(sub-block) 的持久化,所以使用 5 副本来实现数据冗余。因为一是多副本机制尾延时相对低,二是纠删码是 block-level 的,WAL 日志比较小也不能 padding 到 block 大小。
由于存在一些高频写 WAL 日志的场景,5 副本机制带来的 5x 带宽消耗太大了受不了,后来又在 Tectonic 侧支持了 stripe(sub-block) 级别的纠删码机制,一个 stripe 可以到 8KB 大小。stripe 相对 block (MB 级别)来说小了很对,对随机读性能不友好(比如随机读 128K 数据需要到更多存储节点做 IO),但 WAL 日志场景都是顺序读,瓶颈在带宽不在 IOPS 上面,所以不会有这个问题。
Multi-writer 下数据完整性问题
这里是用 fencing token 方案解决的。这其实是一个很常见的方案,分布式系统的准教科书 DDIA 上面有提到过,感兴趣的可以看一下,我这里就不多说了。
远程 IO 适配
这块其实没什么太多的东西。主要说了 RocksDB 原来假设 IO 不容易出错,错误处理的比较暴力,动不动 IO 出错了数据库就切成 read-only mode 了。现在远程 IO 环境下,出错是常态,需要小心谨慎的处理,能重试的就尽量重试。
还有就是一些 IO instrument 之类的工具。
RocksDB on Tectonic 的工作大致介绍完了,接下来我们看一看最终的效果。
 上图是写入的测试结果,Sequential Write 即数据有序写入,不需要 compact。Tectonic 和 Local SSD 的 throughput 是差不多的。对于 Random Write,Tectonic 大约慢了 25%。原文给的解释是:
上图是写入的测试结果,Sequential Write 即数据有序写入,不需要 compact。Tectonic 和 Local SSD 的 throughput 是差不多的。对于 Random Write,Tectonic 大约慢了 25%。原文给的解释是:Although Tectonic can provide enough throughput for sequential read and write when operating multiple files, single files’ processing speed is limited and it causes some bottlenecks. Tuning RocksDB compaction knobs would be able to address these bottlenecks, but we leave the default setting for a better comparison.
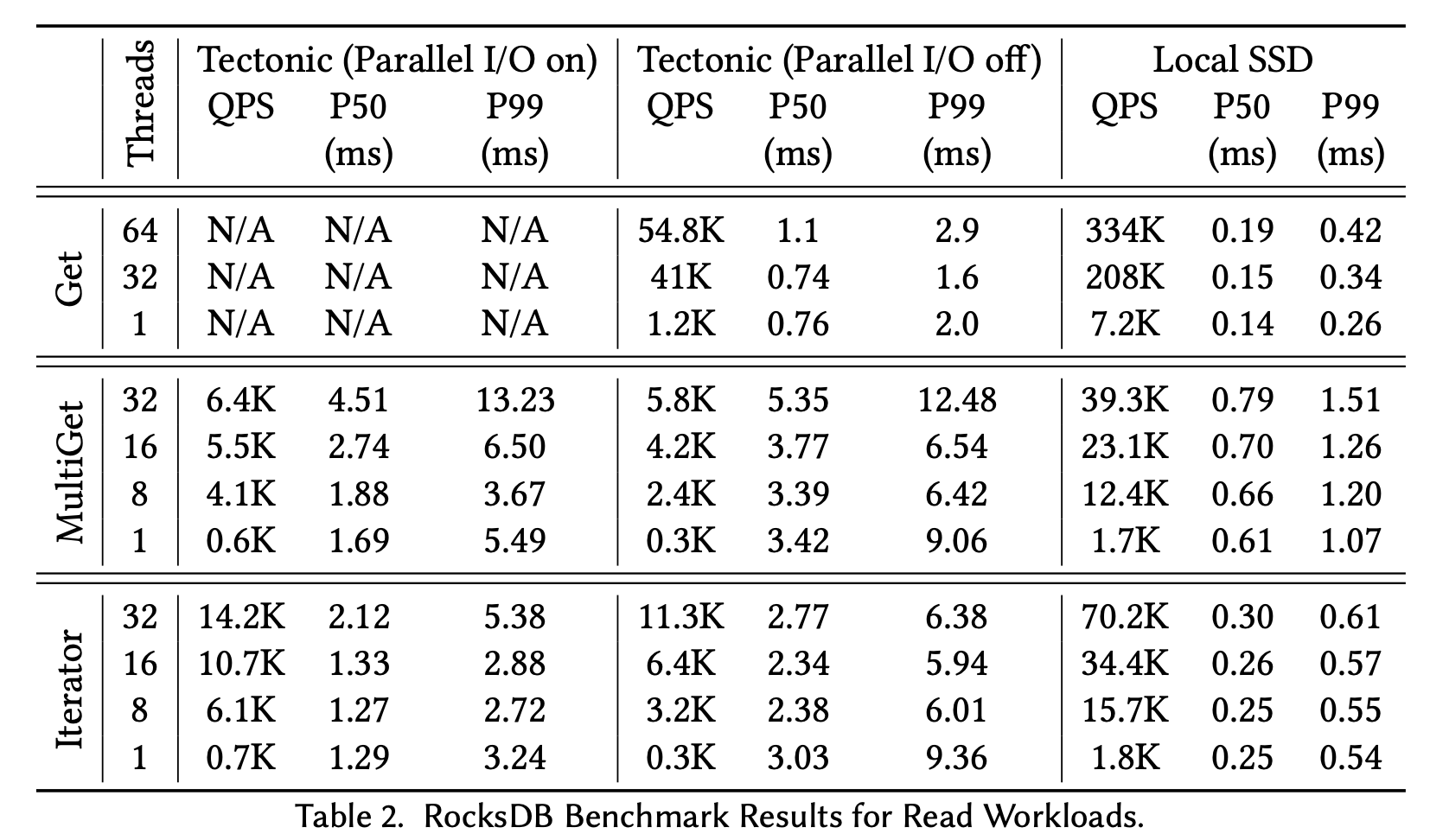 上图是读取的测试结果。RocksDB on Tectonic 测试了 parallel I/O off 和 on 两种模式。结果显示,Parallel I/O off 模式下,Tectoonic 的不同操作吞吐量大约是 Local SSD 的 5x,Parallel I/O on 模式下,能够优化到 3x。呃,有得必有失,性能会下降一点。
上图是读取的测试结果。RocksDB on Tectonic 测试了 parallel I/O off 和 on 两种模式。结果显示,Parallel I/O off 模式下,Tectoonic 的不同操作吞吐量大约是 Local SSD 的 5x,Parallel I/O on 模式下,能够优化到 3x。呃,有得必有失,性能会下降一点。
文章的最后还介绍了一个案例:基于 RocksDB on Tectonic 的 ZippyDB。这个案例很有参考价值,因为它涉及到一个非常有趣的问题:一个基于共识协议(e.g., Raft/Paxos) + RocksDB 实现的 share nothing 架构的数据库,如果存储放到了 DFS 上面,它的 Raft 日志放到哪里?显然,放到 DFS 上是不可能了,每次 Raft 日志持久化要刷到 DFS 上,时延太高,写入性能太差,如果是一个基于 RocksDB 的 OLTP 数据库(e.g., TiDB),这样的性能绝对是没法忍受的。这篇文章给的 ZippyDB 的方案是:仍然保持本地三副本的模式,只不过这三个副本是位于三个计算节点操作系统内核的 shared memory 中的,不做持久化。每次写入,需要把 raft 日志刷到三个计算节点的 shared memory 中,然后返回客户端成功。后台异步的把 shared memory 中的 raft 日志刷到 Tectonic 上。这里有一个假设,即认为多个计算节点的内核同时崩溃是非常罕见的,因此愿意承担一定数据的持久化风险,来换取写入性能。其实我曾经也想到过这个做法,还没有实践过,没想到已经有人在用了。
这篇文章的最后还提到了一些待做的工作:
- Secondary instance。当前互为副本的计算节点,只有一个节点负责读写,其他人都干看着,有必要让其他人也能支持读,把资源用起来。
- Remote Compaction。即把 compaction offload 到专用计算集群。
- Tired Storage。Tectonic 支持使用不同的存储介质来分别存储冷热数据。因此有必要识别出冷热的 SST files,并放到 Tectonic 不同的存储介质上,以实现成本的进一步降低。
好了,本文就到这里了。最后我回答一下本文开头的问题,我的答案是,这个系统好像是有那么一点东西?但 。。。
留下评论