
B-tree 压缩技术介绍(Oracle,MySQL,PG…
本文来聊一下数据库中的 B-tree 压缩技术,探讨以下几个问题:
- 为什么 B-tree 需要压缩?
- 工业界都是怎么干的?包括 Postgres,Oracle,SQL Server,DB2,MySQL 等老油条数据库。
注:本文讨论的 B-tree 圈定在 disk-based 关系数据库中的 B-tree。需要注意该场景下 B-tree 通常会被用来做索引,它的 key 是 structured,即可能是一张表的多个不同类型的列组合而成的 multi-columns key,而不是简单的一个字符串 key。
首先来聊一下为什么 B-tree 需要压缩。
第一个原因是压缩能够降低存储空间,帮客户节省成本,客户省了钱我们就(站着)赚了钱,这个好处显而易见。
第二个原因是压缩能够提升性能。
关于这个第二点怎么理解呢?
我们知道,disk-based B-tree 逻辑上的每一个结点在物理上都对应一个磁盘上的一个 page。这些 page 在磁盘上通常是不连续的,即便逻辑上相连的叶子结点在物理磁盘上也是不连续的,因为任何相连的一前一后两个结点都可能由于后续数据的插入引发前一个结点 split,磁盘上新位置分配出来的 page 会插入到这两个结点中间,导致这三个结点在磁盘上不能连续。因此,我们可以认为,对任意一个 B-tree 结点的读取/写入,都是一次磁盘的随机 IO(我们考虑最差情况,没有 buffer pool 缓存)。又由于 B-tree 的所有读写操作需要从根结点先经过内部结点下降到叶子结点,尤其是最笨重的 range scan 操作可能还要在叶子结点层顺序或逆序扫描多个叶子结点,这些操作都会读好几个结点带来好几次的磁盘随机 IO,巨慢的磁盘在这里就会成为瓶颈。
我们已知磁盘自身有两个性能指标:IOPS 和带宽。硬件上这两个指标都是有天花板的。在 B-tree 场景中,由于存在大量的小随机 IO(每次 IO 一个 16K 的 page),IOPS 相比带宽更容易达到瓶颈。所以我们优化的首要目标就是让 B-tree 的读写操作花费尽可能少的 IO 次数,这样在 IOPS 天花板焊死的前提下,我们就能获得更高的并发度,性能(吞吐量)得到提升。其次,如果仍有精力没事干的话,可以再考虑优化下每次 IO 的带宽消耗,对性能(吞吐量)会有一点小小的帮助,换句话说,帮助不大。
这里引出用 B-tree 压缩来提升性能的两种做法。
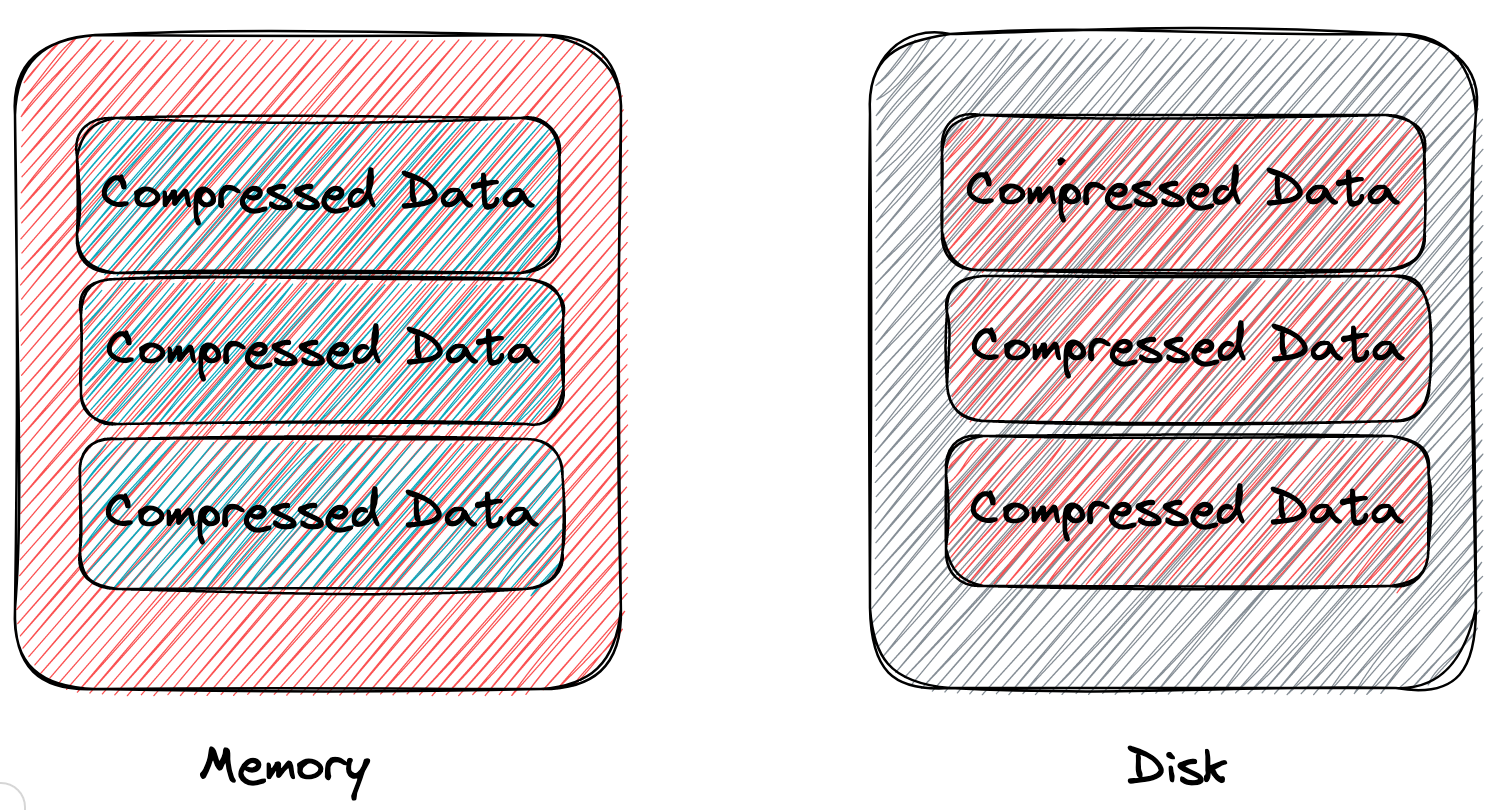
一种是面向 IOPS 优化。具体的做法是,数据直接以轻量压缩(e.g., prefix compression)后的形态存储在内存 page,内存 page 和它对应的磁盘 page 大小相等,存储的东西完全一样。 由于内存和磁盘 page 中存储的都是压缩后的数据,单个 page 能存的数据量相对不压缩来说就更多了,B-tree 的扇出(fan-out)增加了。在数据总量不变的情况下,B-tree 垂直方向上高度减小,水平方向上宽度减小,总的结点数变少了。由于树高减小了,B-tree 的所有操作在下降过程中需要访问的结点数变少了,range scan 操作由于单个叶子结点能存更多的数据了,在需要扫描的数据总条数不变的情况下,扫描叶子结点数变少了。要读的结点数少了,磁盘 IO 次数就少了,整体吞吐量得到提升。
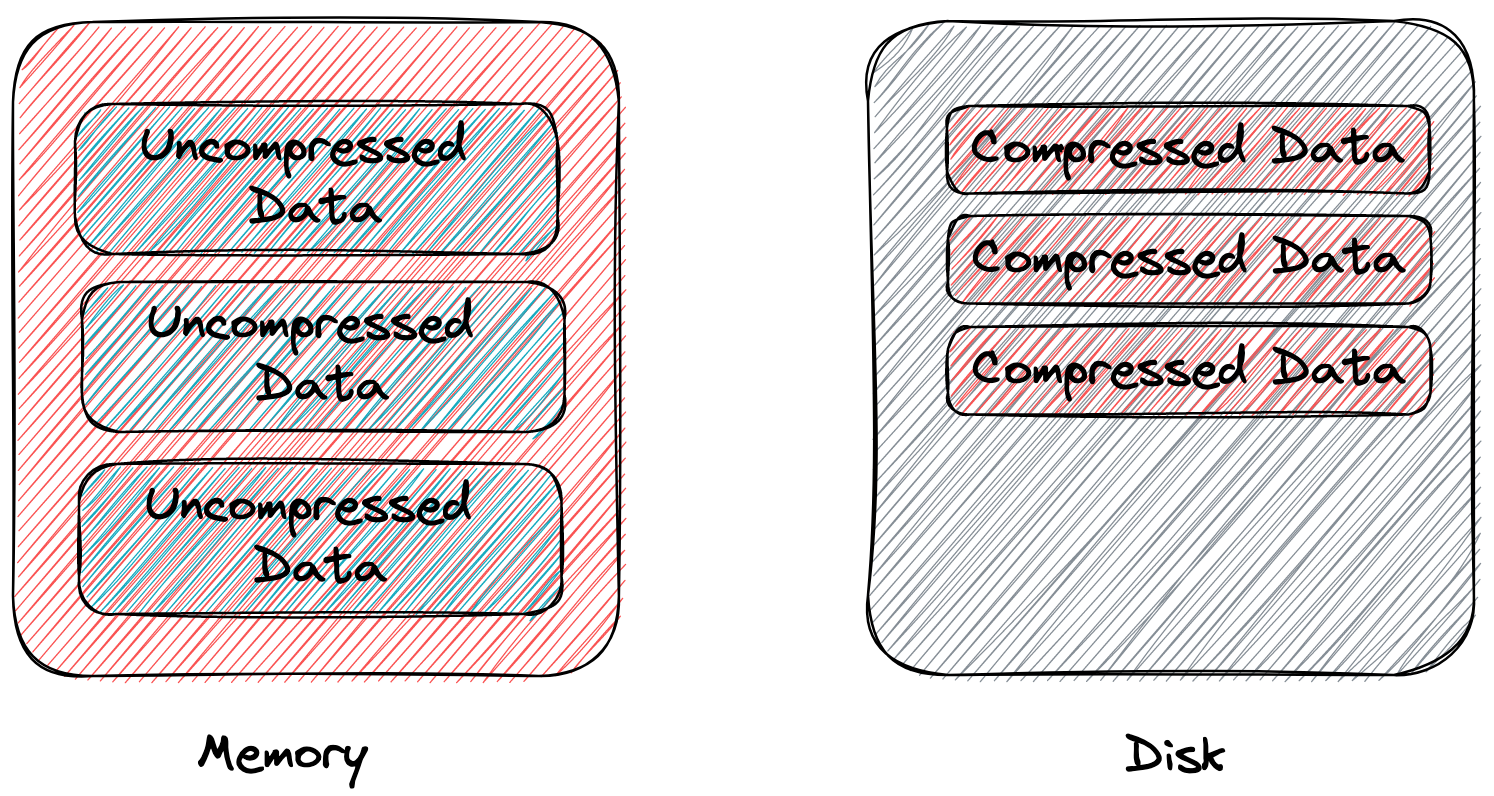
另一种是面向带宽(bandwidth)优化。具体的做法是,数据以未压缩的形态存储在内存 page 中,内存 page 刷盘时压缩,以通用压缩(e.g., zlib, lz4)后的形态存储在磁盘 page 中,磁盘 page 比它对应的内存 page 更小。这种做法下,读写结点的磁盘 page 产生的 IO 大小变小了,消耗的带宽更少了,然而由于这种做法没有增加单个内存 page 能存的数据量,B-tree 结点的扇出没有增加,所有 B-tree 操作需要的 IO 次数没变,对优化 IOPS 没有帮助,所以这种做法对性能的优化很小,主要作用还是在节省存储空间上。
以上就是 B-tree 压缩能够提升性能的原因。(尽管压缩会消耗一点 CPU,但由于磁盘 IO 是瓶颈,而 CPU 有所盈余,这样换是值得的。)
接下来我们以工业界的数据库为例,挨个看一下它们都是怎么干的 B-tree 压缩。
大部分「正常」的数据库都是面向 IOPS 优化的,我们先来看看这些正常的数据库。
先来看一下 Postgres。
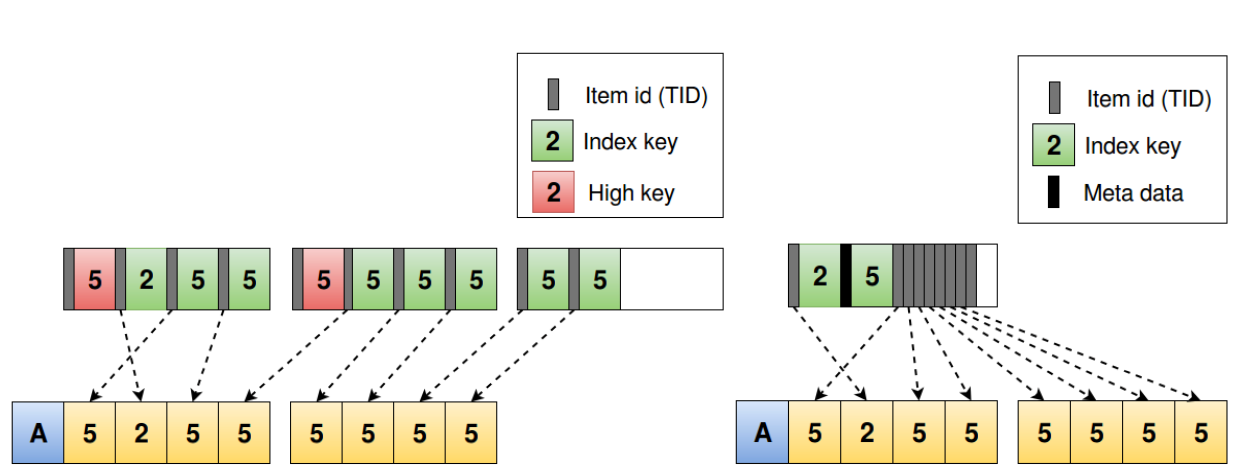
Postgres 可能是由于缺钱没人干活的原因,只支持了简单的 deduplication 压缩。顾名思义,deduplication 就是针对重复的 key 进行的压缩。在非 unique index 中,可能存在很多重复的 key(其实 unique index 中也可能存在少量重复的因为 MVCC)。对于 page 内重复的 key,我们倾向于只存一份以节省空间。举例,未压缩的形态是 {key:TID1,key:TID2,key,TID2…},压缩后的形态是 key + TID list,即 {key:TID1,TID2,TID2…}。(这里的 TID 即 tuple id,指向表的一行记录。下文的 ROW ID,RID 和这个玩意是同一个东西。)
对于 multi-columns key,除非两个 key 的所有 column 的值都相等,否则不会被判定为是重复 key。如 (“aaa”, “bbb”),(“aaa”,”ccc”),虽然两个 key 的第一列相等(都是 aaa),但由于第二列不相等(一个 bbb,一个 ccc),无法被判定为重复,不能用上 deduplication 压缩。
什么时候做压缩呢?Postgres 使用了 lazy 的方案,会在 page 写满要发生 split 的时候,先对 page 内的数据做一下处理(有无效的数据先回收删一下),然后再应用一下 deduplication 压缩。
点评一下 Postgres 的压缩方案,这个方案的压缩能力比较基础,只能针对完全重复的 key 进行压缩,压缩率不高(相比后面提到的几家)。就性能而言,这个方案对读操作没有影响,核心逻辑二分查找还和原来一样,对写操作的影响非常小,几乎可以忽略。
接着看一下商业数据库的开创者 Oracle,传统商业数据库三傻之中的大傻(按市场份额排名)。
Oracle 支持的压缩算法就比较全面了。包括:
- Duplicate Key Removal。这就是 Postgres 中的 Deduplication。
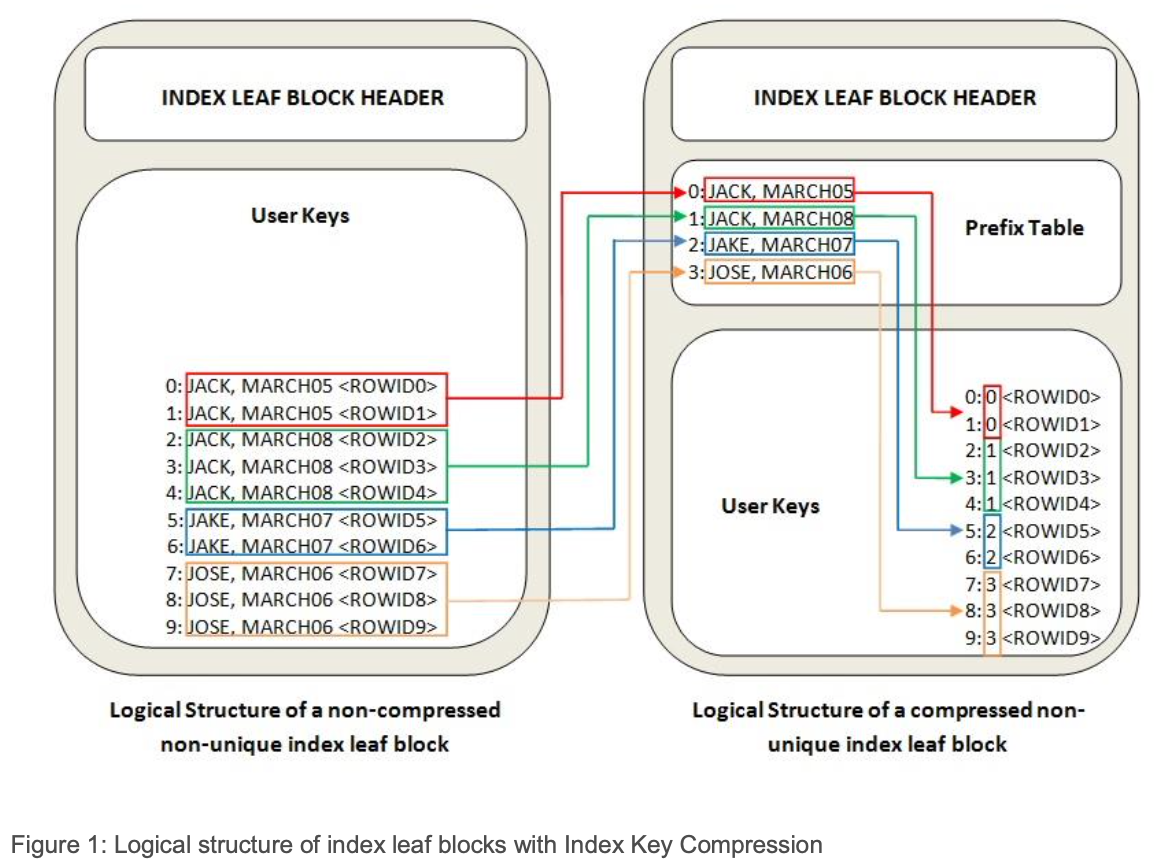
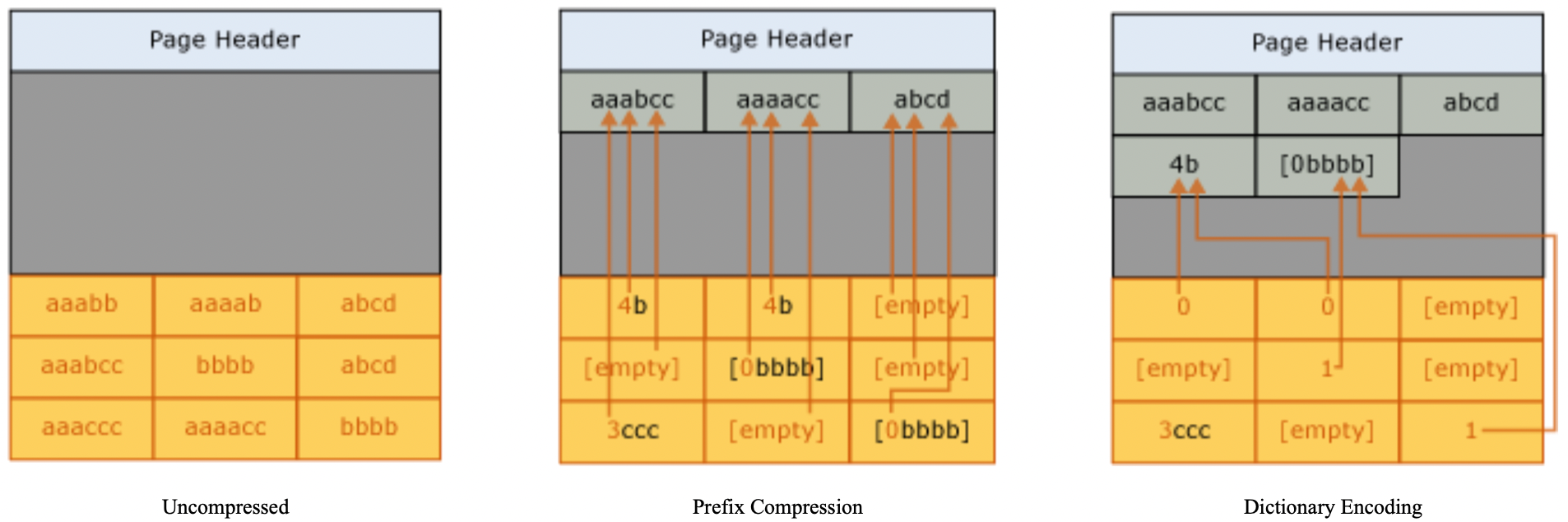
- Index Key Compression(Prefix compression)。这是基于 B-tree 的 key 是排序的,相邻的 key 往往高概率有公共前缀的特点。可以针对公共的前缀,把它抽取出来放到 page 中特定的 Prefix Table 区域,在 key 中存储一个 prefix table 的引用即可(如上图示例)。基础配置下(Advanced Index Compression LOW)是 column-wise 的,以 multi-columns key 中的 column 整体为单位来判定 prefix,系统来确定压缩几个 leading columns。e.g., (“aaa”, “bbb”, “cccccxx”),(”aaa”, “bbb”, “cccccyy”),系统认为对第一列 + 第二列应用前缀压缩是合适的,压缩后的数据就成了 (ref1, ref2, “cccccxx”),(ref1, ref2, “cccccxx”) 。高级配置下(Advanced Index Compression HIGH)支持 intra-column prefix compression,这是 byte-wise 的,以 byte 为单位来判定 prefix,系统来确定哪几个 leading columns 整体作为前缀 + 紧接着的一个 column 的前几个字节作为前缀来压缩。e.g., (“aaa”, “bbb”, “cccccxx”),(“aaa”, “bbb”, “cccccyy”),系统认为第一列 + 第二列 + 第三列的前 5 个字符可以作为前缀进行压缩,压缩后的数据就成了 (ref1, ref2, ref3”xx”), (ref1, ref2, ref3”yy”)。
- Length Byte Compression。变长的字符串类型编码方式是长度 + 字符串内容。如果发现一个 page 内的字符串都很短,长度用 1 byte 就存得下,就只用 1 byte 存。如果发现实际它们的长度都一样,只在 page 内全局存一个固定的长度就可以了。
- ROWID List Compression。文档原文说的是:「ROWID List Compression is an independent transformation that takes the set of ROWIDs for each unique index key and represents them in a compressed form, ensuring that the compressed ROWID representation is logically maintained in the ROWID order to allow for efficient ROWID based lookup.」。
- Row Directory Compression。我们知道 B-tree page 的布局用的都是 slotted-array(indirection vector) 结构。一个个 KV 在 page 内从尾部往前存放,它们的间接指针 「offset」(两个字节)在 page 内从头部往后存放。Oracle 把一个 page 按 256 bytes 切分成很多个 region,把一个 KV 的 offset 表示为 base(region 起始地址) + region 内的 offset。由于同一个 region 内的所有 KV 共享一个 base,只需为这些 KV 存一个共享的 1 byte 的 base,再为它们每个 KV 单独存 1 byte 的 offset 就可以了。
- Flag and Lock Byte Compression。文档原文说的是:「Generally speaking, the index rows are not locked and the flags are similar for all the rows in the index block. These lock and flag bytes on disk can be represented more efficiently provided it is possible to access and modify them. Any modification to the flag or lock bytes requires these to be uncompressed.」
那么 Oracle 什么时候做压缩呢?Oracle 也是 lazy 的方式,增量数据写入 page 时先不压缩,在 page 内的数据量达到阈值时触发压缩。换句话说,一个 page 内的数据在某一时刻会有一部分数据是压缩的数据,一部分是未压缩的数据。相比 Postgres,Oracle 的压缩算法开销更大,lazy 压缩的必要性更大。通过 lazy 压缩,我们就可以均摊一下压缩的开销,否则每次 insert 都跑一边压缩算法性能的开销是没法接受的。
点评一下 Oracle 的压缩方案:压缩率高。读操作仍然可以用二分查找,但需要先 lookup 找到 prefix,有一次 memory lookup 的开销。写操作也需要负担均摊的压缩开销。不过这些开销并不大,用来换取压缩率无疑是值得的。
接着看一下传统商业数据库三傻之中的二傻 SQL Server。
SQL 支持三种压缩算法:
- Row compression。包括 a. 对 key 中 column 的 length 和 offset 进行压缩。(没看到具体说怎么干的) b. 对数值类型(e.g., int, numeric)进行 varint 编码(不了解 varint 的同学可以自行 google 一下,限于篇幅这里不详细介绍)。
- Prefix Compression。类似于 Oracle 的 Intra-column prefix compression。
- Dictionary Encoding。文档原文说的是「Dictionary compression searches for repeated values anywhere on the page, and stores them in the CI area. Unlike prefix compression, dictionary compression is not restricted to one column. Dictionary compression can replace repeated values that occur anywhere on a page.」。这段话有点绕,我的理解是这个「repeated values」中的 「value」指的是一个 multi-columns key 的任意一个列的值,换句话说是 column-wise 的而不是 byte-wise 的,以单个列的值整体为单位来做字典编码。(?疑似不同列的值只要相等,也可以被判定为 「repeated」)。这个算法没有像前缀压缩一样受局部空间限制(相邻的公共前缀才能压缩),而是一个 page 内任意地方的的重复的值都可以压缩,进一步提高了压缩率。
SQL Server 什么时候做压缩呢?Page 写满要 split 的时候压缩(和 Oracle 数据量到达阈值压缩差不多)。
点评一下 SQL Server:压缩率高。读操作仍然可以用二分查找,但会比 Oracle 多一次 memory lookup 的开销,因为先要 lookup 一下 dictionary 做一次 dictionary compression 的 decode。写操作虽然需要均摊额外的一层 dictionary compression,和 Oracle 也差不太多。
最后看一下传统商业数据库三傻之中的三傻 DB2。
DB2 支持的压缩算法有:
- RID List Compression。相当于 Postgres 的 Deduplication。
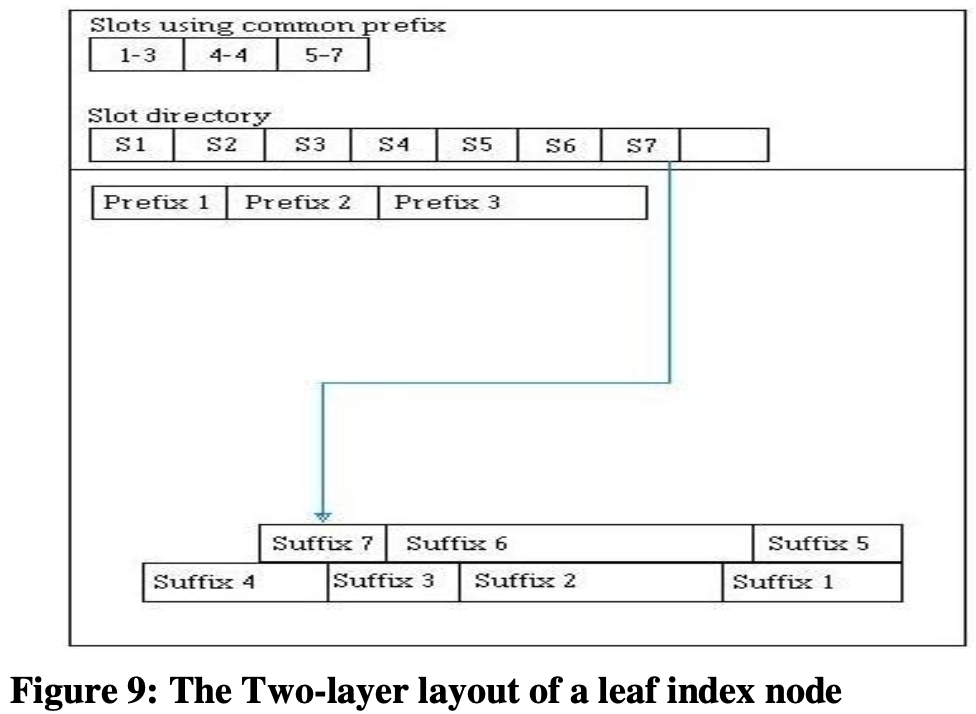
- Prefix Compression。原理和 Oracle 以及 SQL Server 是一样的,只是 page 内布局稍有不同,单独出来了一个「slots using common prefix」结构,存储着一个个区间,每个区间对应一个公共 prefix。
点评一下 DB2:压缩率较高。读操作可以按 Slots using common prefix + prefix 进行二分查找,和 Oracle 差不太多,比 DB2 少一次 dictionary 的 memory lookup。写操作与 Oracle,SQL Server 开销差不太多。
到此为止,我们已经看完了几个面向 IOPS 优化的「正常」数据库,最后再来看看面向带宽优化的「聪明」数据库 MySQL。
MySQL 的 InnoDB 实现了两种 B-tree 压缩方案。
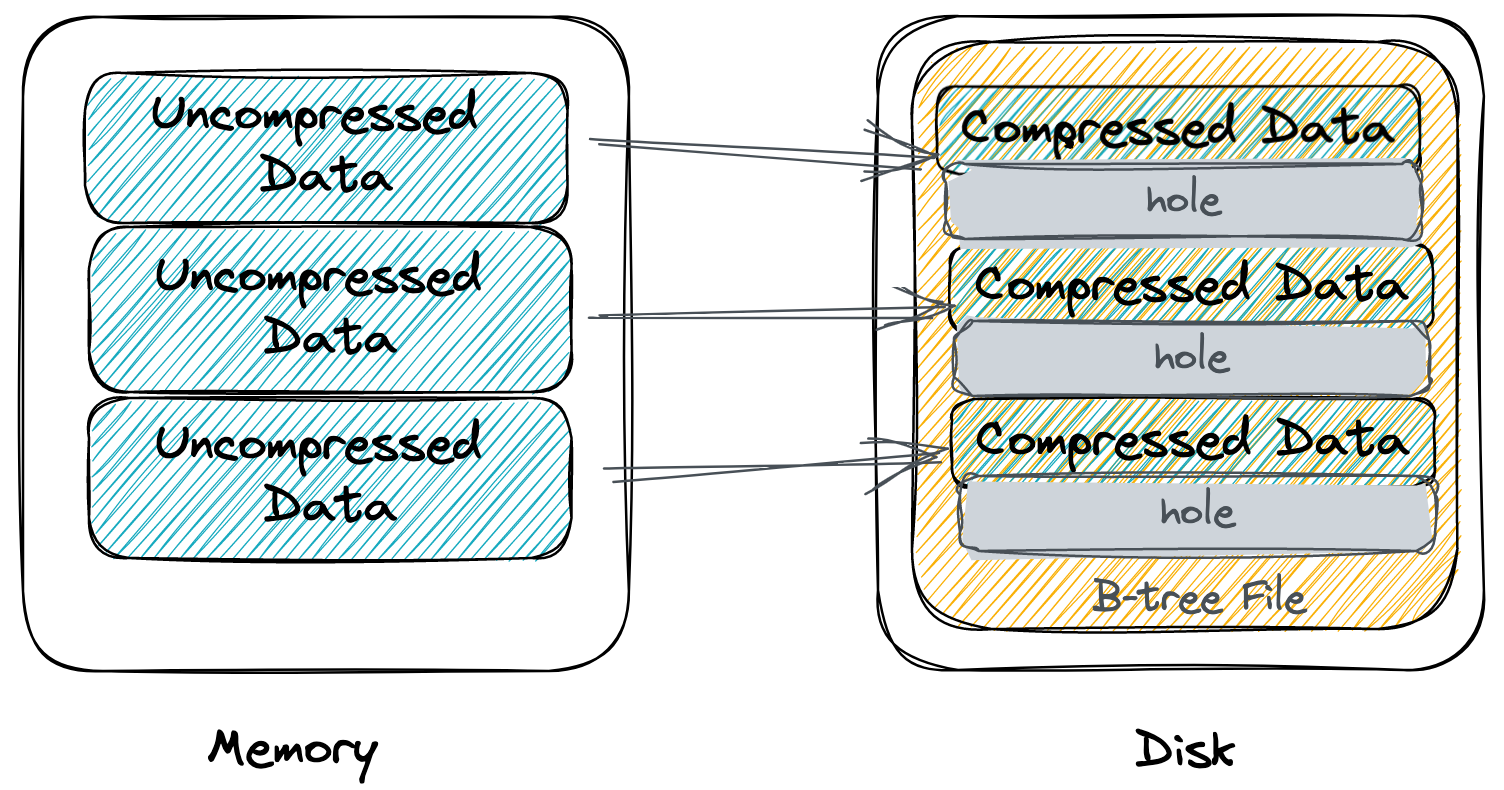
我们先来看一下 Page Compression 方案。该方案利用内核的 punching hole 技术,直接在文件中打洞(在文件中间打洞,即删除文件中间的某一段空间,不影响文件后面 page 的偏移)。数据以未压缩的形态写入到内存 page,直到刷盘时才用通用的压缩算法(e.g., zlib, lz4)压缩一下刷到对应的磁盘文件 page,这一步刷的是压缩后的数据所以可以减小带宽消耗。逻辑上内存 page 和对应的磁盘文件 page 的大小是一样的,但由于磁盘文件 page 存储的是压缩后的数据,这个 page 内有一部分尾部空间没有用上,就可以调用 punching hole 相关的系统调用在物理上删除掉这段没有用到的空间。这样操作下来,物理上磁盘 page 的真实大小变小了,节省了存储空间。不过由于这个方案内存中的 page 存储的是未压缩的数据,所以 B-tree 的扇出没有增加,结点数没有减少,所以对 IOPS 没有优化。
点评一下这个方案,这个方案实现起来比较简单,不用自己实现压缩算法,直接用现成的通用压缩算法 + punching hole 技术就实现了压缩功能。压缩率一般。由于 puching hole 打洞的基本单位是 4K,对于 16K 的 page,极限也就压缩到 4K(打洞 12K),压缩率上界为 4 倍。此外,这个方案性能也有一些问题,punching hole 技术会导致文件碎片化,内核维护开销大,性能很差,例如这里提到的拷贝文件巨慢的问题 。尽管该方案优化了带宽,但这点优化相比 puching hole 的性能劣化算是小巫见大巫了。基于此,我个人不推荐这个方案。
 )
)
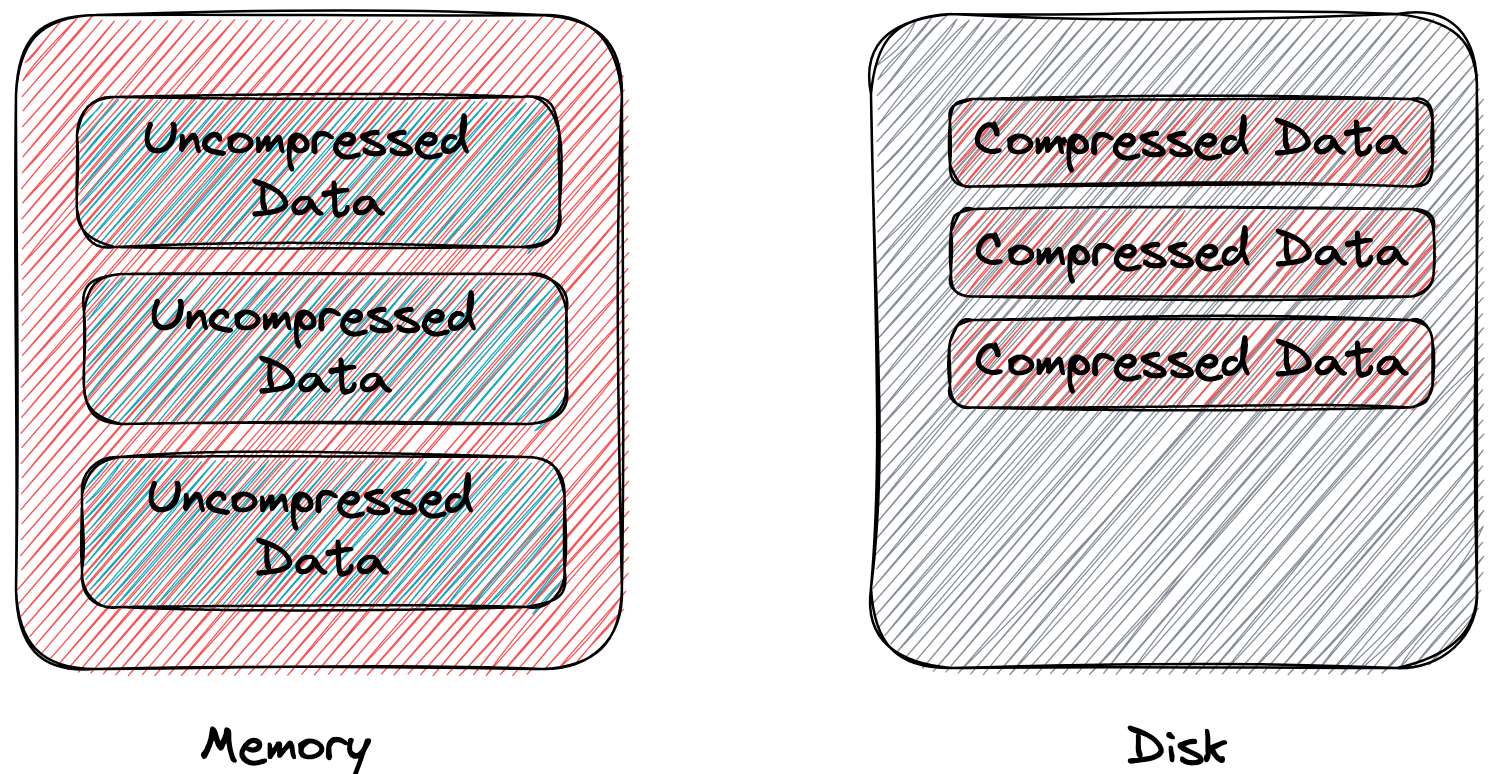
接着我们再看一下 MySQL 的 Table Compression 方案。该方案直接写死一个磁盘上的 page 大小(前提保证磁盘 page 大小 < 内存 page 大小),内存 page 在刷盘的时候用通用的压缩算法(e.g., zlib, lz4)压缩一下,如果压缩后的大小能放入磁盘上的 page,就正常刷下去(这一步优化了带宽消耗)。否则,内存 page 先 split 再次压缩后才能刷下去。
这个方案与 Page Compression 方案一样,内存中的 page 存储的是未压缩的数据,没有增加 B-tree 结点的扇出,所以同样对 IOPS 没有优化。
看起来 Table Compression 方案就是简单的面向带宽做的优化,对性能帮助不大,只能省一点存储空间。这 MySQL 也太拉胯了吧,性能堪忧?
当然不会这么拉胯,毕竟也是搞了这么多年的老牌关系数据库了。
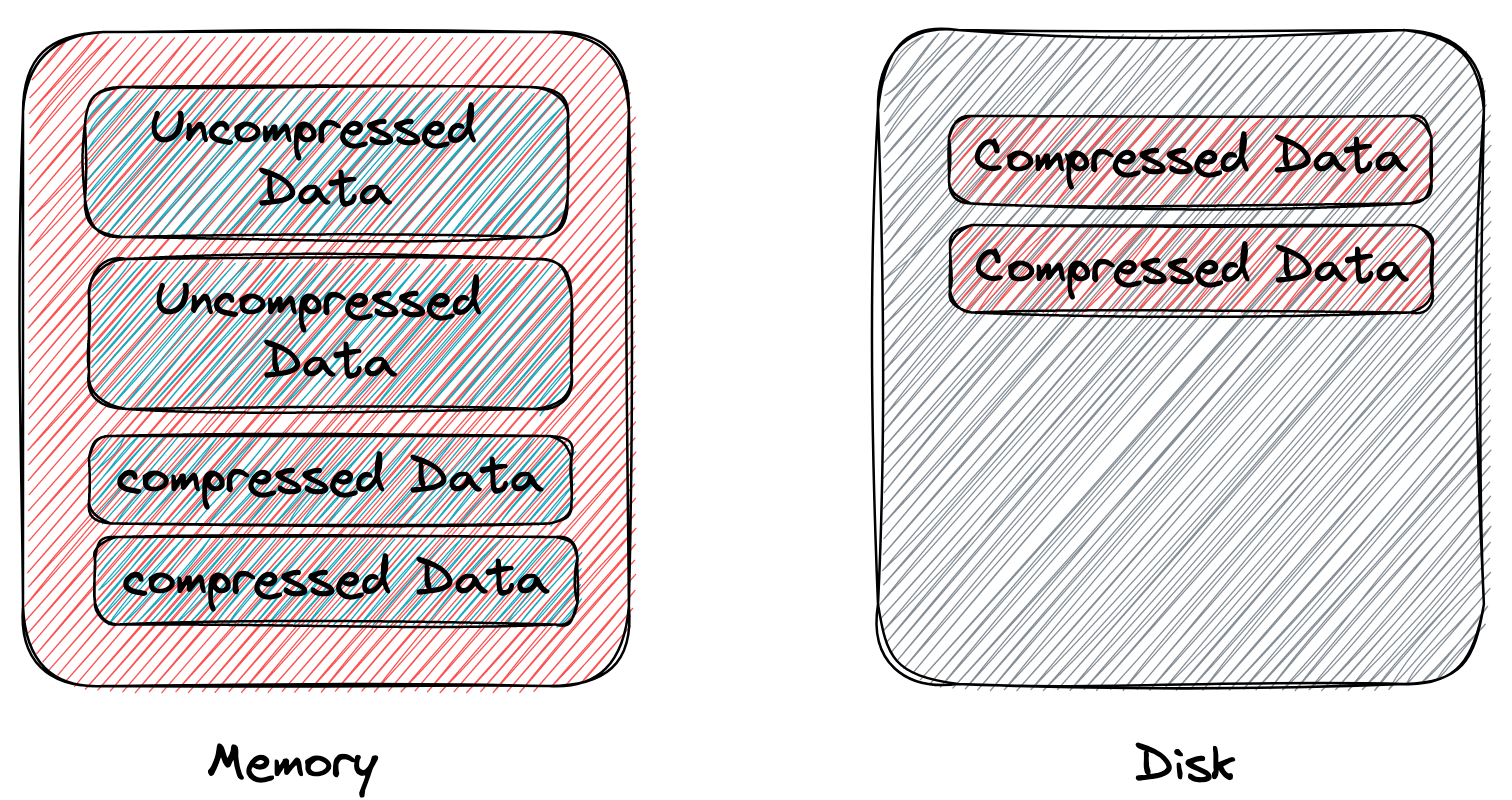
Table Compression 方案通过另外的「旁门左道」实现了面向 IOPS 优化:在 buffer pool 内存中已缓存未压缩的 page 的基础上,再缓存一下压缩后的 page,也就是所谓的「双缓存」。此外,还会把压缩后的 page 作为一等公民,buffer pool 在内存不足只会先去剔除未压缩的 page。由于留下来的压缩后的 page 消耗的内存更小,buffer pool 能缓存 page 数量更多,缓存命中率就提升上去了,读写结点带来的 IO 次数就减少了,算是绕了一点路实现了面向 IOPS 优化,提升了性能。
点评一下 Table Compression 方案,该方案对比 MySQL 的 Page Compression 方案,虽然二者都是面向带宽优化,但 Table Compression 方案看起来更「聪明」一点,通过 buffer pool 中也缓存压缩后的 page,实现了面向 IOPS 优化。对比 Oracle 等其他几家同样面向 IOPS 优化的内存 page 直接压缩的方案,MySQL 双缓存做法的优点是有一份未压缩的 page 缓存,热点数据读取无需解压性能会稍好一点点,缺点是内存消耗会更多一点。
以上就是对 disk-based 关系数据库中 B-tree 压缩的「简短」介绍。
欢迎大家点赞关注我的知乎账号/微信公众号:黄金架构师。
留下评论