
一文讲懂 ARIES Recovery 算法
本文的主要内容是介绍 ARIES 这一经典的 Recovery 算法。写作目的有两个,其一是尽我所能来帮助各位亲爱的读者快速地理解这个算法,其二是笔者想借助写这篇文章来加深一下对 ARIES 论文的理解。
背景知识
Recovery
是什么
Recovery 算法主要由两个部分组成:
- 数据库正常运行时保证数据库挂掉后能恢复的一系列行为。(Rumtime 部分)
- 包括 WAL,Checkpoint 等,下文会详细介绍。
- 数据库挂掉后把数据库恢复到挂掉之前的一致性状态的一系列行为。(Recovery 部分)
- 包括把已提交的事务的更新 Redo 出来,把需要回滚的事务的更新 Undo 掉,下文会详细介绍。
为什么需要
因为我们需要保证事务的原子性和持久性,也就是 ACID 中的「A」和「D」。
Concurrency Control
现代数据库广泛采用 MV2PL 协议来实现 Concurrency Control。然而在 ARIES 那个年代,MVCC 还没有被广泛使用,所以 ARIES 是基于 2PL 协议来设计的。(当然,变种的 ARIES 支持 MVCC 不在话下,Oracle,MySQL 等诸多数据库为我们提供了范例。)
Lock 的运用是 2PL 协议的重点。除此以外,数据库中还有一个 Latch 的概念。这两个概念很容易让人混淆。考虑到读者阅读本文的体验,笔者决定在这里重申一下它们的区别。详情见下表:
| Lock | Latch | |
|---|---|---|
| 锁定对象 | 数据库的逻辑对象。例如 Database,Table,Tuple | 内存中的数据结构。例如 Buffer Pool,Page Table,Table Page,Index Page |
| 持有时间 | 一般是 Transaction-Level,遵循 2PL 协议。事务执行期间加 Lock,事务提交后放 Lock。持有时间长,尤其是长事务的场景 | Instant-Level。每次读写数据结构前加 Latch,读写完成后放 Latch,持有时间短 |
| 实现 | 依赖于数据库的 Lock Manager。通常有死锁检测 | 简单来说就是 Mutex。由程序猿(🐒)人肉保证不会发生死锁。(如果发生了死锁,越南的程序猿可能需要 996 Debug 来解决死锁 :) ) |
ARIES 那个年代的一些数据库会在读写数据时对 Page(包括 Table Page 和 Index Page,本文不区分二者时直接统称 Page)加 Lock。显然,这种做法降低了并发度(对于 Table Page 而言,我们至少应该支持不同事务并发地更新同一 Page 内的不同 Tuple;同样,对于 Index Page 而言,我们也至少应该支持不同事务并发地更新同一 Page 内的不同 Index Entry,即便其中一次操作会引发 Page Split 或者 Merge (注意:本文默认 Index 采用 B-Tree 实现,B-Tree 的 Index Page 简称为 Index Page。) )。因此,现代数据库广泛采用 Early Lock Release 技术,对 Page 只加 Latch 而不是 Lock,寻求通过更细粒度的 Tuple-Level 的 Lock 来提高并发度。
Buffer Pool 策略
所有 Page 驻留内存时都会由 Buffer Pool 来统一管理,它们会被放在 Buffe Pool 的一个个 Frame 中。我们可以理解为一个 Page 有内存和磁盘两个副本,由于磁盘 IO 巨慢无比,很多更新操作出于性能考虑只会更新内存中的副本。如果对某个 Page 的更新已经反映到内存中的副本上,尚未反映到磁盘上的副本上,我们就说这个 Page 是 Dirty Page。由于内存是易失的,为了保证数据不丢失,Dirty Page 必须在某个时刻刷到磁盘上去。
那么问题来了,应该何时将这些 Dirty Page 刷盘?如果这些 Dirty Page 上有未提交事务的改动,能将它们刷盘吗?
回答这个问题需要引出 Buffer Pool 的不同策略:
-
STEAL:允许将未提交事务的改动刷盘。
-
NO-STEAL:与 STEAL 相反。
-
FORCE:必须在事务提交时把该事务的所有改动刷盘。
-
NO-FORCE:与 FORCE 相反。
Buffer Pool 可以在 STEAL 和 NO-STEAL 中二选一,然后在 FORCE 和 NO-FORCE 中二选一,组成自己的策略。
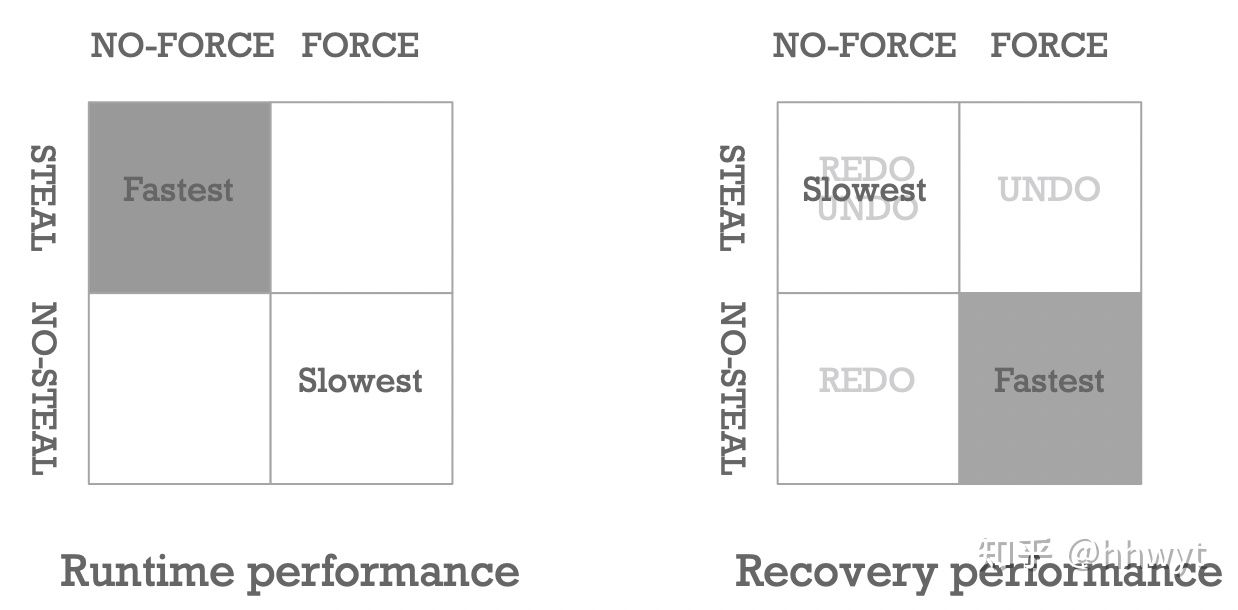
上图是笔者从 Runtime 性能和 Recovery 性能两个维度对 Buffer Pool 不同策略的分析。
首先是 Runtime 性能,结论是 STEAL/NO-FORCE 的策略最快,NO-STEAL/FORCE 的策略最慢。这是因为 STEAL 的策略能让我们很快地(因为刷某个 Dirty Page 不需要等待更新了它的所有事务提交)把 Dirty Page 刷盘,腾出 Buffer Pool 空间给其他 Page 用;NO-FORCE 的策略不要求事务提交时同步刷盘,而是由 Buffer Pool 来定期或者按需刷盘,这种做法大大减少了刷盘的次数(因为很可能会有很多事务改了同一个 Page,最终刷一次盘就给搞定了)。总的来说,STEAL/NO-FORCE 的策略,减小了单个事务的 Latency,提升了整个系统的 Throughput,是看中 Runtime 性能的系统的上上之选。
其次是 Recovery 性能,结论是 NO-STEAL/FORCE 的策略最快,STEAL/NO-FORCE 的策略最慢。这是因为 NO-STEAL 的策略保证了磁盘上的任何 Page 都不含未提交事务的改动,不需要考虑未提交事务的 Undo。FORCE 的策略保证了所有已提交事务的改动都已经反映到了磁盘上,不需要考虑已提交事务的 Redo。所以,NO-STEAL/FORCE 策略让我们在 Recovery 阶段不需要做任何事情,速度快得飞起,这个策略是看中 Recovery 性能的系统的上上之选。
因为大多数数据库都更看重 Runtime 性能,所以 STEAL/NO-FORCE 策略「大行其道」。
WAL 协议
全称是 Write-Ahead Logging。
WAL 协议要求更新任意 Page 都要记录 Log,并且
- 必须保证所有 Page 刷盘之前与它有关的所有 Log 已经刷盘。
- 必须保证事务提交前该事务的所有 Log 已经刷盘。
显然,WAL 协议完美兼容 STEAL/NO-FORCE 的策略。我们可以为一个更新操作记录一条 Redo Log 用来指示我们在 Recovery 期间如何 Redo 这个更新操作;记录一条 Undo Log 用来指示我们在(Rumtime 或者 Recovery 期间)事务回滚的时候如何 Undo 这个更新操作。(一般在 Log 数据量小的情况下,这两条 Log 会合并成一条。)
Log 格式
介绍
Log 格式按逻辑物理属性可以分为 Logical Log,Physical Log,以及二者混合的 Physiological Log。
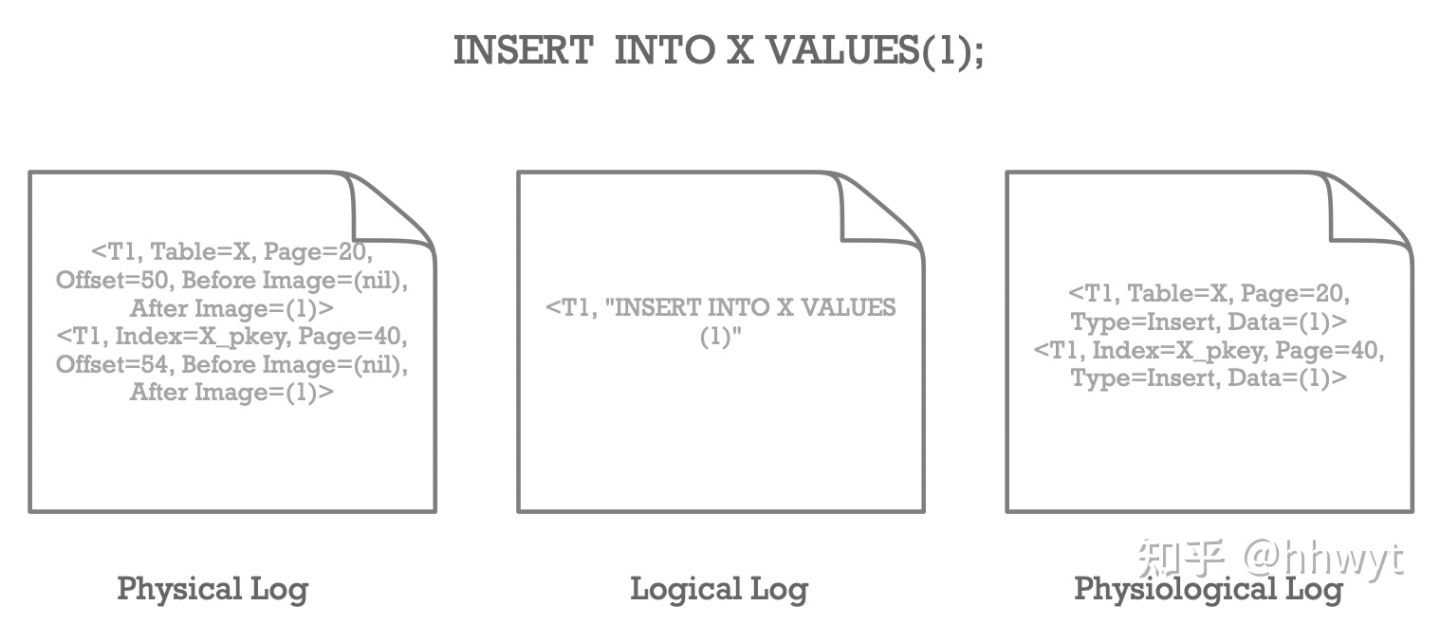
上图给出了「INSERT INTO X VALUES(1);」这条语句在三种 Log 中的实现细节。Physical Log 会记录具体的 Page 以及 Page 内目标对象的 Offset,还包括目标对象更新前后的镜像。如果一次更新操作涉及到更新 Index,也要为 Index Page 的更新记录 Log; Logical Log 不关心物理层面的 Page,上图给出的一种实现方式是记录 SQL 语句。一条 SQL 语句可能更新很多 Page,但 Log 只需一条;Physiological Log 会记录具体的 Page,但不会记录 Page 内目标对象的 Offset,它以任意一种逻辑的方式记录 Page 内的更新操作,上图给出的一种实现方式是记录操作类型,以及目标对象的完整内容。
此外,Log 按抽象程度还可以分为 High-Level Log 以及 Page-Oriented Log。Logical Log 属于 High-Level Log。Physical Log 和 Physiological Log 属于 Page-Oriented Log。
Trade Offs
| Log 格式 | 数据量 | 幂等 | Redo 速度 | Undo 速度 |
|---|---|---|---|---|
| Physical Log | 大(设想一下 Slotted Page 结构的 Table Page,删除一个 Tuple 可能需要挪动这个 Page 内的很多的 Tuple,这需要记很多 Log; Index Page 插入和删除 Index Entry 同理) | 是 | 快(Page 间相互独立,各个组件(比如 Table 和 Index)的 Redo 无依赖,可并行 Redo | 快(Log 记录了 Page Id,可直接读取该 Page 进行 Undo) |
| Logical Log | 小(如果采用记录 SQL 语句的方式,一条语句只需一条 Log) | 否 | 不支持 Redo(因为 Logical Redo 只能作用于 Operation Consistency 的数据上。如果磁盘上的数据只反映了一些操作的部分更新,它就不是 Operation Consistency 的。例如 Insert 一个 Tuple 导致一个 Index Page 发生了 Split,这个 Index Page 上的一半数据会被挪到另一个新的 Index Page 上。Logical Log 只会记录我们 Insert 了一个 Tuple,不会记录这两个 Page 上的细节变化。如果数据库挂掉时这两个 Index Page 只有一个刷盘了,我们仍然按照 Logical Log 来 Redo,最终的数据是什么样的,全靠运气编程了😂) | 慢(需要先查找到具体的 Page,才能做Undo) |
| Physiological Log | 中(虽然会记录具体的 Page,但 Page 内部的更新是以逻辑的方式来记录的) | 否 | 快(同 Physical Log) | 快(类似 Physical Log) |
从上面这个表格不难看出,Redo Log 应该采用 Physical Log 或者 Physiological Log 这种 Page-Oriented 的方式(Page-Oriented Redo),以达到最佳的 Redo 性能。那么,Undo Log 也应该采用 Page-Oriented 的方式,以达到最佳的 Undo 性能?
直接说答案:Undo 应该采用 Logical 的方式(Logical Undo) 而不是 Page-Oriented 的方式(Page-Oriented Undo)。原因有两点:
-
Logical Undo 能够大大提高事务的并发度,因为
-
采用 Physical Undo 或者 Physiological Undo,不同事务不能并发更新同一个 Index Page。
设想这样一个场景,事务 T1 向 Index Page 插入了一条 Index Entry,接着事务 T2 插入了另外一些 Index Entry,正好触发了 Page Split。事务 T1 插入的那条 Index Entry 被挪到了另外一个 Page 上,然后事务 T1 执行出错要进行回滚。
Physical Undo 会死板地用更新前的镜像做覆盖式地 Undo,显然是无效的。Physiological Undo 也没法工作,尽管它可以处理 Index Entry 在 Page 内任意挪动的场景,但是对于 Index Entry 挪到了其他 Page 上的这种场景,Physiological Undo 在 Page 内做逻辑地 Undo 也回天乏术。因此,要正确使用这两种方式来做 Undo,必须配合 Index Page 的 Lock 而不是 Latch(违反了 Early Lock Release 技术,并发度低),保证事务执行期间更新的 Index Page 不会被别的事务并发更新。
与之相反,Logical Undo 只需要对 Index Page 加 Latch。因为 Logical Undo 不关心数据具体存在哪个 Page,它在 Undo 的时候会先查找数据所在的 Index Page,然后再在做逻辑地 Undo。
-
采用 Physical Undo,不同事务不能并发更新同一个 Table 的统计信息(例如 Free Space 的大小,Tuple 的数量)。
设想这样一个场景,某个 Table 当前 Tuple 数量为 10,事务 T1 插入 2 个 Tuple 后将 Tuple 数量增加到 12,事务 T2 插入 1 个 Tuple 后将 Tuple 数量增加到 13,然后事务 T1 执行出错要进行回滚。
Physical Undo 会将 Tuple 数量覆盖式地更新为 10,如果事务 T2 最终提交,那么数据就不一致了。
Logical Undo 在 Undo 的时候可以对 Tuple 数量执行逻辑减 2 操作,更新为 11,即便事务 T2 提交,数据也是一致的。
Physiological Undo 在这里和 Logical Undo 作用的一样的,因为统计信息一般都是在一个固定的 Table Page 中。
-
-
Undo 并不频繁,Logical Undo 因查找 Page 导致的速度慢是可以接受的。
P.S., InnoDB 的 Redo Log 属于 Physiological Log。InnoDB 的 Undo Log,MySQL Binlog 的 Row-Based Log 和 Statement-Based Log,还有 VoltDB 的 Transaction-Level(Command) Log 都属于 Logical Log。
Checkpoint
为什么需要?
我们通过记录 Log 来帮助数据库可以从挂掉的状态中恢复,然而长时间运行的数据库的 Log 会不断增加,制造出两个问题:
- Recovery 期间需要解析并处理全量 Log,越来越慢。
- Log 累积过多会占用大量磁盘空间。
Checkpoint 用来解决这两个问题。
是什么
每次做 Checkpoint,就好像在 Log 中打了一个标记,我们认为这个标记之前的所有 Log 都不会被再用到,Recovery 期间可以直接跳过。这些 Log 甚至可以直接删掉(尤其是在支持 Point-In-Time Recovery 的数据库中,Log 可能已经被增量备份在其他地方,本文不展开)。
如何实现?
通常有 Consistent Checkpoint 和 Fuzzy Checkpoint 两个方案。
Consistent Checkpoint 是最朴素的实现,步骤如下:
-
禁止新事务启动,等待正在执行的事务结束(其实就是停服)。
-
遍历 Buffer Pool,将所有 Dirty Page 刷盘。
-
记录一条 Checkpoint Log。
-
允许所有事务正常执行(恢复服务)。
Recovery 直接从 Checkpoint Log 开始,之前的 Log 一律跳过。
为什么可以跳过之前的 Log?因为 Consistent Checkpoint 先停服然后把所有 Dirty Page 刷盘,保证了 Checkpoint Log 之前的所有 Log 对应的 Page 的改动已经被刷到了磁盘上,并且这些 Page 不包含未提交的数据,不需要再考虑 Redo 或者 Undo,它们的 Log 自然也就不再关心了。
为什么需要停服?如果不停服,并发事务的 Log 可能有一部分在 Checkpoint Log 前,一部分在 Checkpoint Log 后。按照 Recovery 从 Checkpoint Log 开始的规则,并发事务的一部分更新不会被处理,可能导致数据不一致。
虽然 Consistent Checkpoint 解决了上面提到的 Log 制造出的的两个问题,但是它的性能很糟糕。为了做 Checkpoint 而使数据库停服不可接受。ARIES 提出了一种 Fuzzy Checkpoint 的方案,实现了在线 Checkpoint,下文会详细介绍。
ARIES
主要思想
- WAL with STEAL/NO-FORCE
- 我们要 Runtime 性能!
- Repeating history during redo
- Recovery 期间做 Redo 的时候重放历史,无论是已提交,未提交还是已回滚的事务,都要 Redo 一遍。(下文会解释为什么)
- Logging changes during undo
- 在事务回滚做 Undo 的时候,要为 Undo 产生的更新操作记录 Redo Log。(下文会解释为什么)
技术亮点
这里列一下笔者看了论文之后印象比较深的一些技术亮点:
- 支持 Tuple-Level Lock,只在 Page 上加 Latch(换句话说,支持 Early Lock Release 技术)
- 支持 Page-Oriented Redo,Logical Undo
- 支持 Fuzzy Checkpoint(下文会详细介绍)
- 支持 Partial Rollback(下文会详细介绍)
- 支持 Nested Top Actions(下文会详细介绍)
术语
-
LSN:全称是 Log Sequence Number。它是 Log 的编号,始终单调递增。
- Log Header:每一条 Log Record 都是由 Log Header 和具体的 Log 数据组成。Log Header 中一般有 Log Size,LSN,Transaction ID,Prev LSN(见下面介绍),LogType(见下面介绍) 等字段。
- Prev LSN:同一个事务中后一条 Log 会把前一条 Log 的 LSN 记录在 Log Header 的 Prev LSN 字段中,形成一个反向链表,便于 Undo 时逆序回溯事务的 Log。
- Log Type:一般有事务相关的 Type:Begin,Commit,Abort,End(End 有点特殊,下文会详细介绍);普通 Log(包含 Redo Log,Undo Log 和 CLR(见下面介绍))的 Type:Insert,Update,MarkDelete,ApplyDelete,RollbackDelete 等;Checkpoint Log 的 Type:Checkpoint;为一个文件分配新 Page 的 Type:NewPage。
- CLR:全称是 Compensation Log Record,中文一般翻译为补偿日志。由于 ARIES 采用 Logical Undo,Undo 操作不是幂等的,不可以重复执行。我们通过为 Undo 操作记录 Redo Log 来物化 Undo 操作,同时记录 Undo 的进展(通过 UndoNextLSN 的实现,见下面介绍),保证已经 Undo 了的操作不会再被 Undo。Undo 产生的这些 Redo Log 就叫做 CLR。此外,CLR 是 Redo-Only 的,不支持 Undo,这一特点保证了 Undo 是有界的,Recovery 期间 Undo 过程中挂掉并不会增加 Undo 的工作量。这就是为什么 ARIES 要「Logging changes during undo」。
-
UndoNext LSN:每条 CLR 中都会记录 UndoNext LSN,用来指示下一条需要 Undo 的 Log 的 LSN。如果 Undo 到一半数据库挂掉后重启,我们在重新执行 Undo 时,只需先取出最后一条 CLR Log 的 UndoNext LSN,就能继续之前的 Undo 工作。
-
Log Buffer:内存中分配的用来临时存放 Log 的一段空间。事务执行期间写 Log 只写到 Log Buffer 中,直到事务提交的时候统一刷盘。这种做法有利于减少磁盘 IO,提升性能。(很方便我们实现 Group Commit 特性,本文不展开。)
-
Master Record:磁盘上的一个文件,记录最近一次 Checkpoint Log 的 LSN。它能够帮助我们在 Recovery 期间快速找到最近一次 Checkpoint 的 Log。
-
Flushed LSN:已经刷到磁盘上的 Log 中最大的 LSN。它是一个内存中的变量。
-
Page LSN:对于一个 Page,最近一次更新操作对应的 Log 的 LSN。记录在 Page Header 中。
-
Rec LSN:对于一个 Page,自从上一次刷盘以来,第一次更新操作对应的 Log 的 LSN。
-
Last LSN:每个事务最近一次更新操作对应的 Log 的 LSN。
-
DPT:全称是 Dirty Page Table。记录了所有的 Dirty Page 以及它们的 Rec LSN。它是一个内存中的数据结构。
- ATT:全称是 Active Transaction Table。记录了所有活跃事务(事务在执行中,还没有提交或回滚)以及它们的状态(Undo Candidate,Committed,下文会介绍)和 Last LSN。它也是内存中的一个数据结构。
Runtime Log
先说明,下文普通 Log (Redo Log 和 Undo Log 记到同一条)表示为 「LSN:<Transaction ID, LogType, Page Id, Before Image, After Image>」。
CLR 表示为 「LSN:<Transaction ID, Log Type, Page Id, Before Image, After Image, UndoNextLSN>」。
事务相关 Log 表示为「LSN:<Transaction ID, LogType>」。
其他 Log 的表示方法类似,这里不详细描述了,下文遇到的时候看图就能懂。
对于普通 Log 和 CLR 的 Log Type,使用缩写 I,U,D 来分别表示 Insert,Update,Delete。
事务提交
上图是一个已提交事务的完整 Log。事务启动时记录 Begin Log(LSN 40),提交时记录 Commit Log(LSN 43), 最后还会跟上一条 End Log(LSN 44)。这里要注意,事务提交时,只要求将 Commit Log 以及之前的 Log 全部刷盘,End Log 可以异步刷盘。因为 End Log 的作用只是为了编码方便,告诉我们后续不会再有这个事务的 Log 出现。
事务回滚
上图是一个已回滚事务的完整 Log。事务启动时记录 Begin Log(LSN 40),回滚时需要先记录一条 Abort Log(LSN 42),然后 Undo 操作执行期间会记录一些 CLR( LSN 43,44)。与事务提交一样,最终会跟上一条 End Log(LSN 45)。
整体可视化
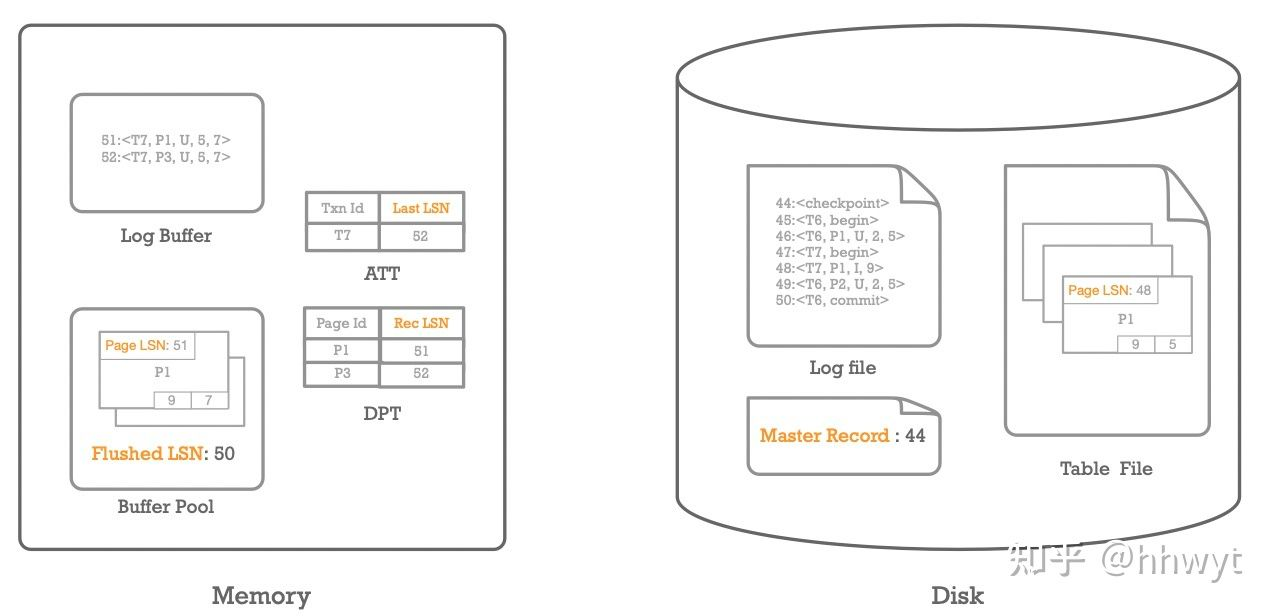
上图是 ARIES 算法的整体可视化。宏观看由两部分组成,左半区是内存相关的一些东西,有 Log Buffer,Buffer Pool,ATT,DPT 等数据结构。右半区是磁盘相关的一些东西。有 Log File,Master Record,Table File 等文件。
我们可以看到 Log Buffer 中有一些 Log,还有一些 Log 已经刷到了磁盘上的 Log File 中,Log File 中最大的 LSN 为 50,因此内存中的 Flushed LSN 是 50。
Log File 显示最近的一次 Checkpoint 的 LSN 是 44,这个在 Master Record 中亦有体现。
通过人肉分析 Log 我们可以看到事务 T6 已经提交(它的 Commit Log 已经刷盘,尽管 End Log 还没有写),事务 T7 尚未提交。所以 ATT 中只记录了 T7 以及它最后一次更新操作对应的 Log 的 LSN 52。
对于 Page P1 而言,上一次 Checkpoint 后,事务 T6 把它之上的一个 Tuple 从 2 改成了 5,接着事务 T7 又向它插入了一个 Tuple 9,这两次更新操作已经反映到了磁盘上的 P1 上(被 Buffer Pool 刷盘过),磁盘上 P1 的 Page LSN 是 48 也体现了这一点。后来事务 T7 又将 P1 上的一个 Tuple 从 5 改成了 7,这次更新操作只反映到了内存中的 P1 上,所以我们看到内存中的 P1 的 Page LSN 是 51,磁盘上的 P1 的 Page LSN 仍然是 48。自从上一次刷盘以来,P1 的第一次更新操作的 Log 的 LSN 是 51,我们可以看到 DPT 中记录了 P1 和 Rec LSN 51。此外,还有一个 Page P3 也被更新且未刷盘,同样记录在 DPT 中。
Recovery 流程
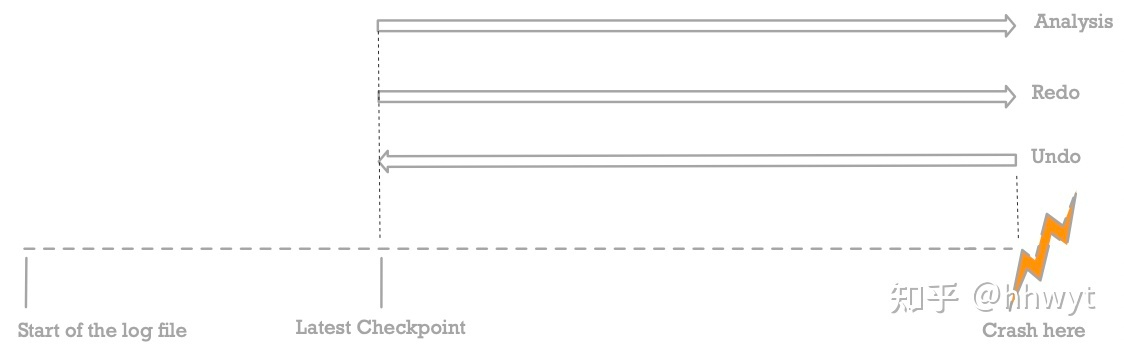
上图是 ARIES 的 Recovery 流程,Checkpoint 采用 Consistent Checkpoint 方案。虚线是我们的 Log,按时间顺序从左到右排列。我们从左往右看,最左侧是 Log 的起始位置,中间有做过一次 Checkpoint,最右侧是数据库挂掉时最新的 Log 的位置。从图中可以看到 Recovery 的三个阶段,对应三个长箭头,箭头的方向表示该阶段扫描 Log 的方向,箭头向右表示顺序扫描,向左表示逆序扫描。
接下来详细介绍一下这三个阶段:
- Analysis
- 从最近的一次 Checkpoint Log 的位置开始,顺序扫描所有 Log,恢复出 ATT 和 DPT。
- ATT:对任意一个事务 Ti ,如果
- 遇到 Ti 的 Begin Log,就把 Ti 加入 ATT,同时把状态设为 Undo Candidate。
- 遇到 Ti 的 Commit Log,就把 ATT 中的 Ti 状态设为 Committed。
- 遇到 Ti 的 End Log,就把 Ti 从 ATT 中移除。(这就是 End Log 的作用)
- 遇到 Ti 的其他 Log(即 Redo,Undo,CLR 和 Abort Log),更新 Ti 的 Last LSN。
- DPT:遇到任意 Redo Log 或 CLR,如果对应的 Page
- 不在 DPT 中:将它加入 DPT,同时记录 Rec LSN。
- 已经在 DPT 中:无需处理。
- ATT:对任意一个事务 Ti ,如果
- 从最近的一次 Checkpoint Log 的位置开始,顺序扫描所有 Log,恢复出 ATT 和 DPT。
-
Redo
- 找到 DPT 中最小的 Rec LSN,将它作为起始点,顺序扫描 Log 并处理来重放历史(实际上就是 Redo 所有事务的 Redo Log 以及 CLR 对应的更新操作)。
- 当且仅当 Log LSN > Page LSN,一个 Log 对应的更新操作才能在对应的 Page 上 Redo。(由于 Buffer Pool 可能在 Checkpoint 后对 Page 进行刷盘,所以 Log LSN < Page LSN 的可能性是很大的。)
- 为 ATT 中所有状态为 Committed 的事务写一条 End Log,同时把它从 ATT 中移除。
- 找到 DPT 中最小的 Rec LSN,将它作为起始点,顺序扫描 Log 并处理来重放历史(实际上就是 Redo 所有事务的 Redo Log 以及 CLR 对应的更新操作)。
-
Undo
- 找到 ATT 中最大的 Last LSN,Undo 它对应的事务,Undo 完成后把该事务从 ATT 中移除。
- 重复上面步骤,直到 ATT 为空。
当上述三个阶段执行完毕,Recovery 流程结束,数据库即可正常对外提供服务。
这里回答一下上文提到的一个问题:为什么要重放历史(Repeating history during redo)?首先上文有提到一个 Operation Consistency 的概念,我们说 Logical Redo 只能作用于 Operation Consistency 的数据上。实际上,更准确地说,应该是 Logical Operation 只能作用于 Operation Consistency 的数据上。这一规则也适用于 Logical Undo。如果我们不重放历史,而是在 Redo 阶段只 Redo 已提交或者已回滚的事务,不 Redo 活跃事务(ATT 中的事务),在 Redo 阶段完成后,数据可能不是 Operation Consistency 的,没有办法做 Logical Undo。例如,一个事务中的一个 Delete 操作同时删除了 Table Page 和 Index Page 中的一条数据,在数据库挂掉前只有 Table Page 被刷盘了,并且这个事务没有提交。在 Recovery 期间,如果我们不 Redo 这个 Delete 操作,直接做 Logical Undo 向 Table Page 和 Index Page 各自 Insert 一条数据,那么 Index Page 中会出现重复的数据,导致 Index 状态异常。因此,我们需要通过重放历史来将数据库中的数据恢复到 Operation Consistency 的状态,保证后续 Logical Undo 的正确执行。此外,重放历史编码起来也比较简单,并且对 Recovery 性能影响较小(一般来说活跃事务的数目也不会非常多)。以上就是为什么 ARIES 要「Repeating history during redo」。
Fuzzy Checkpoint
上文提到,Fuzzy Checkpoint 是一个在线 Checkpoint 方案。Checkpoint 时可能会有并发的活跃事务(ATT 不为空),并且并发事务可能更新了一些 Page(DPT 不为空)。如果此时做 Checkpoint,记录一条 Checkpoint Log,实际上 Redo 的起始位置应该在 Checkpoint Log 之前(DPT 中最小的 Rec LSN),要 Undo 的一些事务的部分 Log 也在 Checkpoint Log 之前(ATT 中所有事务最小的 LSN)。换句话说,我们不能像 Consistent Checkpoint 那样,Recovery 直接从 Checkpoint Log 的位置开始了。如何保证 Recovery 的时候把 Checkpoint Log 之前的 Log 对应的更新操作该 Redo 的 Redo,该 Undo 的 Undo ?
ARIES 说,我们做 Checkpoint 的时候把 Checkpoint 时刻的 ATT 和 DPT 一同记录下来不就行了。Checkpoint Log 中记录的 ATT 和 DPT 将作为 Recovery 启动时 ATT 和 DPT 的初始状态,依据初始状态我们可以知道 Checkpoint Log 之前有哪些 Log 需要处理。然后我们从 Checkpoint Log 位置开始执行 Analysis 阶段,重做 ATT 和 DPT 后续的增量改动,恢复出完整的 ATT 和 DPT,接下来不就和 Consistent Checkpoint 一样了么。
解决方案就是这么简单朴实无华。
如何记录 ATT 和 DPT 呢?方案有一点 Trick。我们可以先对 Log Buffer(新事务和更新操作的 Log 会被延后)加 Latch,接着对 ATT 和 DPT 加 Latch,然后拷贝 ATT 和 DPT 并记录 Checkpoint Log。Checkpoint Log 中记录的是 Checkpint 时刻 ATT 和 DPT 的快照。这种做法的缺点是 Latch 的持有时间有点长,对系统负载影响比较大。实际上我们并不需要拿到 ATT 和 DPT 快照。我们可以把 ATT 和 DPT 分成很多个 Partition,每次只加单个 Partition 的 Latch, 然后拷贝这个 Partition,最终经过多次拷贝我们就能够得到一份完整的 ATT 和 DPT。这种做法 Latch 的持有时间很短,对系统的负载影响很小。拷贝出来的 ATT 和 DPT 相当于某一时刻的快照加该时刻后续的部分增量改动。Analysis 阶段拿着这份 ATT 和 DPT 从这个「某一时刻」开始,重做后续的全部增量改动,Checkpoint 期间拷贝过程中漏掉的增量改动会被重做,已经包含的增量改动也会被重做但不影响正确性,因为增量改动的重做是幂等的。
ARIES 通过记录一条 Checkpoint Begin Log 来明确这个「某一时刻」的位置。
详细步骤如下:
- 先记录一条 Checkpoint Begin Log。
- 通过多次对 ATT 和 DPT 加单个 Partition 的 Latch,拷贝出一份完整的 ATT 和 DPT。
- 记录一条 Checkpoint End Log。Log 内容包括 ATT 和 DPT 的信息。然后把 Log 刷盘。
- 把 Checkpoint Begin Log (也可以加上 Checkpoint End Log)的 LSN 信息记录到 Master Record 中。
Recovery 的时候,先从 Master Record 中找到 Checkpoint Begin Log 的位置,然后找到 Checkpoint End Log 的位置,恢复出 ATT 和 DPT 的初始状态,接着从 Checkpoint Begin Log 位置开始执行 Analysis 阶段即可。

上图是 Fuzzy Checkpoint 的 Log。我们可以看到事务 T7 更新了 Page P1 后(LSN 41),Checkpoint 开始,先记录了一条 Checkpoint Begin Log(LSN 42),然后 Checkpiont 进程开始慢慢拷贝 ATT 和 DPT。这期间事务 T7 又更新了 Page P2(LSN 43),并且新的事务 T8 启动了(LSN 44)。最终拷贝完成后的 ATT 有 T7,DPT 有 P1 和 P2。P1 是必须有的,P2 是可有可无的,因为 P2 是 DPT 在 Checkpoint Begin Log 之后的增量改动,即便这里没有记录,由于 Analysis 阶段会从 Checkpoint Begin Log 开始,它也会被恢复出来。
自从有了 Fuzzy Checkpoint,Recovery 的三个阶段就变成这个样子:
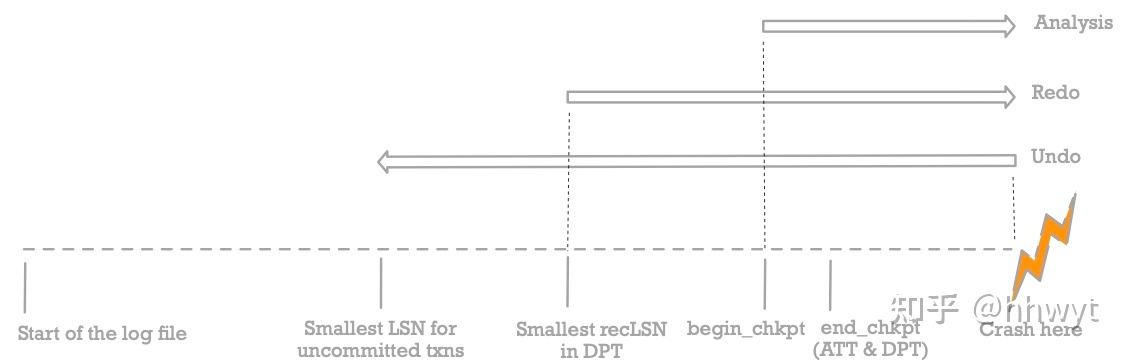
笔者自我感觉上面这幅图比较清晰,就不解释了。
注意,由于 ARIES 有能力在 Recovery 的时候处理 Checkpoint Log 之前的 Log,所以不强制要求 Checkpoint 的时候把所有 Dirty Page 刷盘。我们可以启动一个专门的线程来定期或者按需刷盘,有利于集群的负载稳定。
Partial Rollback
这个玩意实际上指的就是 Savepoint 子事务。ARIES 提出了一种方案解决子事务回滚,父事务提交的场景。

如上图,ARIES 支持子事务回滚的方式很简单,类似父事务,为子事务回滚产生的所有 Undo 操作记录 CLR 即可。
Nested Top Actions
有一些特殊的操作,一旦执行成功就不能再 Undo。比如在一个事务中为某个 Table 分配了一个新的 Page,分配成功后可能会有一些其他的事务会更新这个 Page,如果分配 Page 的事务回滚(销毁这个 Page),那么其他事务的更新会丢失。
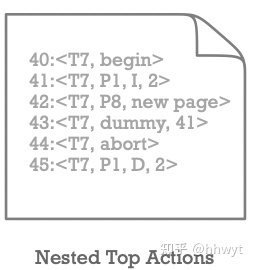
如上图,ARIES 中这种操作(LSN 42 对应的操作)执行成功后,会跟上一条 Dummy CLR Log(LSN 43),Dummy CLR 的 UndoNext LSN 会故意跳过这种操作的 Log(LSN 43 的 UndoNextLSN 直接指向 LSN 41),这样即便后续事务回滚,这种操作也不会回滚。
总结
本文介绍了 ARIES 这个经典的 Recovery 算法。它的核心思想是 WAL with STEAL/NO-FORCE,Repeating history during redo 以及 Logging changes during undo,支持 Page-Oriented Redo,Logical Undo ,Fuzzy Checkpoint,Partial Rollback,Nested Top Actions 等诸多特性。我们不得不承认,它就是 Disk-Based 数据库在 Recovery 方面的最佳实践。ARIES 在一系列商业和开源数据库中都有应用,如 Oracle,MySQL 以及 Postgres。然而,ARIES 诞生至今已经整整三十年了,在这三十年中,硬件的发展是如此迅速,以致于它对硬件的一些假设已经慢慢变得不成立了。例如,现在有针对大内存的 In-Memory 数据库,所有数据都放在内存中,只需要 Redo 不需要 Undo;也有正在发展的 NVM 数据库,事务提交时无脑刷盘,只需要 Undo 不需要 Redo(WBL 协议)。嘿嘿,笔者就以教员的一句诗作为结尾吧:「俱往矣,数风流任务,还看今朝。」(最后这一句权当玩笑)
参考
- ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging
- Database System Concepts, 7th, Avi Silberschatz, Henry F. Korth, S. Sudarshan
本文作者:hhwyt
本文链接:https://hhwyt.xyz/2021-11-29-aries
版权声明:本博客所有原创文章均采用 CC BY-NC-SA 4.0 许可协议。转载请注明出处!
留下评论