
How TiKV Reduces Write Stalls Caused by RocksDB SST Ingestion
TiKV adopts RocksDB as its storage backend, utilizing RocksDB’s
methods like Write() for regular foreground key-value writes and IngestExternalFile() method for bulk loading. IngestExternalFile() directly ingests SST files into the lowest possible level of the RocksDB LSM-tree, minimizing MemTable writes and reducing compactions.
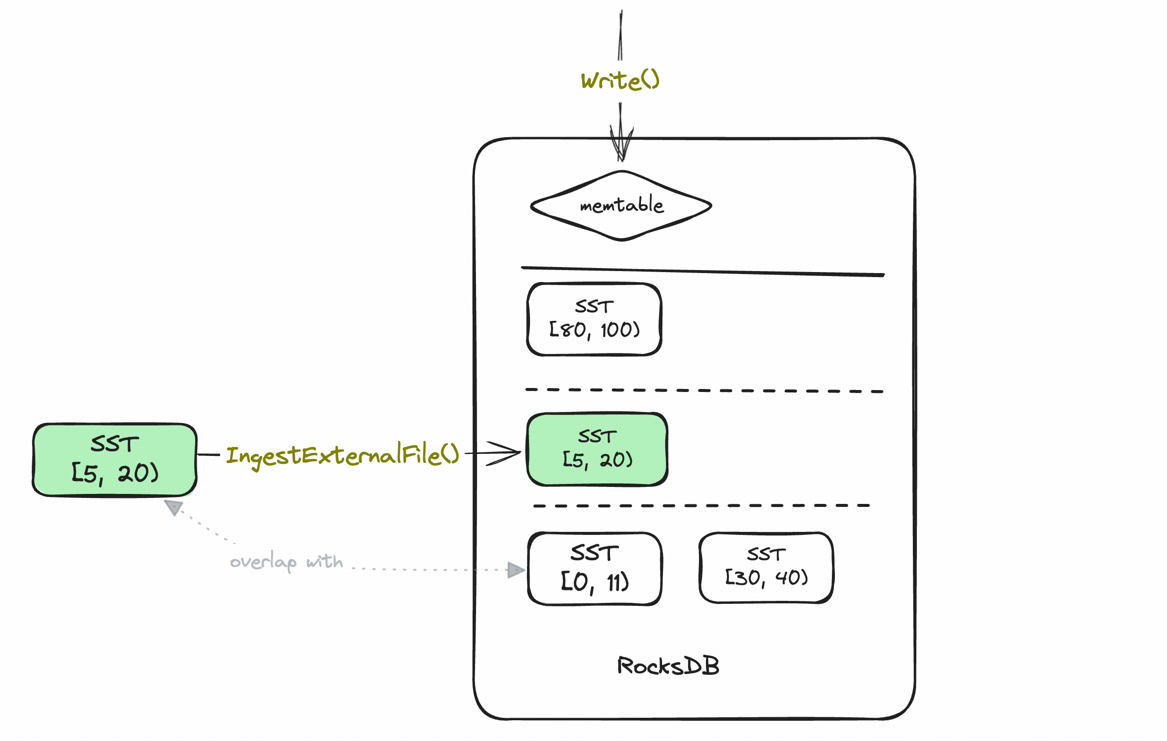
To ensure sequence number consistency, IngestExternalFile() triggers a write stall, temporarily pausing foreground writes during data ingestion. This can cause write latency jitter, especially in TiKV cluster scaling scenarios where a large number of Regions need to migrate(i.e., their data is dumped as SST on old nodes and ingested to new nodes). In TiKV, all
Regions on the same node share a single RocksDB instance. When ingestion triggers a write stall, it affects all Regions on that node, significantly increasing long-tail write latency. This becomes a challenge in delivering stable performance for our customers.
In this post, we’ll explore this challenge in detail and discuss how TiKV addresses it.
Sequence Number Consistency in RocksDB
RocksDB’s sequence number consistency requires that, for a given key in the LSM-tree, the sequence number of the higher-level version must be greater than that of the lower-level version. This allows reads to return immediately if a key is found at a higher level, without needing to access lower levels. This reduces the cost of accessing lower levels, thereby improving performance and ensuring that reads are up-to-date, i.e., no stale reads.
Keys in SST files, ingested via IngestExternFile(), are also assigned sequence numbers and typically share a global sequence number, which is stored in the SST file’s metadata.
To prevent stale reads, SST files can be ingested into a level of the LSM-tree only if there are no range-overlapping SSTs at higher levels, since such SSTs might contain overlapping keys with smaller sequence numbers.
Another reason for maintaining sequence number consistency is atomic reads. Without consistency, a RocksDB scan meant to return all data from ingested SSTs may instead return a mix of fresh data from ingested SSTs and stale data from higher levels or the MemTable, breaking the atomicity of reads on ingested SST data.
How IngestExternFile() Maintains Sequence Number Consistency
According to the RocksDB wiki, we can see that:
When you call DB::IngestExternalFile() We will
- …
- Block (not skip) writes to the DB because we have to keep a consistent db state so we have to make sure we can safely assign the right sequence number to all the keys in the file we are going to ingest
- If file key range overlap with memtable key range, flush memtable
- Assign the file to the best level possible in the LSM-tree
- Assign the file a global sequence number
- Resume writes to the DB
This “block-and-resume” process refers to the write stall mentioned earlier. The guarantees provided by this process include:
- Overlapping keys before ingestion, with a smaller sequence number, must be placed at a lower level. If the key exists in the MemTable, it will be flushed to L0, and the ingested SSTs will also be placed in L0 with a higher sequence number. An SST with a higher sequence number at the L0 level is treated as “higher”.
- Overlapping keys during ingestion can not occur, as write stall is triggered. The write stall acts like a lock, ensuring that the assignment of sequence number to ingested SSTs and the update of RocksDB metadata are preformed atomically, preventing race conditions in sequence number assignment with foreground writes.
- Overlapping keys after ingestion, with a greater sequence number, must be placed at a higher level. For foreground writes after SST ingestion, they will write to the MemTable, which is the highest level.
As mentioned earlier, this approach negatively impacts stable performance. Optimizing it could involve reducing the write stall duration or eliminating it entirely.
First Attempt: Removing MemTable Flush from Ingestion Path
The first attempt(TiKV#3775) aimed to reduce the write stall duration by removing the MemTable flush from ingestion path. Flushing MemTable is an expensive I/O operation, and eliminating it significantly reduces the write stall duration.
This approach utilizing an option provided by RocksDB: allow_blocking_flush. When set to false, and if IngestExternalFile() requires a memtable flush, the IngestExternalFile() will fail.
The optimized ingestion process works as follows:
- TiKV first calls
IngestExternalFile()withallow_blocking_flush = false.- If no MemTable flush is needed, ingestion continues as usual.
- Else:
IngestExternalFile()fails, and TiKV manually callsFlush()to flush the MemTable.- Then TIKV calls
IngestExternalFile()again withallow_blocking_flush = true.
In most cases, the flush is handled by Flush(), which occurs outside the write stall, effectively removing the MemTable flush from the ingestion path.
This optimization reduces TiKVs maximum write duration by ~100x, as shown in the figure below:
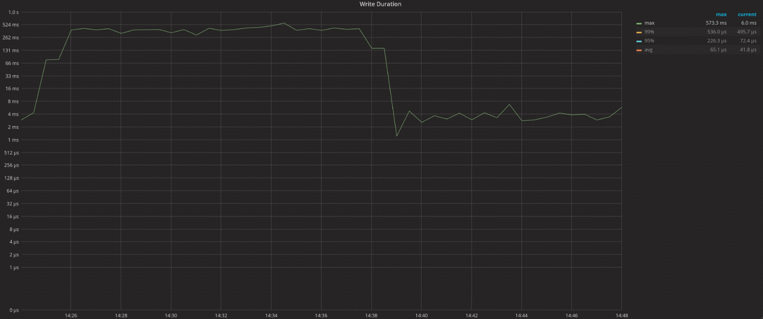 (Left part: without optimization, Right part: with optimization)
(Left part: without optimization, Right part: with optimization)
Second Attempt: No Write Stall Ingestion
While the first optimization significantly reduced write stall duration, there is still room for further performance improvements, as write stalls still occur.
Can we eliminate the write stall entirely? What if user can ensure that there are no concurrent foreground writes overlapping with the SSTs being ingested?
TiKV is based on Raft, a sequential commit consensus protocol, unlike Paxos. Therefore in TiKV, at any given time, for a specific Region, only one thread can write data at the Raft layer. This sequentiality holds true during:
- Region creation: a single thread ingests SSTs to load the Region’s data.
- Region normal state: a single thread handles foreground writes to the Region.
- Region destruction: a single thread cleans up the Region’s data.
However, there is still a scenario where concurrent writes can occur—compaction-filter GC(garbage collection). compaction-filter GC is a low-level operation in the RocksDB layer, bypassing Raft’s layer.
Compaction-filter GC utilizes RocksDB’s Compaction Filter mechanism, and during compaction, it calls back to TiKV’s logic to evaluate the validity of key-value pairs and discard invalid versions, thereby implementing TiKV’s MVCC GC.
Since TiKV uses multiple column families(CFs), only the keys in the Write CF contain version information (commit-ts) that determines the validity of a key. To prevent the Default CF from being unaware of key validity after Write CF’s compaction-filter GC, GC for the Default CF must be triggered during the Write CF’s compaction. This requires calling RocksDB’s Write() API on the Default CF to delete invalid data, which is why compaction-filter GC results in foreground writes that may run concurrently with SST ingestion.
To eliminate the write stall while maintaining the safety of compaction-filter GC, the second attempt proposed the following:
- Allowing concurrent writes during ingestion: This PR(RocksDB#400) introduces an
allow_writeoption in RocksDB’sIngestExternalFile(). By settingallow_write = true, ingestion could proceed without triggering the write stall. RocksDB users(e.g., TiKV) must ensure that there are no concurrent foreground writes overlapping during ingestion. - Using a range latch for mutual exclusion between compaction-filter GC and SST ingestion: This PR(TiKV#18096) introduces a range latch. The latch requires that both processes acquire the lock on the key range before starting. This guarantees that:
- Foreground writes triggered by compaction-filter GC won’t interfere with ingestion.
IngestExternalFile()can safely setallow_write = trueafter acquiring the latch, avoiding the write stall.
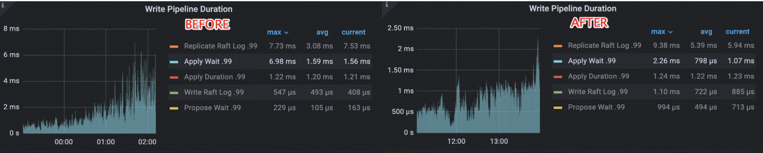
With this optimization, in the TPCC scenario, the P9999 write thread wait, which used to measured write stall, has been reduced by over 90% ~ 96%:
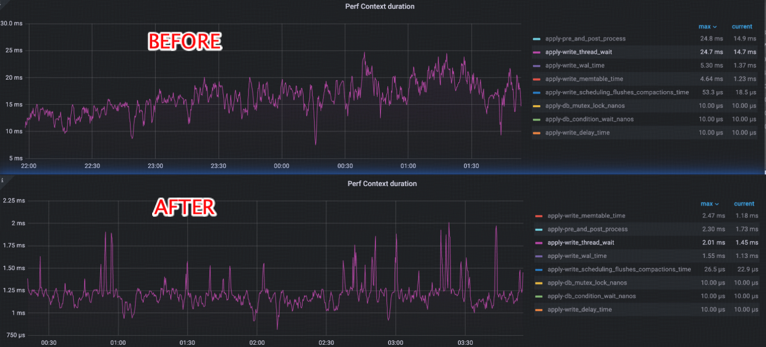
TiKV’s P99 Write Wait Latency (referred to as Apply Wait Latency in TiKV) has been reduced by ~50%:
Summary
This post begins by exploring the challenge of write stalls in TiKV caused by RocksDB SST ingestion. It then discusses TiKV’s efforts to reduce these write stalls. The first approach removed the MemTable flush, reducing write stalls and write durations by 100x. The second approach introduced the allow_write option in RocksDB and a range latch in TiKV to prevent concurrent writes between compaction-filter GC and ingestion, eliminating write stalls and reducing P9999 write thread wait latency by over 90% and P99 Write Wait Latency by ~50%.
留下评论