
TiKV 如何实现快速扩缩容并保持性能稳定
TiKV 是一款分布式的 KV 数据库。「分布式」要求 TiKV 能够实现集群快速扩缩容,「KV」 则要求 TiKV 能够保持低延迟和稳定的性能,因为通常服务于在线低延迟场景。在本文中,我们将探讨 TiKV 如何实现集群快速扩缩容,同时在扩缩容期间保持性能稳定。
背景
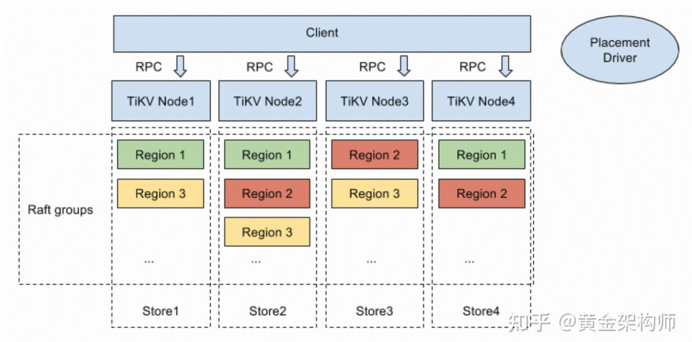
TiKV 基于 Multi-Raft 架构 —— 数据按照 key range 被划分为很多的 Region,每个 Region 通常有三个副本,形成一个 Raft group。每个 TiKV 节点管理着很多的 Region,这些 Region 的数据存储在节点内所有 Region 共享的 RocksDB 实例中。
在 TiKV 之外,PD(Placement Driver)作为全局调度器,负责 TiKV 集群的调度和管理。在扩缩容场景中,PD 会选择合适的节点作为 source node 和 target node,并下发副本迁移任务给 source node,让它将指定的 Region 副本迁移到 target node。对于扩容,source node 是集群中现有的节点,target node 是新加入的节点;对于缩容,source node 是即将移除的节点,target node 是缩容后仍保留的节点。无论扩容还是缩容,其流程和面临的性能问题基本是一致的。
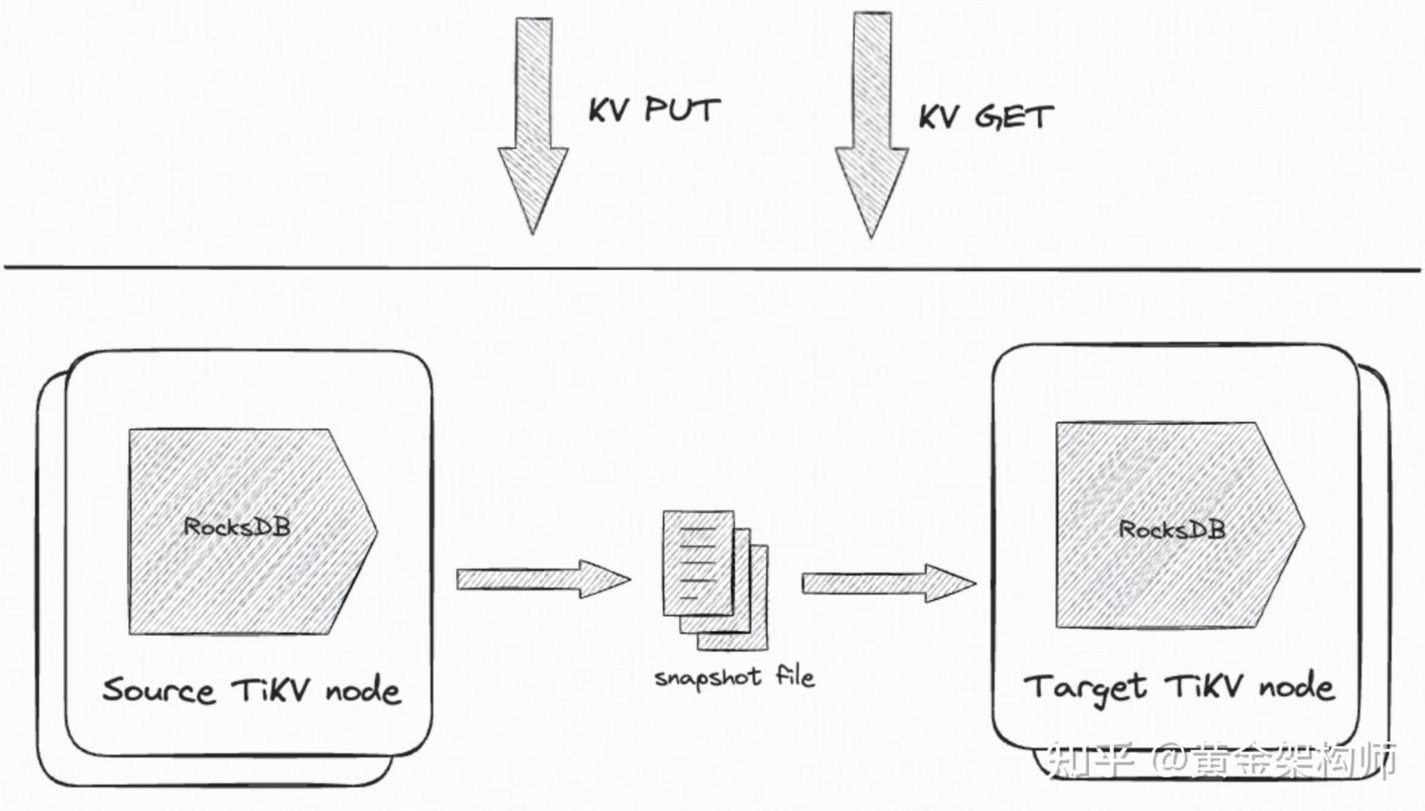
具体到 TiKV,其 Region 副本迁移过程主要包括以下几个步骤:
- 生成 snapshot:在 source node 上,通过 RocksDB 的 Iterator 读取指定 Region 的数据导出并生成 snapshot 文件。
- 传输 snapshot:source node 将 snapshot 文件传输给 target node。
- 应用 snapshot:在 target node 上,将接收到的 snapshot 文件加载到 RocksDB 中。
这个过程对 CPU 和 IO 的消耗不小,尤其是当扩缩容涉及大量 Region 时。因此,如何实现快速扩缩容并保证性能稳定,是一个不小的挑战。接下来,我们就来探讨 TiKV 在应对这个挑战时所做的一些工作。
通过 IngestSST 来应用 snapshot
在应用 snapshot 这一步,TiKV 利用 RocksDB 的 IngestExternalFile(下面简称 IngestSST) 接口来提升速度。具体来说,在生成 snapshot 时,直接将 Region 数据转化为 zstd 压缩后的 SST 文件,并在传输到 target node 后,通过 IngestSST 将这些文件直接批量导入到 RocksDB。
在扩缩容场景中,target node 通常不包含该 Region 的数据。如果这些 SST 文件与 RocksDB 的高层次 SST 文件没有 range overlap(也就是说不存在某个 SST 文件的 [start key, end key) 区间包含了该 Region 的数据),那么它们很可能会被直接被导入到 RocksDB 的 bottommost level。
与另外一种做法 —— 先导出 KV 数据,再传输到目标节点并通过 WriteBatch 写入 RocksDB —— 相比,IngestSST 存在明显的优势:
- 压缩后的 SST 文件显著减少了网络传输和磁盘 IO 的带宽开销。
- 直接导入 SST 文件避免了通过 WriteBatch 写入 RocksDB 的额外流程,降低了 CPU 开销。
- 数据直接写入 bottommost level,显著减少了写放大问题。
所以,IngestSST 是 TiKV 用于提升扩缩容速度的一项非常高效的优化措施。
避免 Write Stall 中 Flush Memtable
在 RocksDB 中,IngestSST 的流程如下:
- 停止前台写入。
- 如果 memtable 中存在 overlap 数据,则 flush memtable。
- 真正执行 ingest SST。
- 恢复前台写入。
这个流程会停止写入,也就是触发 write stall。触发 write stall 的必要性是,RocksDB 必须保证同一个 key 的 sequence number 在所有层次上保持正确顺序。如果在 flush memtable 之后,前台写入了一个 key 并分配了小的 sequence number,而之后 ingest SST 文件到更低层的同一个 key 使用了大的 sequence number,就会导致同一个 key 的 sequence number 在层次间失序。
write stall 尽管保证了正确性,但影响了前台性能。为了降低 write stall 的影响,TiKV 在 PR #3775 中进行了优化,将 flush memtable 操作移出了 write stall 的作用域,以此来减少 write stall 的持续时间。
改进后的流程是:
- 停止前台写入
- 如果 memtable 中不存在 overlap 数据,直接跳到步骤 3。否则报错返回 TiKV,TiKV 手动调用 RocksDB Flush 接口,执行一次不停写的 flush memtable,然后回到步骤 1,重新执行 ingest。
- 真正执行 ingest SST。
- 恢复前台写入。
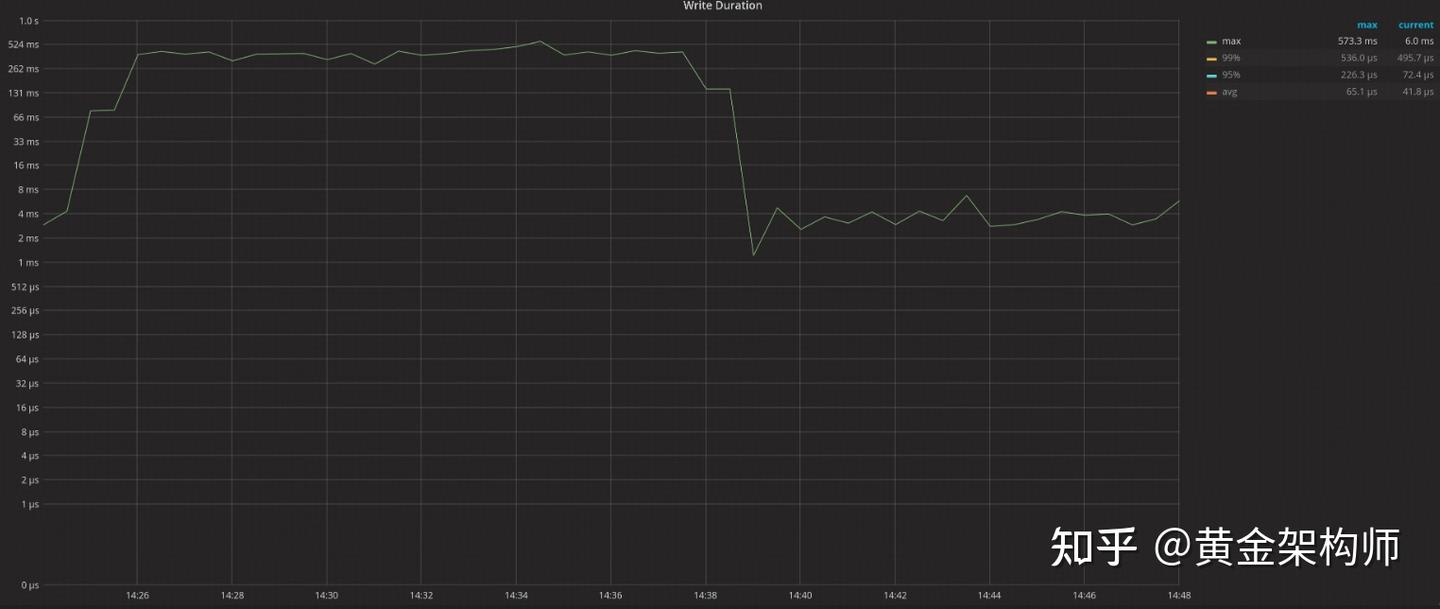
这一优化将 TiKV 前台写入 RocksDB 的最大延迟减少了约 100 倍,显著提升了性能。
允许 IngestSST 期间的写入
尽管通过上面的优化减少了 IngestSST 期间 write stall 的时长,但 write stall 本身仍然存在,对前台性能仍有影响。
在 TiKV 的场景中,write stall 实际上是可以避免的。因为 TiKV 的同一个 Region 在任意时刻只有一个线程负责写入操作,无论是在初始 Region(应用 snapshot)、Region 正常运行,还是销毁 Region 的过程中,都不会有并发写入的情况。换句话说,应用 snapshot 期间执行 IngestSST 时,TiKV 可以保证前台不会写入 overlap 的数据。
基于这一特点,我在 PR #18096 中为 RocksDB IngestSST 增加了 allow_write 选项(目前尚未合入 upstream),使得在 IngestSST 期间可以继续前台写入操作。TiKV 启用了 allow_write 后,P99 raft apply wait duration 明显减少。

限制资源使用
为避免 Region 迁移任务对前台性能产生影响,TiKV 对扩缩容任务的硬件资源使用率进行了限制,主要从以下两个方面进行优化:
- I/O Limiter:TiKV 使用基于令牌桶算法的 I/O Limiter 来限制扩缩容任务的 IO 消耗,确保迁移任务的 IO 使用量不会超过配置的阈值,从而减少对前台 IO 性能的影响。
- Snapshot Generator Thread Pool:在副本迁移过程中,生成 snapshot 是最耗费 CPU 资源的一步,因为需要将读取到的数据通过高压缩率的 zstd 算法生成 SST 文件。为了避免过多占用 CPU 资源,TiKV 限制了 snapshot generator thread pool 的线程数,从而控制迁移任务对 CPU 的使用。
总结与展望
以上是 TiKV 在提升扩缩容速度和保持性能稳定方面的一些工作。由于篇幅所限,还有许多优化细节未能一一讨论,有兴趣的读者可以查阅 TiKV 的文档和源码了解更多内容。
目前,为了确保扩缩容期间的性能稳定,TiKV 对后台任务的 IO 和 CPU 资源进行了限制。这种策略虽然有效保障了前台业务性能,但也在一定程度上限制了扩缩容的速度。如果希望进一步提升扩缩容性能,可以从以下方向进行优化:
一种优化思路是减少快照生成过程中对 CPU 和 IO 的开销。例如,我在这个 Proposal 中提出了一种方案:生成 snapshot 时,不再完全依赖 RocksDB 的 Iterator 扫描 Region 数据、压缩并重新生成 SST 文件,而是直接复用 bottommost-level 的 SST 文件作为 snapshot 的一部分,同时仅扫描非 bottommost-level 的数据生成 snapshot 的另一部分。该方案基于 TiKV 的 bottommost-level 数据已经按照 Region 边界切分,且通常占总数据量的 90% 左右这一特点。如果能够直接复用这些文件作为 snapshot,就能显著提升快照生成效率,在不增加 I/O Limiter 和线程池上限的情况下提高扩缩容吞吐量。
不过,该方案在采纳时面临两大挑战:一方面,它需要对 RocksDB 进行大量定制化修改,增加了维护的复杂性;另一方面,这个方案并非终极方案,仅能算是当前架构中的权宜之计。
终极方案是采用 Multi-RocksDB 的设计,即在单个 TiKV 节点上为每个 Region 配置一个独立的 RocksDB 实例。在这种架构下,生成某个 Region 的 snapshot 时,可以直接使用该 Region 专属 RocksDB 的所有文件,而无需筛选或扫描,从而显著提升快照生成的效率。这种设计对应于 TiKV 的 Partitioned Raft KV 实验特性。遗憾的是,该特性目前尚未稳定。
最后,期待 TiKV 在未来能够进一步提升扩缩容效率和性能稳定性!
留下评论