
真相!分布式数据库性能可击败传统数据库
网络上有很多贬低分布式数据库(e.g., TiDB, OceanBase),吹捧传统(单机)数据库(e.g., Postgres, MySQL)的文章,这类文章通常列出的一个关键论据是:传统数据库的性能可以全方位(各种负载下)击败分布式数据库(基于单机环境测试结果)。然而事实真的是这样的吗?作为一个利益相关的分布式数据库行业的产品经理,我认为我有必要站出来捍卫一下行业的声誉。为此,我选取了世界上最先进的开源传统数据库 —— Postgres,和世界上前三先进的开源分布式数据库 —— TiDB,进行了一系列的性能测试。我的测试结果表明:传统数据库和分布式数据库在性能上是互有胜负的,而不是一边倒的。如果你对我的测试感兴趣,就请继续往下看吧。
本文接下来的内容主要由两大部分组成。第一部分介绍性能测试的负载和环境。第二部分介绍先后进行的两次性能测试,一次是未调优的测试,一次是调优后的测试,同时我会对这两次测试的结果进行归因。
测试负载及环境
我选择使用 Sysbench 工具来进行性能测试。
CREATE TABLE `sbtest168` (
`id` int NOT NULL AUTO_INCREMENT,
`k` int NOT NULL DEFAULT '0',
`c` char(120) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
`pad` char(60) COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_168` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=25001 ...
Sysbench 数据集的数据模型很简单,整个被测数据库中有 N 张表(N 可以指定),每张表都是如上定义:表中有 4 列,包括一个单调递增的主键列,一个二级索引列,外加两个相对长一点的字符串列。表的宽度不到 200B。
-- oltp_write_only
begin;
UPDATE sbtest%u SET k=k+1 WHERE id=?;
UPDATE sbtest%u SET c=? WHERE id=?;
DELETE FROM sbtest%u WHERE id=?;
INSERT INTO sbtest%u (id, k, c, pad) VALUES (?, ?, ?, ?);
end;
-- oltp_insert
begin;
INSERT INTO sbtest%u (id, k, c, pad) VALUES (?, ?, ?, ?);
end;
-- oltp_point_select
begin;
SELECT c FROM sbtest%u WHERE id=?
end;
Sysbench 工具可以生成很多种类型的负载,由于精力财力有限,我只选择了其中三种进行测试。上面列出了这三种负载的具体 SQL,可以看到,oltp_write_only 负载的每个事务由多条单行写入组成(三条更新,一条插入),oltp_insert 负载是单行插入,oltp_point_select 负载是点查询。
测试的具体步骤大概是这样的:
- 生成数据。生成 10 张表,每张表导入 1000w 行数据。(总数据量大概在 20GB 多。)
- 跑负载。针对每一种负载,我们在不同并发(1-1024) 情况下,采用 cold run 方式(先重启数据库,清空 OS page cache 再跑),跑 10 分钟,然后统计 TPS 结果。
其他值得一提的事项:
- 数据分布采用 uniform 而不是 special。这是因为 special 分布只会访问热数据,而热数据全部在 cache 里面,访问它不需要磁盘 IO。由于我们测试的两个数据库都是 disk-based 数据库,没有磁盘 IO 的测试就是毫无意义的。
- 未使用 plan cache。如果你对双方都打开 plan cache(prepare statement) 后的性能感兴趣,可以自行测试一番。
测试的命令大致如下:
sysbench --db-driver=xxx --time=600 --threads=$num_thread --events=0 --rate=0 --report-interval=10 --db-ps-mode=disable $query_type --tables=10 --table-size=10000000
测试的软件版本如下:
- Sysbench: 1.0.20
- Postgres: 15(使用 Yum 安装)
- TiDB: 7.1.1(使用 TiUP 安装)
- OS: Centos 7.x
- FileSystem: 应该是 ext*,忘记看了。
我们使用单机环境进行测试。硬件规格如下:
- 机型:腾讯云 S5.2XLARGE32
- CPU:Intel Xeon Cascade Lake 8255C(2.5GHz/3.1GHz),8 cores,不支持超线程
- Mem: 32GB 容量,带宽未知
- Disk:1 块 100GB SSD 云硬盘,IOPS 4800/s,吞吐量 140M/s(高 IOPS,低带宽)
注意:我们的数据集总共 20GB 多,而机器总内存有 32GB,这意味着在负载跑一段时间后,数据基本上就都在内存里面了。
ROUND 1: 未调优的测试
关键参数
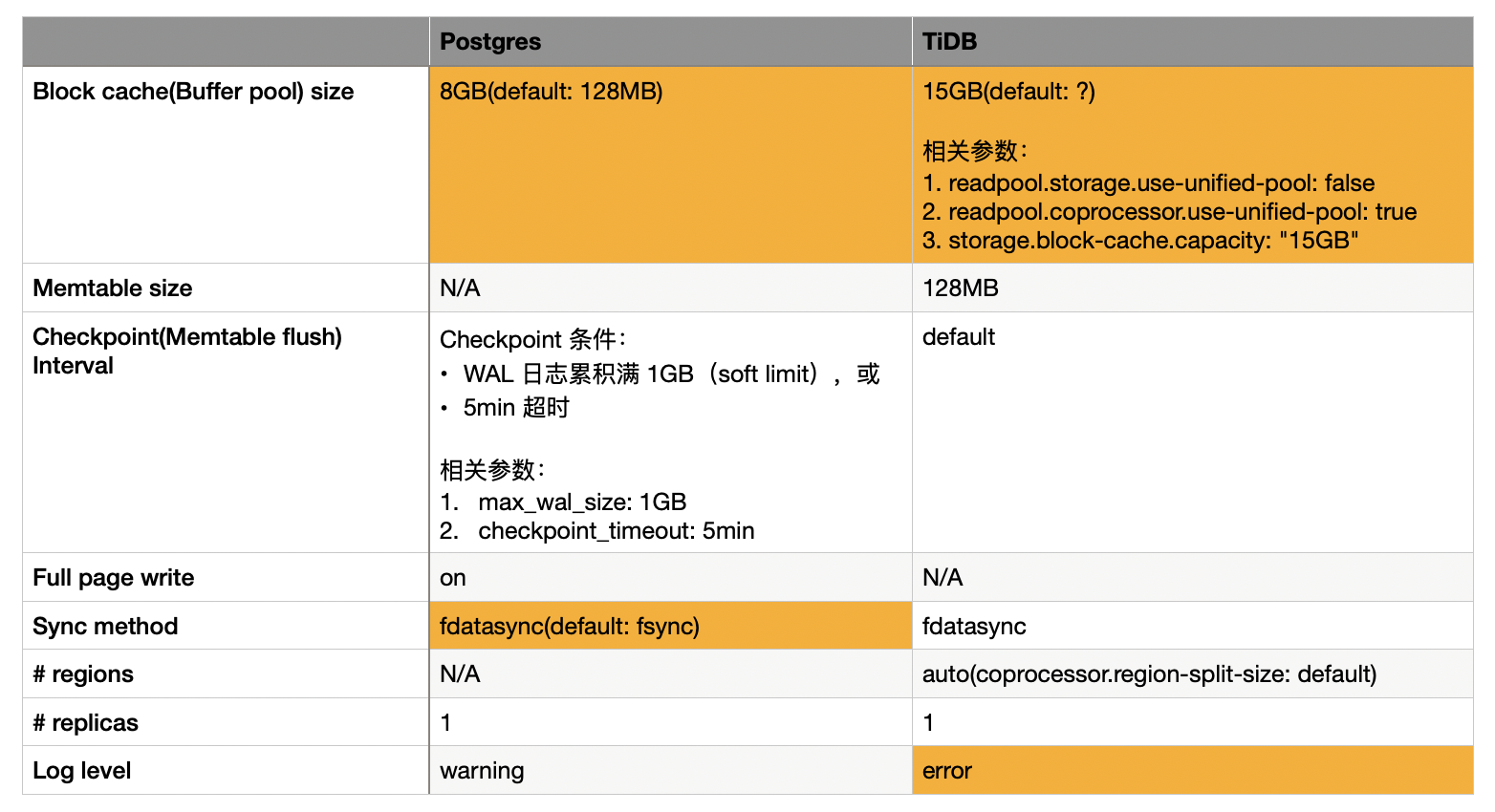 上图是未调优测试的关键参数。
上图是未调优测试的关键参数。
总体来看,除了个别参数(黄色背景)不得不调整,其余参数均使用默认值。
考虑到不了解这些参数的读者的阅读体验,我有必要在这里对这些参数解释一番。至于了解这些参数的读者,建议跳过这一部分,直接看下文的测试结果和归因。
Block cache size
- 在 Postgres 中,block cache 叫 buffer pool,用来实现 page(包括 data page 和 index page) 的 read cache 和 write buffer。除 buffer pool 外,Postgres 还会利用 OS page cache,它们合起来就组成了一个两级的 cache 结构。对于 index scan(随机读少量 page),会先从 buffer pool 读 page,如果 miss,再读 OS page cache;对于 table scan(顺序读大量 page),会绕过 buffer pool 直接读 OS page cache。不难看出,这种做法存在「双缓存」问题,即同一份数据可能在 OS page cache 和 buffer pool 中都缓存了一份。综合考虑,由于 table scan 依赖 OS page cache(尽管接下来的测试负载中没有 table scan,但我们以有 table scan 的生产环境为目标)以及双缓存问题,Postgres 的 buffer pool 不宜配置得过大,因此这里配置为机器总内存大小的 25%,即 8GB。
- 在 TiDB 中,block cache 仅用作 read cache。至于 write buffer,它由 memtable 来实现。由于 TiDB 与 Postgres 不同,TiDB 基于的 RocksDB 使用 Direct IO(O_DIRECT),它只使用自己的 block cache,不使用 OS page cache,因此它的 block cache 的大小可以配置得更大一些。我这里参考了官方的建议,配置为机器总内存大小的 45%,即 15GB。
Memtable size
- Memtable 仅与 TiDB 有关,因为 TiDB 的存储(RocksDB)是用 LSM-tree 实现的。本测试没有费心关注这个参数,直接使用了默认配置(128MB)。
Checkpoint Internval
- 在 Postgres 中,checkpoint 干的事就是周期性地把 buffer pool 中的 dirty page 刷盘。有了 checkpoint,日常的写入只写 buffer pool 中的 page 然后记录 WAL 日志就可以了,无需考虑刷盘。由于是周期性地刷盘,同一个 page 在单个周期内可能有多次更新,但只需要在 checkpiont 的时候刷一次盘,很明显 checkpoint 有均摊写放大的作用。这对数据基于 heap 表存储,索引基于 B-tree 存储的 Postgres 来说至关重要,因为 heap 表和 B-tree 在随机更新场景下的写放大都非常大。很容易得出结论,checkpoint 频率越低,Postgres 的写性能越好(代价是 recovery 变慢)。(补充:B-tree 随机更新的写放大无需多言。heap 表的写放大相比 B-tree 稍微好一点,因为 heap 表的 insert 可以粗略看做是 append 的(不考虑空间回收复用的话),update/delete 需要在目标 tuple 上打一个删除标记,这是随机更新的主力。)
- 在 TiDB 中,checkpoint 其实就是 memtable flush 了。flush 的频率同样影响 TiDB 的写放大。这里我没有费心去研究 TiDB 的 flush 频率的相关参数,我推测默认的行为应该是只有 memtable 写满了才会触发 flush。
Sync method
这个参数指的是刷盘操作使用的系统调用是用 fsync() 还是 fdatasync()。这两个的区别是,fsync 更安全但代价更大(fsync 刷盘不仅刷文件数据还会刷文件元数据,fdatasync 只刷文件数据)。fsync 是生产环境首选,理论上我们应该把两个数据库都配置为 fsync 再进行测试。然而由于 TiDB 仅支持 fdatasync(),所以我统一配置为 fdatasync() 来测试(感谢 Postgres,各种 sync method 都支持)。
Full page write
这个参数仅与 Postgres 有关,它是 Postgres 用来保证 crash safety 的一个重要功能。由于 Postgres 的存储结构是 in-place update 的,在刷盘的时候断电会有「partial write」问题,为了保证这种情况下不把 page 写坏,必要条件下刷盘前会先把 page 备份写入到 WAL 日志中,以供意外情况下恢复。虽然打开 full page write 会增加磁盘 IO 的开销,但为了安全,这个参数必须打开。
# regions
这个参数仅与 TiDB 有关,指的是 TiDB 数据分片的数目。TiDB 是分布式数据库,为了解决大数据量问题,需要支持数据分片,有了数据分片,就能做数据并行和灵活调度。数据分片带来的一个副作用是:跨多个分片的写入需要进行两阶段提交,相对于传统单机数据库的一阶段提交来说,会引入额外的 CPU 和磁盘 IO 开销。
# replicas
这个参数指的是数据库的副本数。由于我们是在单机环境进行测试,不考虑副本,因此 Postgres 和 TiDB 的副本数都被固定为 1。
Log level
这个参数见文知意,即日志的级别。这里提到这个参数是因为 TiDB 官方建议性能测试的时候将日志级别调整为 error。(没有自信在 warning 级别下测试吗?)
结果及归因
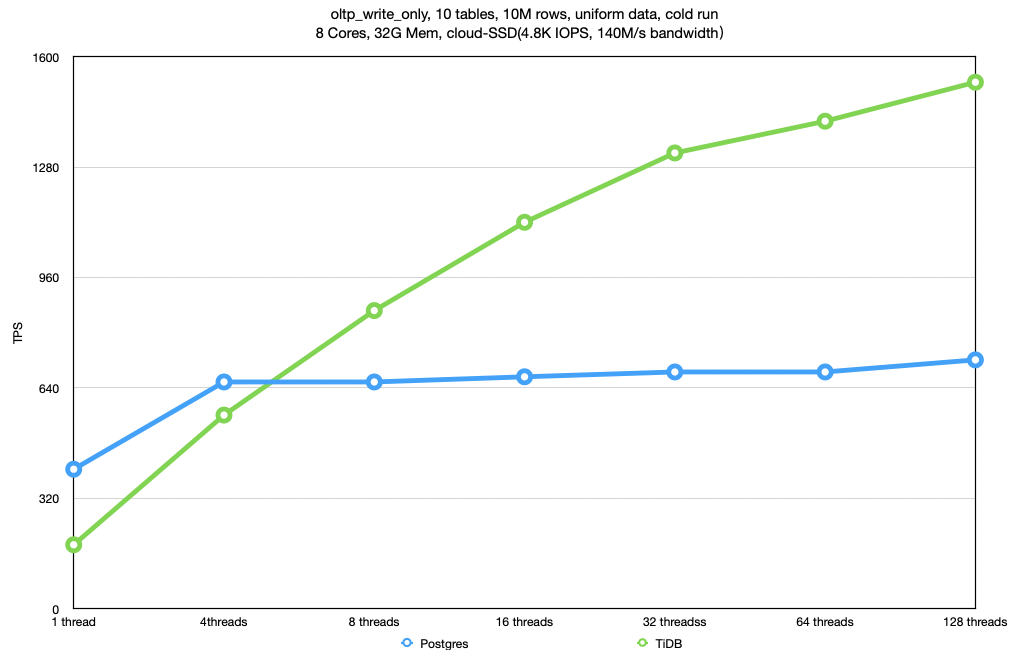
上图是 oltp_write_only 负载下的测试结果。
整体上看,TiDB 的表现是全程优于 Postgres 的,128 线程时甚至达到了 Postgres 的 2x。
我们先来分析下 Postgres。在这个负载下,Postgres 的性能瓶颈在磁盘带宽上。这是因为云硬盘的 IOPS 很高(4800),带宽比较小(仅 140MB),而默认的 checkpoint 频率比较高(WAL 日志量累积满 1GB 就触发),因此写放大比较大,很快就跑慢了磁盘带宽(4 线程就跑满了)。
然而图里面接下来出现了一个乍看比较吊诡的情况,Postgres 在 128 线程(及之后)出现了「回光返照」现象,原本看起来已经达到瓶颈的吞吐量开始大幅提升了。经过分析发现,这是由于 Postgres 的 checkpoint 频率自动降低所致。在高并发场景下,更新的 page 数量相对比较多,每次 checkpoint 都需要很久才能做完,规则上,只有前一个 checkpoint 做完了才能进行下一次 checkpoint(WAL 日志累积量满 1GB 是 soft limit,在这里失效了),因此在单位 checkpoint 耗时变长,总时间不变的情况下,checkpoint 的频率事实上降低了(实测速率大约等于 WAL 累积满 2GB 做一次 checkpoint),写入性能得到提升。
此外,上图还有一个让人意犹未尽的地方,Postgres 在 1024 线程的时候仍未显露颓势,似乎还能再上层楼,可惜的是,我尝试了一次 2048 线程的测试,Postgres 直接 OOM 了。OOM 的原因推测是因为 Postgres 是多进程模型,每个进程会分配一些私有的内存(e.g., per 进程的 syscache),进程数多的情况下就会出现内存爆炸。
再来分析一下 TiDB。TiDB 的 LSM-tree 在这个写入密集型负载下是如鱼得水。由于 LSM-tree 的写放大比较小,磁盘达不到瓶颈,瓶颈就出现在了 CPU 上。至于 CPU 上的具体开销占比,限于精力,我没有进一步地分析。
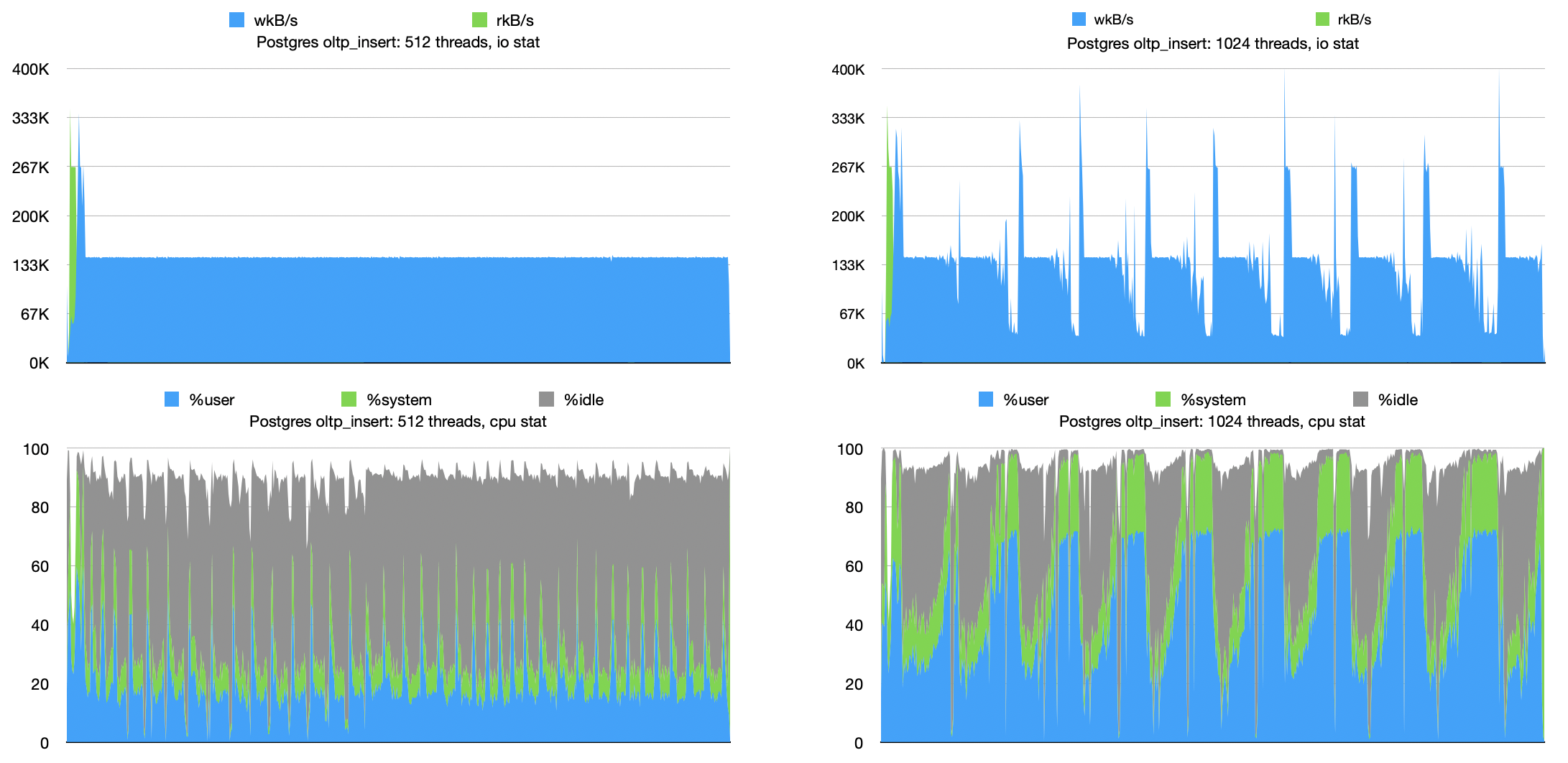
 上图是 oltp_insert 负载下的测试结果。(注:文末附有 oltp_insert 负载测试现场的 CPU 和磁盘 IO 监控图。)
上图是 oltp_insert 负载下的测试结果。(注:文末附有 oltp_insert 负载测试现场的 CPU 和磁盘 IO 监控图。)
整体上看,Postgres 的表现是优于 TiDB 的,尤其是在回光返照(与 oltp_write_only 测试同样的原因)后的 1024 线程,它们之间的差距达到了 2.5x 左右。
仍然先分析 Postgres。Postgres 在 oltp_insert 负载下的瓶颈和 oltp_write_only 负载下一样,都在写入带来的磁盘 IO 上。
或许你会有疑问?同样是瓶颈在磁盘 IO 上,为什么 oltp_write_only 负载下表现差于 TiDB,而 oltp_insert 负载下的性能却反超了 TiDB 呢?
这归功于 Postgres 的 heap 表。正如上文提到的,heap 表在 insert-only 情况下的写入是 append 的(没有 update/delete 随机更新以及空间回收复用),写放大非常小。这为 Postgres 反超 TiDB 创造了条件。
接下来,让我们再次分析TiDB,其性能瓶颈仍然在 CPU 上,与 oltp_write_only 负载下的情况相似。
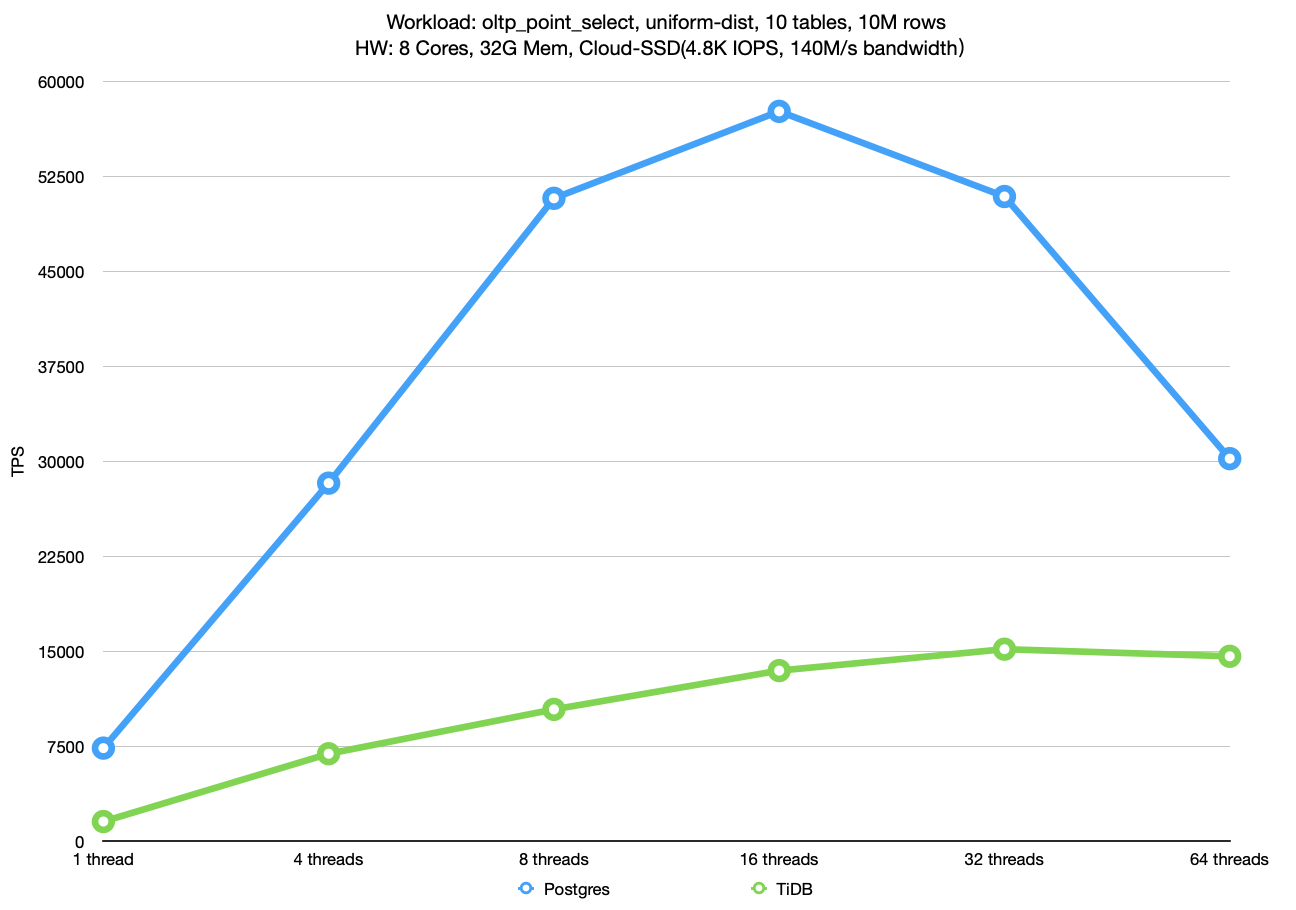 上图是 oltp_point_select 负载下的测试结果。
上图是 oltp_point_select 负载下的测试结果。
整体上看,这个负载下 Postgres 是全面吊打 TiDB 的,在 16 线程时差距达到最大,大约 3.5x。
无论是 Postgres 还是TiDB,性能瓶颈都在 CPU 上。尽管我们是 cold run 测试,在初始阶段可能涉及大量磁盘 IO 操作,但一旦负载运行一段时间,数据就会完全加载到内存中,导致磁盘 IO 会显著减少。因此,从较长时间的性能表现来看,瓶颈是出现在 CPU 上的。
ROUND 2: 调优后的测试
关键参数
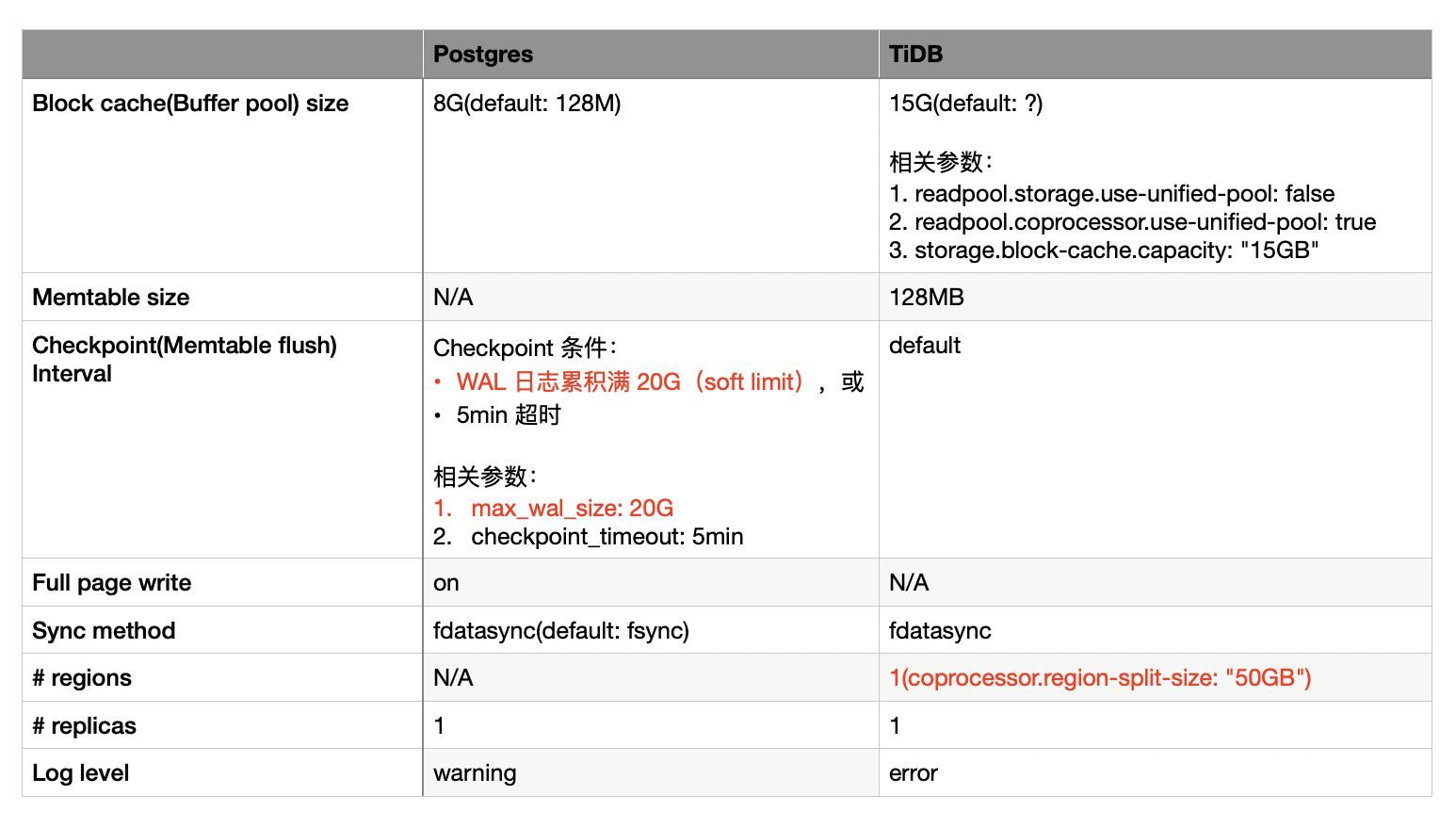 上图是调优后测试使用的所有参数,与未调优的版本相比,仅优化了两个参数:
上图是调优后测试使用的所有参数,与未调优的版本相比,仅优化了两个参数:
- 针对 Postgres,我们将 max_wal_size 从 1G 增大到 20G(WAL 日志量满 20GB 触发 checkpoint),从而降低了 checkpoint 的频率。由于我们的测试数据集总共就 20GB 多,在测试跑 10 分钟,且 checkpoint timeout 是 5min 的情况下,预计 checkpoint 只会触发 1 次(没实地确认,仅凭推测)。之所以调优这个参数,是想看看 Postgres 在牺牲一点 recovery 性能的情况下的性能表现如何。
- 针对 TiDB,我们将 coprocessor.region-split-size 增大到 50GB。这确保了 TiDB 中只会有一个 region。因为我们的数据集的大小仅为 20GB 多,不会触发 region split 生成新的 region。之所以调优这个参数,是因为我们是在单机环境下测试,两阶段提交是不需要的,因此需要干掉,这样能公平一些。
结果及归因
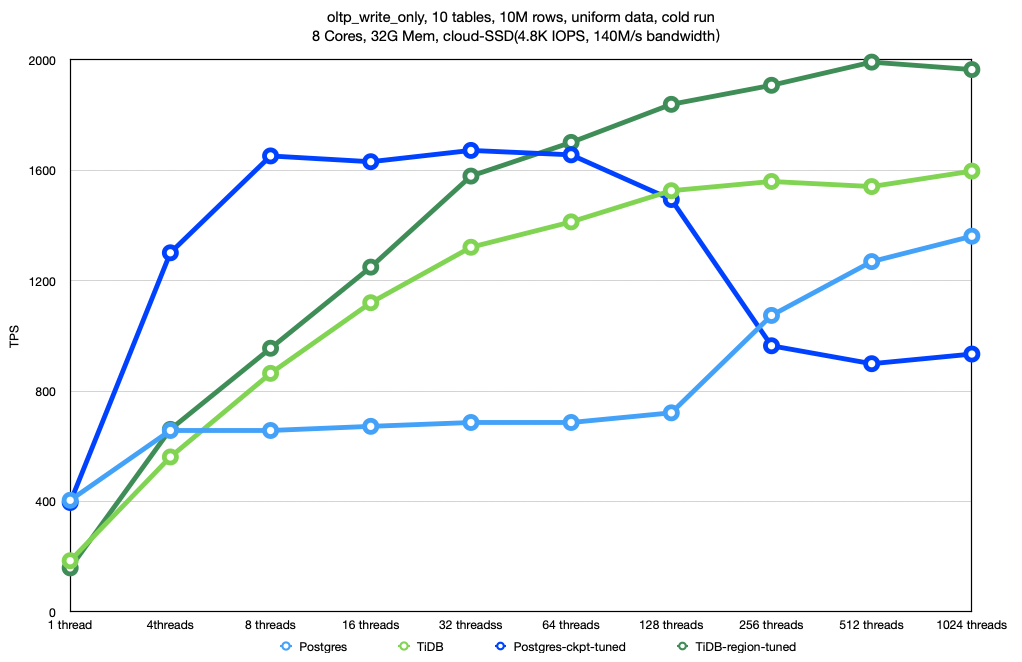
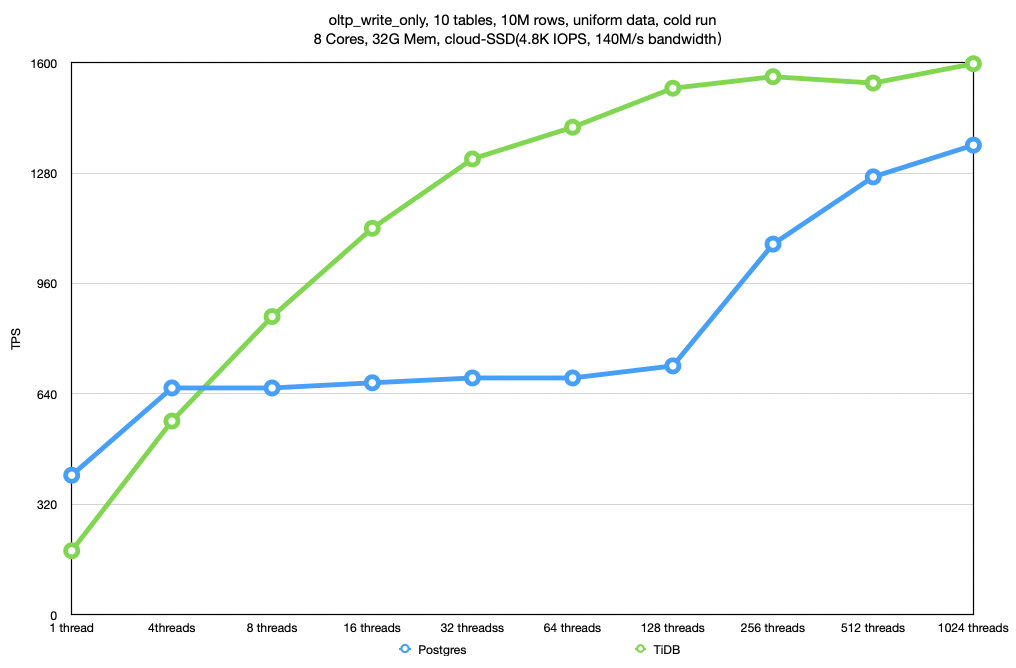
上图是 oltp_write_only 负载下的测试结果。我在未调优版本的图上加上了调优后的测试结果。Postgres 调优后的名称叫 Postgres-ckpt-tuned(ckpt 是 checkpoint 的缩写),TiDB 调优后的名称叫 TiDB-region-tuned,它们都是用更深颜色的曲线表示,寓意「深度」调优。
整体上看,Postgres 和 TiDB 调优后的性能都有所提升。值得注意的是,TiDB 的表现仍然优于 Postgres:Postgres 的峰值 TPS 大约在 1600,TiDB 的峰值 TPS 在 2000。
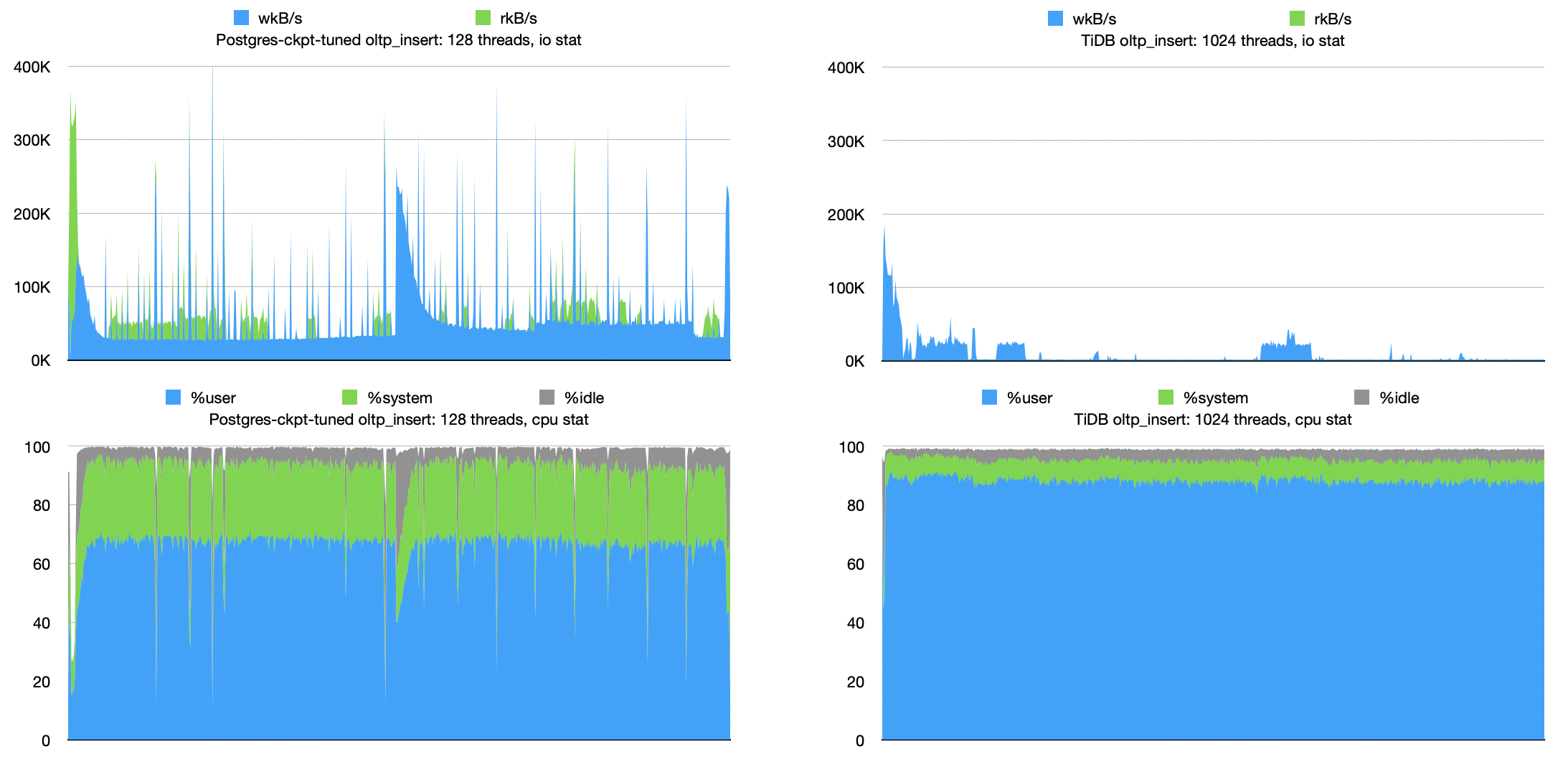
Postgres 调优后,性能瓶颈从磁盘 IO 转移到了 CPU。比较符合 checkpoint 频率降低,磁盘 IO 减少的预期。
TiDB 的性能瓶颈并没有发生变化,瓶颈仍然在 CPU 上。由于没有了两阶段提交,CPU 和磁盘 IO 同时得到优化,性能得到一些提升。
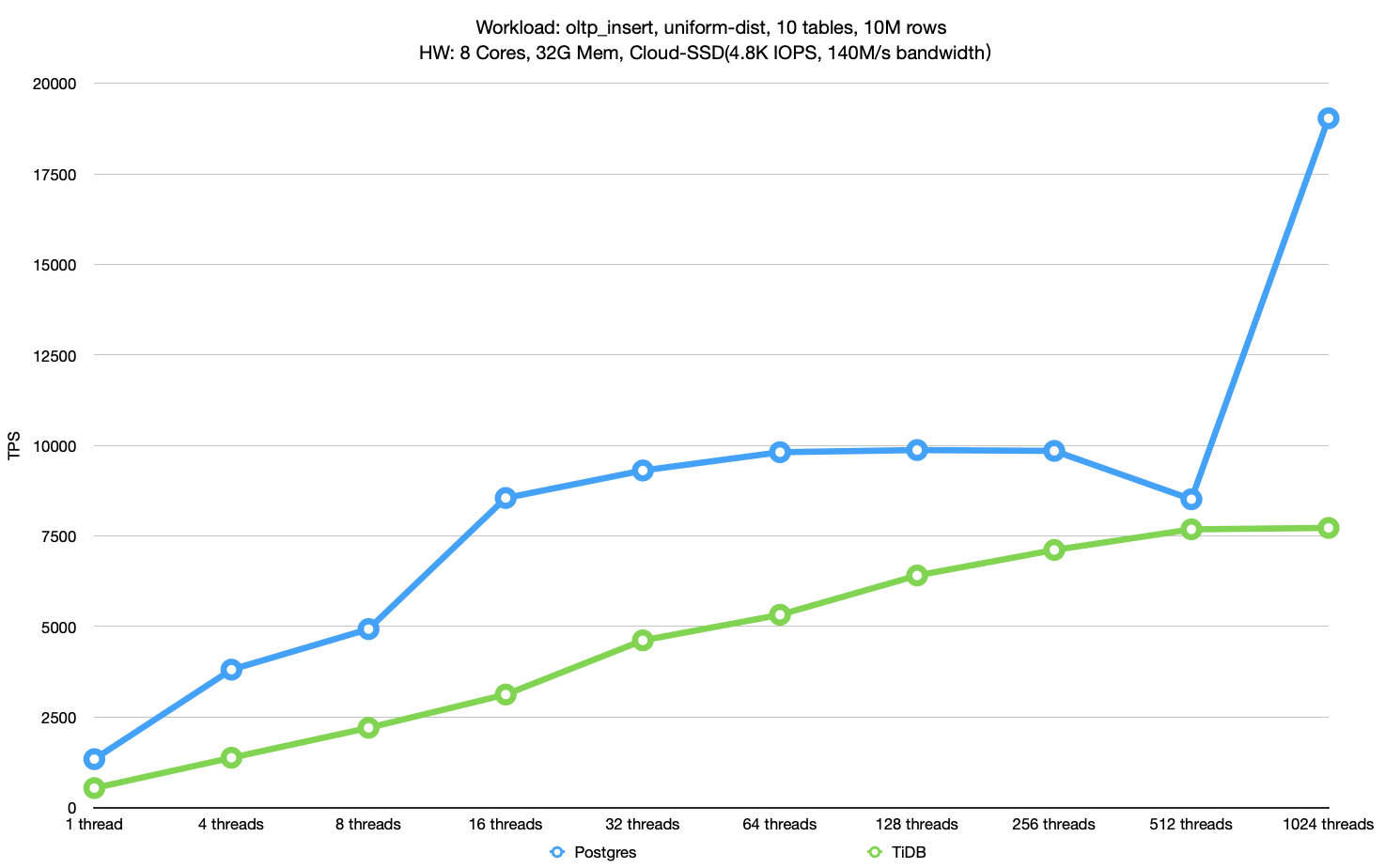
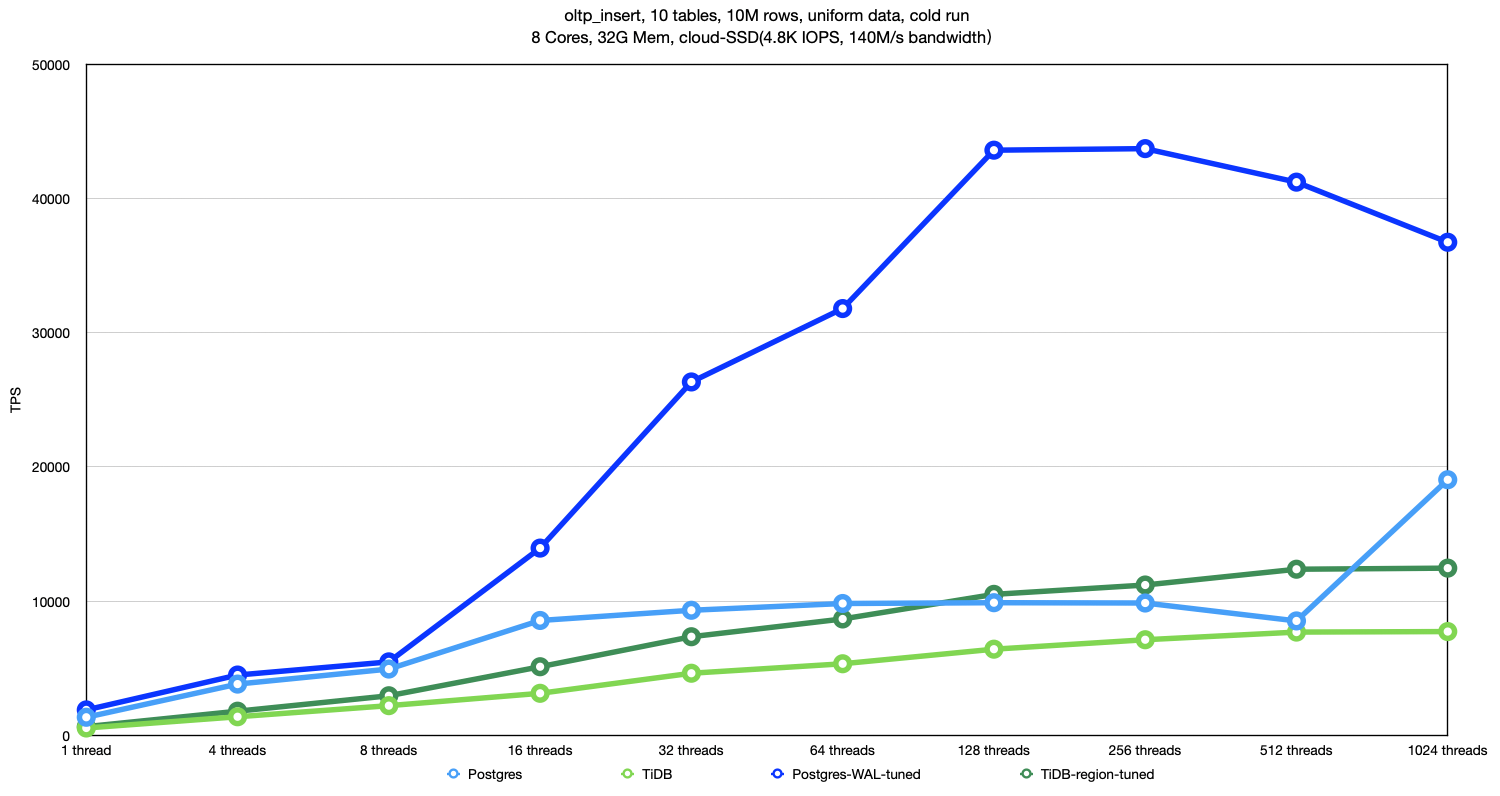 上图是 oltp_insert 负载下的测试结果。同样在未调优版本的图上加上了调优后的测试结果。
上图是 oltp_insert 负载下的测试结果。同样在未调优版本的图上加上了调优后的测试结果。
整体上看,Postgres 和 TiDB 调优后的性能都有所提升,特别是 Postgres 的性能甚至能达到调优前的 4x 多。与TiDB相比,可以说 Postgres 的性能有着明显优势。
这两个数据库在 oltp_insert 负载下的性能瓶颈和 oltp_write_only 负载下相同,因为原理类似,所以不再进行详细解释。
最后提一下,olto_point_select 没有在调优后进行测试,这是因为 oltp_point_select 没有写入,与 checkpoint 无关,与两阶段提交无关,不会受到调优的影响。
总结以上所有的测试,我们可以发现,TiDB 在 oltp_write_only 的负载下表现得比较好,而 Postgres 在 oltp_insert,oltp_point_select 的负载下表现得比较好,完全可以说它们二者是互有胜负的。
总结
本文为了澄清网络上传统数据库性能全方位击败分布式数据库的「谣言」,挑选了传统数据库的代表 Postgres 和分布式数据库的代表 TiDB 做了一系列的性能测试,得出了传统数据库和分布式数据库在性能上互有胜负,而不是一边倒的结论,为我们还原了事情的真相。
话虽如此,我们却不能忽视一个事实,尽管并不是一边倒,但在许多负载下,分布式数据库与传统数据库仍有差距。为了填补这些差距,我们大家(同行们)需要共同努力。既然 TiDB 这一「钛制的栏杆」已经有能力在某些情况下绊倒「大象」(大象是 Postgres 的 logo)了,那我们何不一起努力再加把劲,抄上我们各自的家伙,把大象绊一个象啃泥呢?
广告时间
欢迎大家关注我的知乎和微信公众号,搜索:黄金架构师。
附录
附上 oltp_insert 负载性能测试现场的监控。
留下评论