
Postgres Blink-tree 的工程实现
Postgres Blink-tree 的实现参考了三篇论文:
- 论文 1:《Efficient Locking for Concurrent Operations on B-Trees》—— Blink-tree 的原始论文,但仅提出了 insert 的实现方案。
- 论文 2:《A symmetric concurrent B-tree algorithm》—— 原始论文的补充,提出了 Blink-tree delete 的实现方案。
- 论文 3:《Prefix B-tree》—— B-tree 前缀压缩论文。
尽管这几篇论文的 idea 都非常出色,但在工程实现时,仍需摒弃一些不切实际的假设,并针对现实场景进行专门的设计和优化。
本文将介绍 Postgres 中 Blink-tree 的工程实现,重点关注其与上述论文的差异之处,供读者参考。本文假设读者对 Postgres 和 Blink-tree 有一些基本的了解。
读锁
论文 1 宣称 Blink-tree 不需要加 page 的读锁,只需要加写锁;而 Postgres 却引入了读锁。
说明:B-tree 的「结点」和「page」这两个术语在本文中是互换使用的。
在传统 B-tree 中,page 读锁有两个用途:
- 保证原子性读取:通过持有读锁确保读取 page 不受并发写的干扰。
- 确保子结点指针有效性:在下降(descend)过程中,确保从父结点读到的子结点指针(在 Postgres 中称为 downlink)始终有效。具体来说,防止在读取 downlink 后、下降到子结点之前,子结点被并发线程写满并触发 page split,导致其部分数据右移,从而使得继续读取原来的子结点时可能读不到数据出错。通过 lock-coupling 加锁方式 —— 在加上子结点读锁后才释放父结点读锁 —— 可确保子结点指针的有效性(同时要求 split 操作必须先持有父结点的写锁)。
而在 Blink-tree 中,high-key 和 right-link 的重定向机制已经满足了用途 2。至于用途 1,论文 1 基于一个假设来满足 —— 假设内存 page 在线程间不共享,可以无锁原子地读取。
原文描述如下:
Each process can examine or modify data only by reading those data from the disk into its private primary store (the “memory”). To alter data on the disk, the process must write the data to the disk from its memory.
然而,这个假设在实际环境中并不现实 —— 每个线程各自维护一份 page 的拷贝会极大地浪费内存。因此,Postgres 引入了线程间共享的 buffer pool 来管理这些 page。既然 page 是共享的,那么就必须加读锁以保证原子读取。
Postgres 的 page 读锁仅在读 page 期间短暂持有,读完立即释放,不涉及 lock-coupling,因此引入的性能开销可以接受。(为了区分 lock-coupling,下文将这种读锁称为短读锁。同理,也存在短写锁。)
写锁
论文 1 提到 Blink-tree 同一时刻最多持有三把 page 写锁,而在 Postgres 中最多持有两把写锁。
持有锁最多的情况出现在特殊的 page split 场景。在了解这个场景之前,我们先简单介绍一下 split 流程。
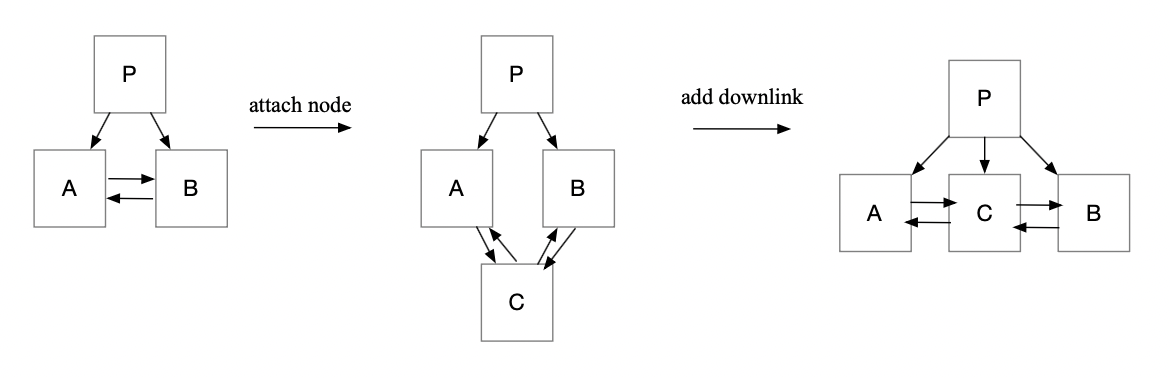
注意:为了支持从右往左的扫描,Postgres 为结点增加了指向左兄弟的 left-link,上图已绘出。
如上图所示,split 分为两个阶段:
- 链接新结点:将 split 结点 A 的新右兄弟结点 C 构造出来,并链接到 A 和 B 之间。(加锁顺序:先锁定 A 和 B,修改 B 的 left-link 后释放 B。)
- 添加 downlink:在父结点 P 上添加 C 的 downlink。(加锁顺序:在持有 A 锁的情况下,加锁 P,加上后立即释放 A。)
这两个阶段的任一阶段同一时刻最多持有两把写锁。注意,如果父结点被第二阶段写满触发 split,还需要递归向上处理。
更复杂的情况是在第一阶段完成后、第二阶段开始前,父结点 P 被并发线程写满触发 split,导致父结点右移。这种情况下第二阶段就需要在父结点层向右查找真实的父结点。
查找过程对应论文 1 中的 move-right 代码:
 可以看到,move-right 的加锁方式采用了 lock-coupling。因此,论文 1 中 Blink-tree 同一时刻最多持有三把写锁:split 结点、父结点和父结点右兄弟的锁。
可以看到,move-right 的加锁方式采用了 lock-coupling。因此,论文 1 中 Blink-tree 同一时刻最多持有三把写锁:split 结点、父结点和父结点右兄弟的锁。
然而,实际上 move-right 只需要短写锁,不需要 lock-coupling。因为我们的目的是在父结点层找到一个 downlink 的插入位置,满足 key_i <= key_downlink < k_(i+1),而无论 key_i 和 key_(i+1) 是在同一个结点上,还是分别在两个相邻结点上(key_i 是 high key),通过短写锁都能找到正确的 downlink 插入位置。
因此,Postgres 中父结点层的 move-right 就采用了短写锁(代码在 bt_getstackbuf())。split 过程同一时刻最多持有两把写锁——split 结点和父结点的锁。
对这个话题感兴趣的读者也可以看看 Postgres 社区中对 Blink-tree lock-coupling 的讨论:Why does L&Y Blink Tree need lock coupling?。
split 的 crash consistency
论文 1 并没有讨论 split 的 crash consistency,而作为工业界数据库, Postgres 必须考虑这一点,以确保用户数据的持久性。
假设 split 执行到一半时系统突然 crash,会发生什么?例如,第一阶段完成后、第二阶段开始前 crash 了,如何保证系统恢复后的一致性?
一种 naive 的方案是在 split 期间始终持有 split 结点的写锁(无论 split 是否需要递归上升),直到 split 完成时持久化一条涉及多层多结点的日志。这条日志用于在系统恢复时重做 split。然而,这种方案缺点很明显 —— 锁的持有时间太长,并发度不高。
我们观察到,如果 split 过程只在完成时记录一条日志,那么 split 结点的锁不能提前释放,否则可能会出现 split 结点的日志顺序与实际写操作的顺序不一致 —— 先 split,然后释放 split 结点的锁,接着 split 结点被并发线程插入数据并写日志,最后 split 完成再写 split 日志。在这种情况下,如果系统恢复时按照这种乱序的日志重做,数据将会被写坏。
为了提升并发度,Postgres 选择在 split 的每个阶段各写一条日志(也可看做每层一条日志,在递归上升的场景中),以便提前释放 split 结点的锁。
然而,这仍需考虑 crash 场景:假设第一条日志持久化后、第二条日志写就 crash 了,系统恢复时只会重做第一条日志,导致 split 结点的右兄弟缺少 downlink。尽管这不影响正确性,但仍会影响性能。
为解决这个问题,Postgres 进一步的方案是:split 的第一阶段在 split 结点打上一个 incomplete-split 标记;第二阶段完成时清除这个标记。如果第二阶段开始前就 crash,系统恢复时先不处理,等到后续的读写操作遇到这种带 incomplete-split 标记的结点,就帮助其完成第二阶段。这样,就确保了 split 的 crash consistency。
删除 KV
在论文 2 中,Blink-tree 的删除是物理删除——直接从 page 上移除 KV。然而,在 Postgres 中,由于 MVCC 的实现方式,B-tree index 的删除是逻辑删除——仅在 heap 表的 tuple 上打上标记以表示删除。更新操作也是先进行逻辑删除,然后再向 B-tree index 插入一条新版本的 KV。
在这种方案下,B-tree index 的删除和更新会保留大量的无效版本,并且所有版本都需要回表检查有效性,以过滤掉已删除的数据。这会导致索引空间膨胀和性能下降,因此有必要尽早物理删除无效的版本,以保证存储空间和性能的稳定。
Postgres 的物理删除方式总共有三种。第一种是 simple deletion —— 一种机会性的删除方式。它由 index scan 触发,对 scan 范围内 KV 进行机会性删除。因为 index scan 会先访问 index, 然后再访问 heap 表,所以在访问 heap 表后,可以将有效性信息回馈给 index,并在 index 的无效版本上打上标记。后续在 page split 时,可以批量物理删除这些无效版本,以避免 split。
第二种是 bottom-up deletion —— 一种启发式的删除方式。在非索引列更新导致 page split 时触发。因为非索引列更新插入的新版本和老版本的 key 相同,通常在同一个 page 上,基于此我们就可以假设该 page 上可能存在很多无效版本。在这种情况发生时,Postgres 会根据启发式算法在这个 page 上选择适量的版本回表检查有效性,然后物理删除无效版本以避免 split。由于回表会引入 heap page 访问开销,Postgres 会限制访问的 heap page 数量,同时利用空间局部性(优先访问 page 上版本数量多的以及邻近的 page)和预读优化,以减小访问开销。社区有关 Bottom-up deletion 的讨论 —— Deleting older versions in unique indexes to avoid page splits 中给出的一个场景提升了 1.7x 的 throughput。
第三种是 vacuum —— 一种阈值触发的全表扫描删除。当统计到删除和更新数量达到特定阈值时触发 vacuum。先扫描 heap 表数据并找到无效的 tuple,然后批量去 B-tree index 做物理删除。这里对 index 也是顺序扫描文件,从而提升读取吞吐量。
避免版本过多另一个优化手段 —— HOT(heap only tuple):如果非索引列更新涉及的新老版本在同一个 heap page 内,那么就不会向 B-tree index 插入新版本,直接使用老版本即可。因为可以根据老板本 KV 读到老版本 heap tuple,然后通过老版本 heap tuple 上指向新版本 heap tuple 的指针,找到同一个 page 内的新版本。
为什么前提条件限制两个版本必须在同一个 heap page 内?因为如果不在,读取会引入两次 heap page IO —— 先读老版本所在 page,再读新版本所在 page。相较而言,不使用 HOT 优化,根据 index KV 直接定位到新版本 heap tuple 所在的 page,只需要一次 heap page IO。
删除 page
在论文 2 中, Blink-tree 在 page 上的数据删除到一定量时会触发 merge。
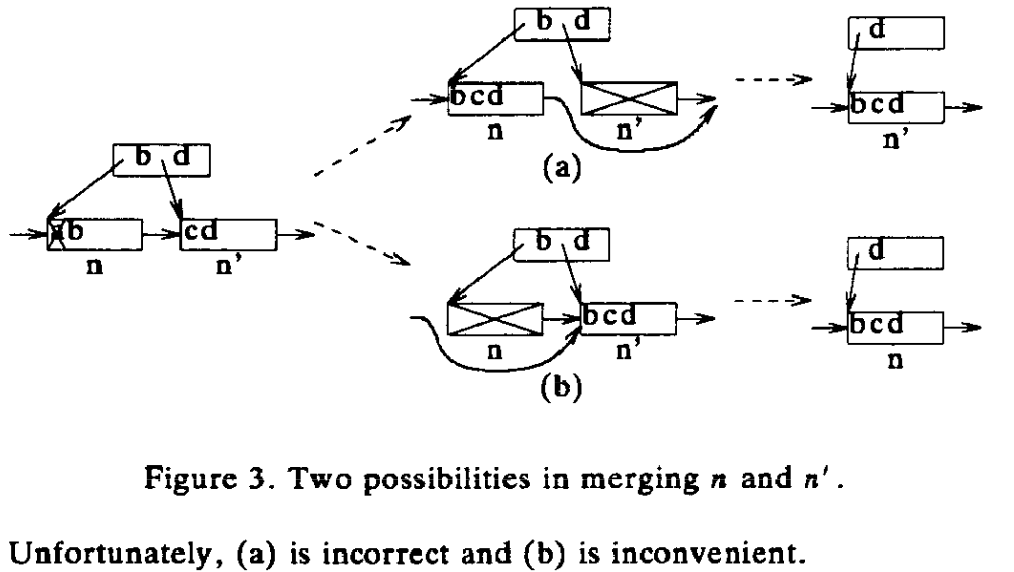 论文 2 提到的两种 merge 方案如上图所示:
论文 2 提到的两种 merge 方案如上图所示:
- 3.a 把右边的 n’ 合并到往左边的 n。这个方案存在不一致的中间状态 —— b 的 downlink 指向了 n’,然而大于 b 的数据 —— c 和 d —— 却在 n 上,这不符合 B-tree 的定义。
- 3.b 把左边的 n 合并到右边的 n’。论文 2 认为这个方案 inconvenient,因为需要给结点添加一个 left-link,以找到 n 的左兄弟并更新其 right link。
因此,论文 2 主张采用 3.a 方案。
为了在方案 3.a 中解决数据不一致的问题,论文 2 还在结点上添加了一个 outlink 指针,用于在结点 merge 时指向其左兄弟。
 最终的 merge 流程如上图所示,与 split 一样,是一个两阶段的过程:
最终的 merge 流程如上图所示,与 split 一样,是一个两阶段的过程:
- 第一阶段(half-merge):先将 n’ 的数据移动到 n,并更新 n 的 right-link 以指向 n’ 的右兄弟,然后将 n’ 的 outlink 指向 n。此阶段完成后,n’ 成为一个空结点,仅起重定向作用。
- 第二阶段(remove-link):在父结点上删除 n’ 的 downlink。此阶段完成后,n’ 从 Blink-tree 中分离,但不能立即回收,回收相关话题会在下文单独讨论。
与论文 2 不同,Postgres 为方便从右往左 scan 为结点引入了 left-link,实现方案 3.b 更简单方便,因此便采用了方案 3.b。此外,Postgres 不支持 merge 非空 page,仅支持把 page 上的数据删空,然后再删除空 page。因为 merge 过程需要将数据移动到左边或右边结点,并发的 scan 操作很难保证数据不遗漏。
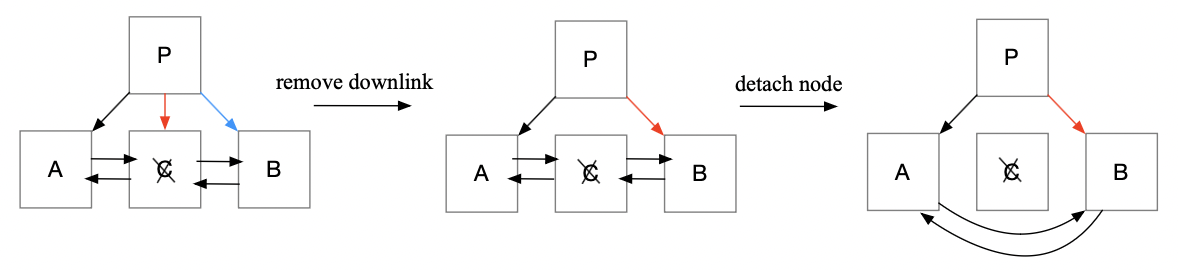 Postgres 删除 page 的流程如上图所示:、
Postgres 删除 page 的流程如上图所示:、
- 第一阶段(half-dead):逻辑上是删除结点 C 的 downlink,实际操作是将结点 C 的 downlink 指向右边的兄弟结点 B,同时删除结点 B 原来的 downlink。这样无论是结点 A 还是 B 都无需更新 high key。(加锁顺序:先加 C 锁,再加 P 锁。)
- 第二阶段:将结点 C 从结点 A 和 B 之间除去。(加锁顺序:先释放 A 锁,再按照 A、C、B 从左到右的顺序加锁,代码在 bt_unlink_halfdead_page()。)
Postgres 的方案有一个限制:最右子结点不支持删除,除非它是父结点的唯一子结点。因为最右子结点的右边是表兄弟结点,如果使用上述算法将父结点上的 downlink 指向表兄弟结点,父结点的 key 范围会改变,还需要递归向上处理祖先结点。因为实现多结点更新的原子性很困难,所以就不支持删除最右子结点。
回收 page
page 删除后不能立刻回收复用,因为可能存在并发线程正在访问它。这些线程可能刚从父结点离开,或者刚从左兄弟或右兄弟离开,仍需访问已删除的 page 以重定向到正确的 page。如果 page 立刻被回收复用,并且数据被重写,其他线程会访问出错。
Postgres 和论文 2 一样,在回收 page 这一点上,采用了解耦合的方案 —— 将删除和回收复用分开处理。它们总体流程上没有什么大的不同。
具体到实现上,Postgres 在删除 page 时,会在 page 上记录活跃事务的水位线(实际上是 Postgres 中下一个要分配的事务 ID)。当水位线以下的所有活跃事务都提交后,该 page 才允许被回收。至于真正的回收则是在后续的 vacuum 过程中进行,该过程会遍历并回收所有可以回收的 page。
scan 和 split
论文 1 没有描述如何实现 scan 和 split 的并发。
scan 的要求是读到的数据不重不漏,同时加锁开销要小。为了减少加锁开销,首选方案是 page 短读锁,而非 lock-coupling。此外,频繁加锁的开销不可忽视,最好的方法是对 page 加一次锁,然后将所有数据拷贝到私有内存中处理,即对 page 内容做一次快照。这样做足够保证正确性,因为即便后续这个 page 的 key 范围内有新增数据,读不到也不违反任何隔离级别。 因此,Postgres 便采用了这种实现方式。
对于从左往右的 scan,读数据时会获取 right-link 的快照,下一次读取时直接读 right-link 指向的右兄弟即可。即便刚读完的结点发生了 split,也只会影响到这个右兄弟的左边,我们不会读到重复的数据。
对于从右往左的 scan,读数据时会获取 left-link 的快照。然而,下一次读取直接读 left-link 指向的左兄弟是不对的,因为可能漏掉数据 —— 左兄弟在我们拿到 left-link 快照后发生了 split,一些数据被右移。因此,在读取左兄弟时,需要检查左兄弟的 left-link 是否仍然指向我们刚读过的结点。如果不是,需要向右查找满足这一要求的结点,然后从那个结点开始读取。
通过这些办法,Postgres 即确保了 scan 的并发正确性,又最小化了加锁开销。
压缩
为节省空间和提升性能,Postgres 支持去重压缩(deduplication),我在很久以前写的一篇文章—— 《B-tree 压缩技术介绍(Oracle,MySQL,PG…》 曾经介绍过这个技术,本文不再赘述。
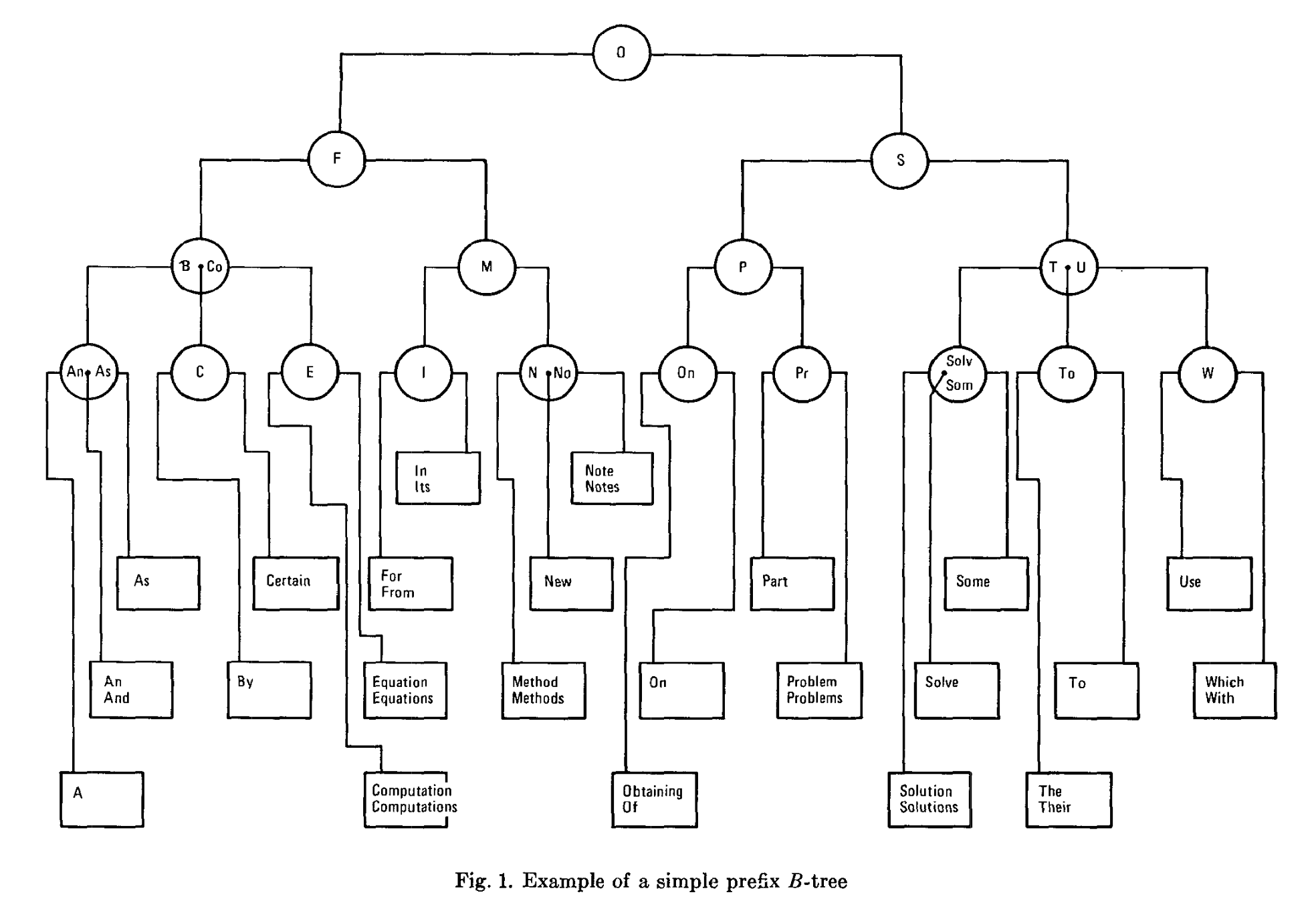 除了去重压缩,Postgres 还参考论文 3 实现了 simple prefix B-tree。
除了去重压缩,Postgres 还参考论文 3 实现了 simple prefix B-tree。
简单来说,simple prefix B-tree 就是内部结点不存储完整的 key,只存储 key 的最短前缀,要求前缀足够区分不同子结点的 key 范围就行。在 Postgres 中,这项技术被叫做 suffix truncation。
suffix truncation 的一个好处是通过减小内部节点的 key 大小,增加了内部结点的 fan-out,减小了 B-tree 的高度。不过这对存储空间的帮助微乎其微,因为通常内部节点仅占 B-tree 空间的 1%。
另一个好处是 split 分割点的选择更加灵活,有助于更好的分割叶子结点,从而切实地节省存储空间。
第二个好处有点难理解,我们举个例子来说明。假设现在有一个两列组成的联合索引,类型是 (char, char),每列的值域是 a~z 范围内的 26 个字母。它的一个叶子结点上有 (a, a), (a, b), (b, m), (b, n) 四条数据,如果选择 (b, m) 作为分割点来 split,那么 split 后左结点的范围是 (a, a~z) ∪ (b, a~l),右结点的范围是 (b, m~z)。相较而言,如果仅按照前缀 (b) 来分割,左结点的范围是 (a, a~z),右结点的范围是 (b, a~z)。显然,使用前缀分割在值域上会更均匀一些。这对随机插入的场景会有一定的帮助。社区的讨论 —— Why B-Tree suffix truncation matters? 给出的一个例子节省了约 14% 的存储空间。
写在最后
这篇文章是我从四年前的笔记中提取并整理出来的。由于最近换了工作,今后一段时间可能不会有很多的精力在 B-tree 上,所以我决定把以前的一些相关内容逐步整理发布出来,避免它们仅仅停留在我的笔记本中,成为未被利用的「熵」,而不是我和读者之间共享的知识。
希望本文能帮助读者更好地了解 Postgres 和 Blink-tree。
参考
- 开头提及的 Blink-tree 几篇论文。
- Postgres 源码文档等相关资料。
留下评论