
列存高效更新技术介绍
列存具有「读友好,写不友好」的特点。这个特点使列存和 AP 数据库仿佛王八看绿豆一样 —— 对上眼了。因为 AP 数据库正好重视读性能(大查询吞吐量),不重视写性能(能容忍 T+1h/1d 更新)。 于是,列存顺理成章地霸占了 AP 数据库的存储底座。
近年来,随着业务的发展,越来越多的业务场景霸道地要求 AP 数据库必须具备实时分析能力。为此,AP 数据库必须把上游 TP 数据库产生的写入和更新实时地导入进来。这对 AP 数据库的列存更新效率制造了新的挑战。
本文将介绍迎接这个挑战诞生的列存高效更新技术。探讨内容包括:
- 列存更新的难点。
- 一种低效更新方案。
- 四类高效更新方案,并介绍这些方案在业界数据库中的实现。涉及数据库包括 Iceberg,Hudi,Kudu,Doris,ADB,Hologres 等。
- 比较总结所有方案。
希望本文能对读者了解列存更新技术有所帮助。
列存更新的难点
我认为主要面临两个难点:一个是写放大,另一个是无法简单地做 in-place update。

首先这里的写放大特指 IO 次数的放大,具体来说:
- 传统列存(每列一个文件):写入需要每列一次磁盘 IO。尽管可以通过攒批来均摊开销,但大宽表(成百上千列)场景仍然力不从心。
- 行列混存(PAX 格式):文件被切分成很多 block,一行的所有列数据按列存格式塞到同一个 block 里面。写入需要在内存中攒满一个列存 block,然后以 block 为单位压缩并刷盘。所有列一次 IO 搞定。尽管这种做法优化了磁盘 IO 次数,但在内存 IO 次数方面还是有放大,因为内存 block 不是行存。
下文所有数据库的列存格式均属于行列混存。
其次是无法简单地做 in-place update。原因有二:
- 容易造成比较大的写放大。列存的 block 非常大,因为面向读场景优化,追求高压缩率。哪怕是 in-place update 一个 field,也有可能导致大 block 内数据的 reorganize。重写大 block 会带来比较大的写放大。
- 最致命的,AP 数据库的趋势都是 share-storage 架构,基于 HDFS/S3。这类分布式存储本身就不支持 in-place update。所以没得选了,只能做 out-of-place update。
下文所有列存更新技术均属于 out-of-place update。
低效更新技术
想了解什么是高效更新技术,必须先了解什么是低效更新技术。 —— 黄金架构师(知乎和公众号同名)
最简单的 out-of-place update 方案是 file-level COW(copy-on-write) 。这种方案简单来说就是更新时无论更新一行还是一批,都直接把原文件拷贝出来更新,然后生成一个新文件。
File-level COW 方案在业界的典型代表是 Hudi COW 表。
 Hudi COW 表的实现概述如下:
Hudi COW 表的实现概述如下:
- 宏观上看,一张表的数据存储在 HDFS/S3 上的很多列存文件中。
- 更新时重写整个列存文件。因为要做写写冲突检测(ww-conflict check;为实现 snapshot isolation),更新需要保证可串行化。Hudi COW 通过 file-level 乐观锁来保证这一点。更新文件期间不加锁,commit 时检查有没有并发写事务抢先更新了相同的文件,如果有,那么自己就 abort。换句话说,不支持对同一文件的并发更新。
- 读取时,按快照选取适当版本的文件。
这个方案的优点是读性能非常棒,文件级别多版本使得读完全不受写的影响。缺点是写性能很差,因为写放大很大,并且写并发度低。
显然,file-level COW 是一种低效更新方案。如果用这个方案来应对实时场景,那无异于以卵击石。
到现在为止,我们已经具备了低效更新技术的认知。那么,接下来我们就可以往高效更新技术的殿堂进发了。
高效更新技术
我们可以思考一下,要想高效,应该做好哪些事情?我认为,主要是两件事情:
- 降低写放大,提升写并发。单线程性能靠降低写放大来优化,多线程性能靠提升写并发来优化。单线程和多线程都在手,性能我有。
- 尽量少损害读性能。毕竟咱是 AP 数据库,读性能至关重要,还要靠它来吃饭。
为了做好这两件事情,我们应该追求:
- 更细粒度的更新。Hudi COW 拷贝更新整个文件算是 file-level update。如果我们能做到 block-level,tuple-level,甚至是 field-level,写放大会显著优化。
- 更细粒度的并发。Hudi COW 加 file-level 的锁,算是 file-level concurrency。如果我们能做到 block-level,tuple-level,写并发会显著提升。(没有 filed-level,复杂且开销不一定小)。当然我们也要清醒地认识到,细粒度的并发需要细粒度的锁,细粒度的锁对于批量更新没有那么友好(想象一下更新整张表的数据,为每一行加一个行锁)。因此这里存在一些取舍的空间。
上述思考很有意思。我运用这个思考框架,再结合业界数据库的实际情况,把业界数据库的高效更新方案按照写并发和更新粒度分成了四类,分别是:
- Table-level concurrency + tuple-level update.
- File-level concurrency + tuple-level update.
- Tuple-level concurrency + field-level update.
- Unlimited concurrency + tuple-level update. (Unlimited concurrency 看起来非常唬人,其含义我们下文再细说。)
这四类方案在各家数据库中都是怎么实现的呢?接下来我们挨个分析一下具体的案例。
Table-level concurrency + tuple-level update
这类方案的典型代表是 Iceberg MOR 表。
使用这类方案的数据库绝对地重视批量更新,轻视并发更新和单行更新,因此更新通过表锁来实现,仅支持 table-level concurrency。
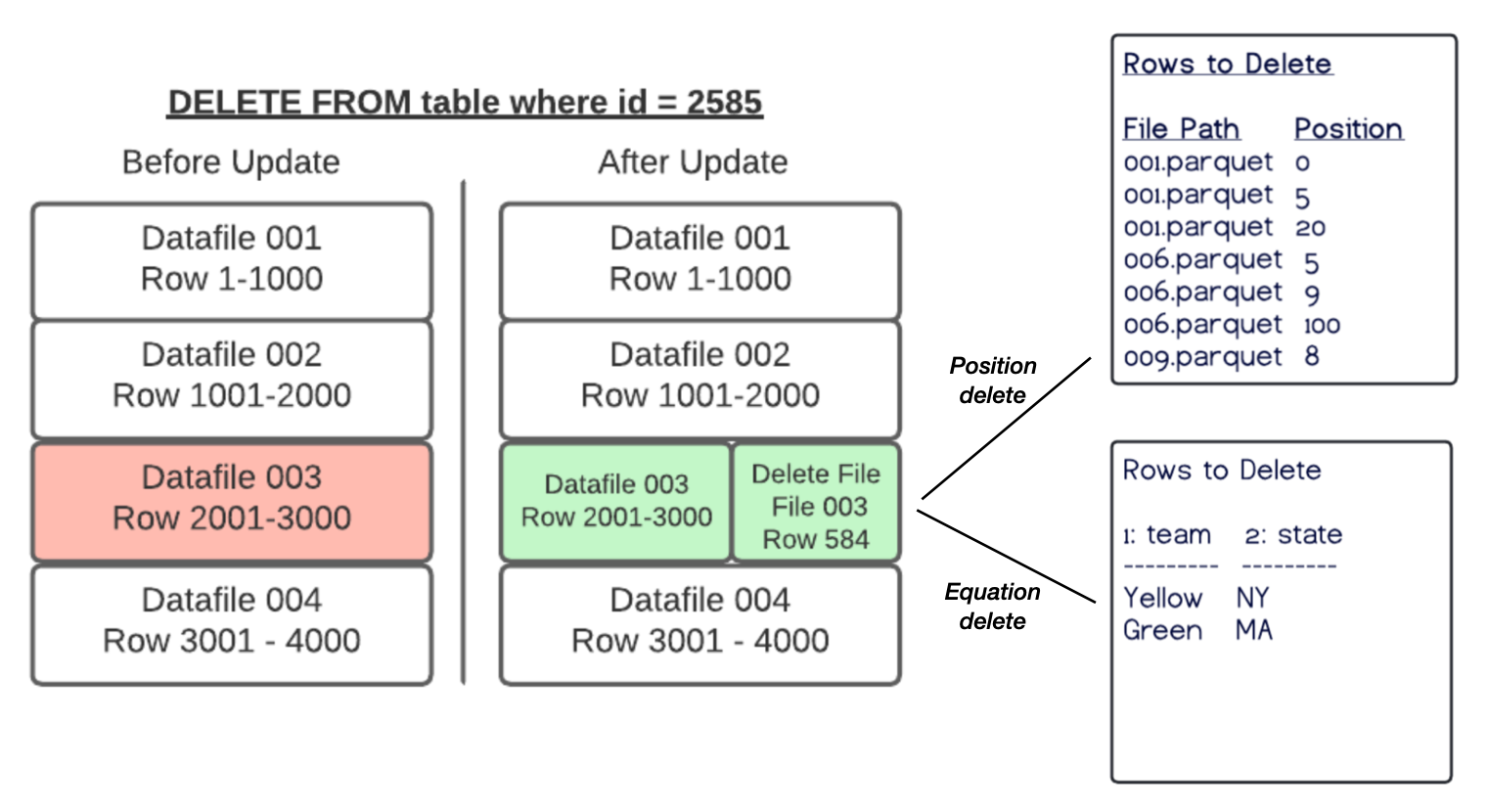 Iceberg MOR 表的实现概述如下:
Iceberg MOR 表的实现概述如下:
- 宏观看是两个存储结构:存储主要数据的列存文件(data file)和存储标记删除的文件(delete file)。data file 和它对应的 delete file 会定期合并成新的 data file。
- 更新流程:update 看做 delete + insert。先向 delete file 追加一条 delete mark 删除老版本,然后把新版本写入 data file。
- Iceberg 的 delete mark 有两种:1. position delete:记录删除行在 data file 中的行号,行号需要在更新的时候从 data file 中查到。 2. equation delete:记录删除的等值条件。equation delete 的写入更高效,尤其是在根据非主键(唯一键)的等值删除场景。这个场景下一个等值条件会匹配很多行。equation delete 只记录一个等值条件,而 position delete 需要为每行查行号并为每行记录 delete mark。
- Iceberg 采用 table-level 乐观锁。更新操作完成后,需要把新增的 delete file 文件登记到表的元数据里面去。如果此时发现别的并发事务往这张表已经登记过元数据,那么自己就 abort(某些情况下会挣扎重试一下)。
- delete mark 和新版本 tuple 加起来的数据量级约等于一个 tuple,所以是 tuple-level update,写放大很小。
- 读取流程:需要 merge 一下 data file 和 delete file(这也是 MOR(merge on read) 名称的由来)。
- 如果是 position delete,只需要按行号顺序地归并 一下(因为行号天然有序)。
- 如果是 equation delete,需要为每一行计算可能很多(每删除一次就多一个)的等值条件是否匹配。
- 二者对比,显然 position delete 的读取更高效。
相比 Hudi COW,Iceberg 的并发能力差了些。抛开并发不谈,Iceberg 算是牺牲了一些读取的性能(需要 merge on read),换取更新的性能。在这个基础上,Iceberg 还提供了 position delete 和 equation delete 两种方式,给用户提供了 MOR 模式下进一步在读友好和写友好之间权衡的空间,这个做法很「用户友好」。
File-level concurrency + tuple-level update
这类方案的典型代表是 Hudi MOR 表。
这类数据库的特点是重视批量更新,但没有 Iceberg 那么极端,所以并发度稍高一点,做到了 file-level。
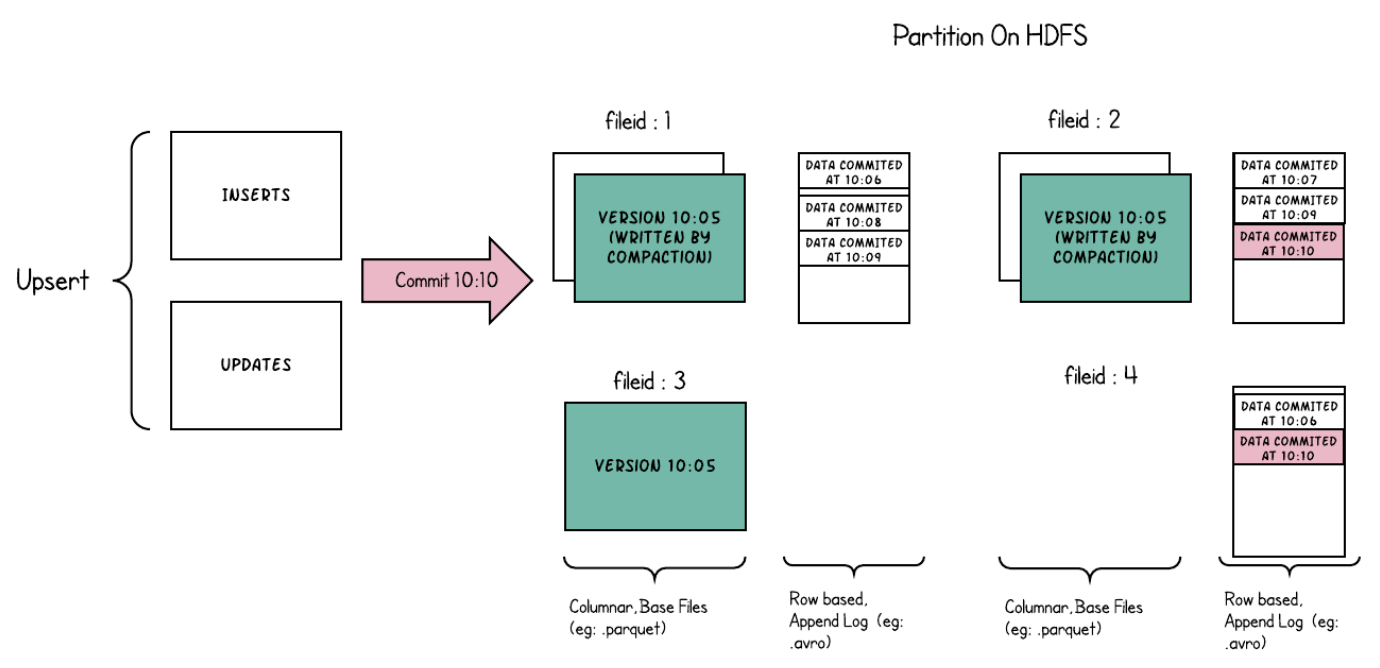 Hudi MOR 表的实现概述如下:
Hudi MOR 表的实现概述如下:
- 宏观看是两个存储结构:存储主要数据的列存文件(base file)和存储增量更新的行存文件(log file)。log file 采用行存对写比较友好。base file 和它对应的 log file 会定期合并成新的 base file。
- 更新流程:update 看做 delete + insert。先向 log file 插入一条 delete mark 来标记删除老版本,然后再向 log file 写入新版本。
- delete mark 记的是主键。但 log file 中的数据是 append 的,并不按照主键排序。
- 更新和 Hudi COW 一样,是 file-level OCC,因此是 file-level concurrency。
- 写入数据量是 delete mark 加新版本的 tuple,因此是 tuple-level update。
- 读取流程:需要 merge 一下 base file 和 log file,实现上是 base file 和 log file 按主键做 hash join。由于 log file 中的数据是无序的,即便通过 zone-map 过滤后只需要读一个 base file 的 block,也要 join 整个 log file。
除了并发度比 Iceberg 高以外,Hudi MOR 和 Iceberg 主要有两个区别。
第一个区别是 delete mark 的实现不同。
写性能方面,Iceberg position delete < Hudi 主键 delete < Iceberg equation delete。
position delete < 主键 delete,是因为 AP 数据库的更新大多数情况下是提供了整行数据的 upsert,这种情况下,主键 delete 可以做到不需要去 base file 中读数据,直接写 log file 就搞定,而 position delete 还得去读行号。
主键 delete < equation delete,这个显而易见,equation delete 在根据非主键(唯一键)的等值删除场景具有绝对的优势。
读性能方面,Iceberg position delete > Hudi 主键 delete > Iceberg equation delete。
因为主键 delete 需要 base file 和 log file 做 hash join,得构建 hash table 和按行 probe。而 position delete 只需要按天然有序的行号归并,因此更快。equation delete 需要每一行计算很多的等值条件,因此更慢。
第二个区别是同一主键的新老版本存储位置不同。Hudi 能保证新老版本逻辑上在同一个 base file 中(在 base file 或者它对应的 log file 中),而 Iceberg 新版本可能出现在不同的 data file 中。相比之下,Iceberg 在实现主键行级别的索引,主键 zone-map 过滤方面出于劣势。
综合来看,没有明显的胜者,二者互有胜负。
Tuple-level concurrency + Field-level update
这类方案的唯一代表是 Kudu。一个数据库自成一类。
这类数据库非常重视单行更新,因此通过行锁来实现并发,实现了 tuple-level concurrency。(注意:我不确定 Kudu 是否还支持表锁,通过 cost 判断该加表锁还是行锁。感兴趣的读者可以自行研究一下。)
这类数据库非常「吝惜」存储空间,因此更新时只记录被更新的 field。
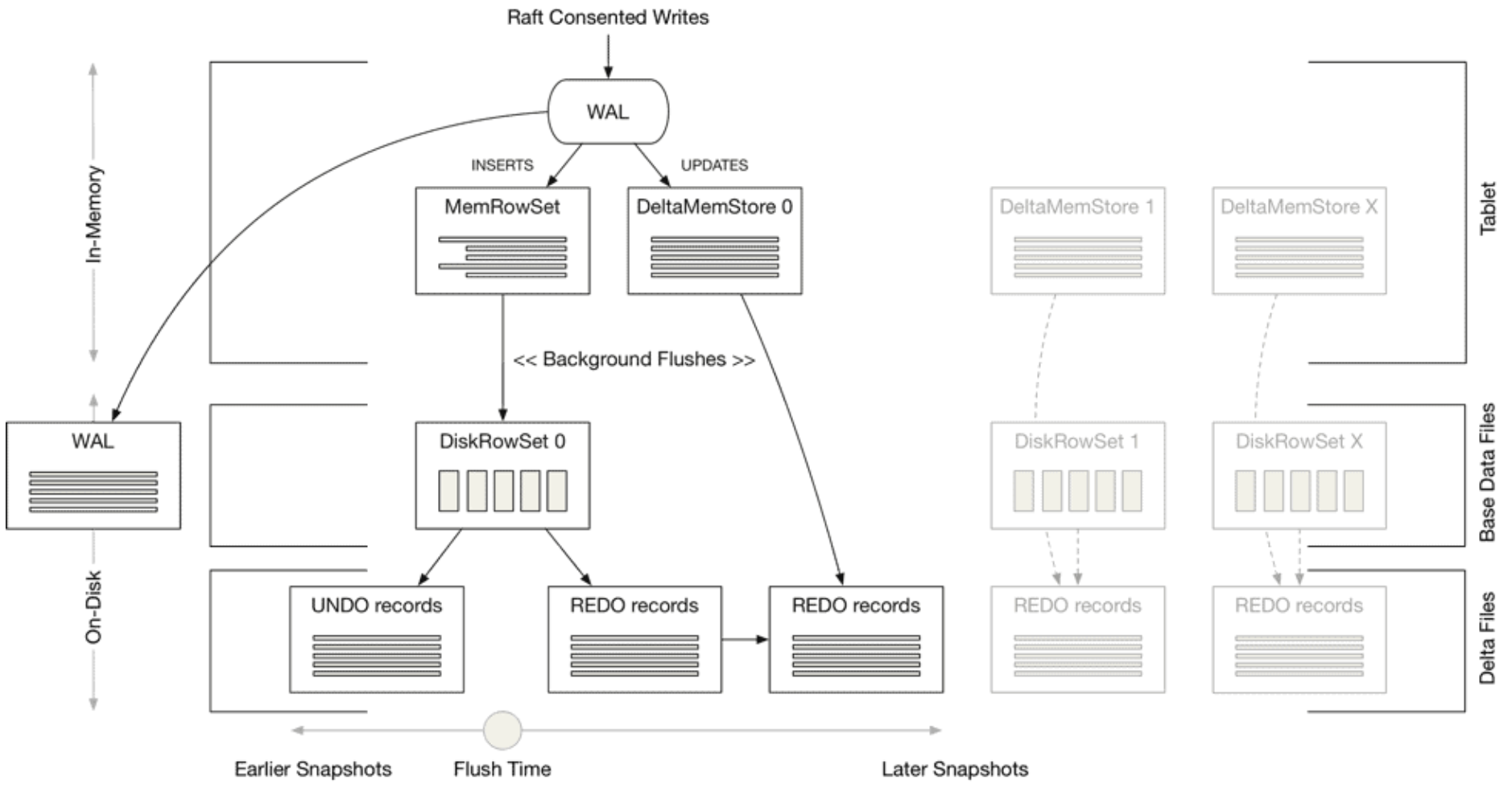 Kudu 的实现概述如下
Kudu 的实现概述如下
- 宏观看有点像一个只有 L0 层的 LSM-tree,但 Kudu 对于写入和更新分类处理。写入和更新分别使用自己的 memtable 和文件。写入写到行存 MemRowSet(Masstree 实现),定期刷盘成为 DiskRowSet 列存文件。更新写到行存 DeltaMemStore,定期刷盘成为 DiskRowSet 对应的 REDO records 文件。DiskRowSet 文件内嵌一个主键 B-tree 索引,用来加速主键点查。DiskRowSet 和 REDO records 文件会被周期性地合并。
- 更新流程:先根据主键查询在 DiskRowSet 中的行号,然后在 DeltaMemStore 中记录行号以及更新后的 field。因为只记了更新后的 field,有点像 redo log,所以文件名叫 REDO records。
- 通过行锁来保证并发更新的事务性,所以是 tuple-level concurrency。
- 写入的数据量只是更新后的 filed,所以是 field-level update。
- 读取流程:需要按行号顺序地归并 DiskRowSet 和 REDO records。
Kudu 的方案是我最喜欢的方案。这个方案写并发高,写放大最小。此外,field-level update 非常有利于大宽表的部分列更新场景,因为不需要花费大量的 IO(每列一次 IO)去补全其他列数据。如果非要找出一个缺点,那就是行锁对批量更新没那么友好。不过这也可以通过动态地选择表锁或者行锁来优化。
Unlimited concurrency + tuple-level update
我创造的 unlimited concurrency 这个术语有点唬人。其实这个术语翻译成人话就是不支持并发更新的事务性——不加任何锁,不检测写写冲突,允许丢失更新(lost-update)。
比如 Doris,并发更新采用 last writer wins 策略,同一行的并发更新,后来的更新会覆盖前面的更新,造成前面的更新丢失。
至于 ADB,我没有看到 ADB 论文中提到并发更新,找官方文档也没找到(也有点迷路了,ADB 有很多版本,MySQL,Postgres 等等,弄晕我了),所以我猜测它也不支持并发更新的事务性,不然没理由不高调宣传。因此,我将 ADB 也归类到了这里。尽管我不能 100% 确定它属于这个分类,但我认为分类错了也问题不大,它不影响本文的核心思想。
由于不支持更新的事务性,这类数据库的单行更新和批量更新都比较快。
提问:牺牲事务性,换取更新的性能,你认为值得吗?欢迎留言讨论。
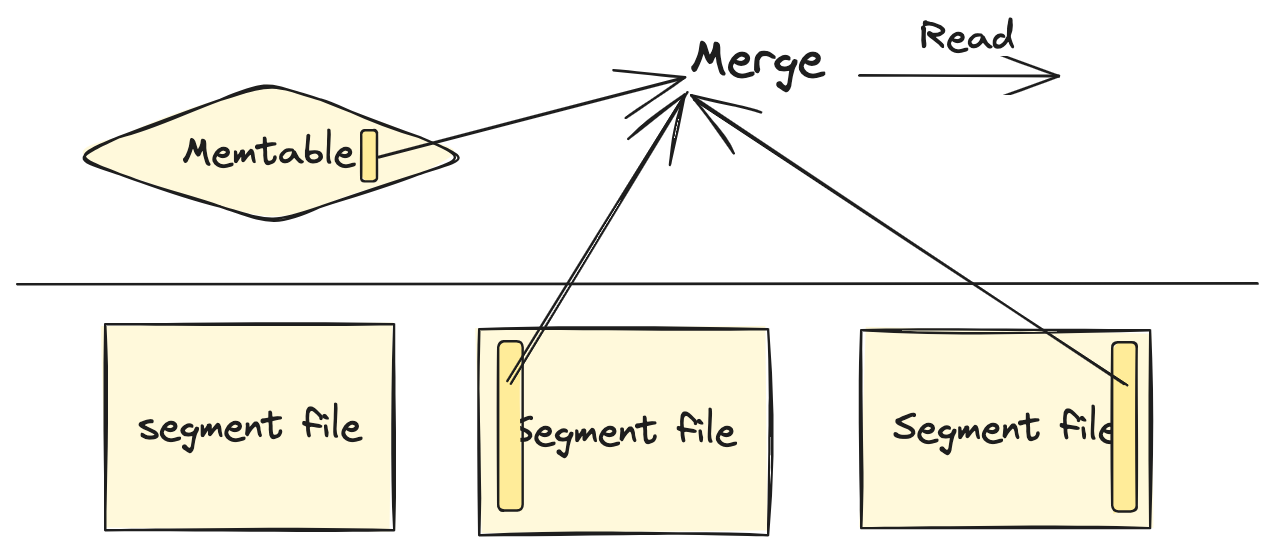 Doris MOR(unique-key 表) 的实现方式概述如下:
Doris MOR(unique-key 表) 的实现方式概述如下:
- 宏观上看是一个 LSM-tree,只有 memtable 和 L0 层列存文件。
- 更新流程:采用 LSM-tree 的做法,直接写入新版本,覆盖旧版本。
- 每个版本上带着一个 sequence number,作为版本排序的依据。
- Doris 默认不支持并发更新(官方文档)。如有需求,可以通过开关打开,但会有丢失更新的异象。因为不支持并发更新的事务性,所以我把 Doris 划分为 unlimited concurrency。
- 写入数据量只是一个 tuple,所以是 tuple-level update。
- 读取流程:需要 merge 多个文件以及 memtable 来找到同一主键的最新版本。
抛开对并发更新事务性的支持不谈,Doris MOR 方案的优点是更新非常快。甚至写入不需要关心是否违反主键唯一约束,因为同一主键的新版本总会覆盖旧版本,保证了绝对的唯一。此外,在提供整行数据的 upsert 场景,Doris 也不需要读老版本数据,直接写新版本就可以搞定。 Doris MOR 的缺点是读取的并行度不高,无法做到 file-level 独立并行读。因为文件之间存在依赖,需要多个文件合并到一起,才能找到最新版本的数据。在这个限制下,聚合函数无法下推到文件层并行计算,读性能比较差。
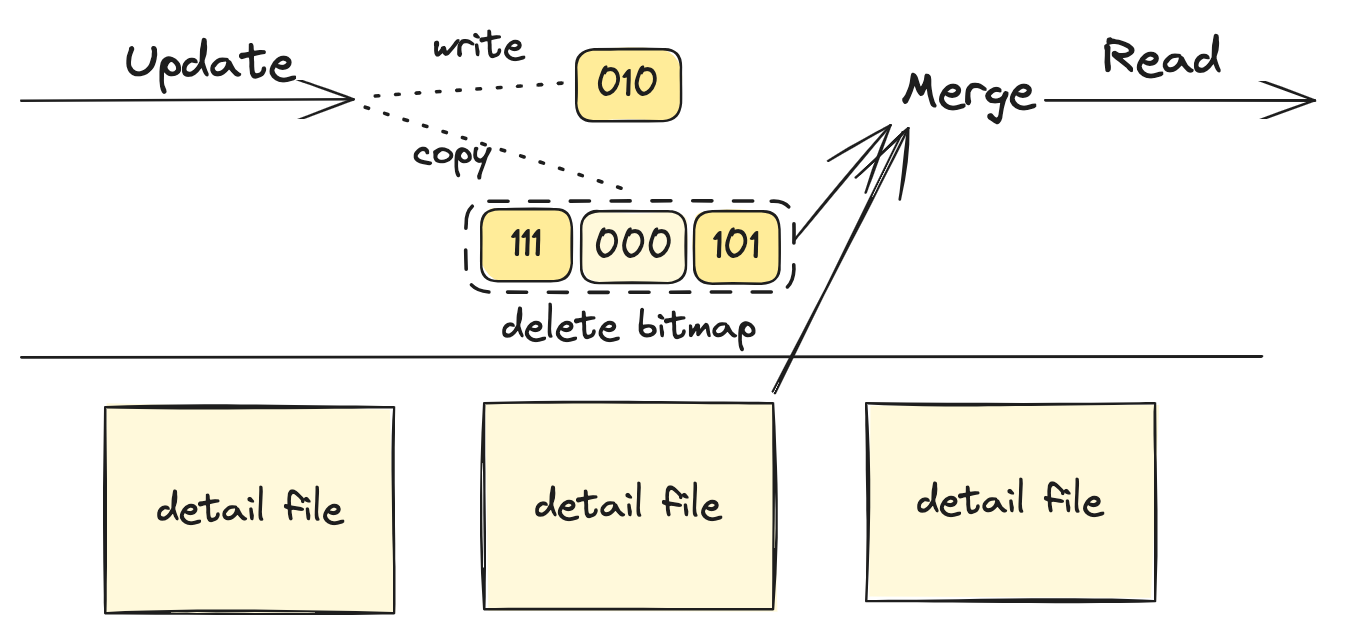 ADB 的实现概述如下:
ADB 的实现概述如下:
- 宏观看存储是两个结构:磁盘上的列存文件(detail file)和内存中的 delete bitmap。delete bitmap 被切分成很多 compressed segment。
- 更新流程:update 看做 delete + insert。先在 delete bitmap 标记删除老版本(把删除行的对应 bit 置 1 表示删除),然后写入新版本。
- delete bitmap 自身的更新通过 segment-level COW 实现,有一定的内存空间开销。
- 疑似不支持并发更新的事务性,所以我把它划分到 unlimited concurrency。
- 写入的数据量是内存 bitmap 的一个 compressed segment,以及磁盘上的一个 tuple。因为我重点关注磁盘的写入量,所以这个方案被分类为 tuple-level update。
- 读取需要 merge 列存文件和对应的 delete bitmap segments。
ADB 方案最特别之处在于 in-memory delete bitmap,优点是标记删除的读写性能都很棒,毕竟内存数据结构的威力不可小觑。缺点是内存开销比较大。
相比与 Doris,ADB 可以实现文件级别甚至更细粒度的并行读。虽然同一主键的新老版本也可能会出现在不同的文件中,但每个文件有自己的 delete bitmap,可用来过滤被删除的数据。每个文件都知道自己的数据要么是新版本的,要么是被删除的,不依赖别的文件来确定,所以可直接并行读。
In-memory delete bitmap + segment-level COW 的内存开销很大。一种优化的思路是将其转化为 on-disk bitmap。Hologres 就采用了 on-disk bitmap 的方案,每个文件一个 delete bitmap(roaring bitmap 实现),存储在整张表一个的 LSM-tree 中。为了省空间,delete bitmap 的更新不是通过 COW 来实现,而是通过 MOR 来实现,即每个增量更新都会生成一个新版本的 bitmap,读的时候合并所有版本。感兴趣的可以阅读下 Hologres 的论文。更进一步地,Doris MOW(merge on write) 表在 Hologres 方案的基础上,为了减小合并多个 bitmap 的开销,还会把合并后的结果缓存起来,详情可以参考 Doris MOW 的设计文档。
总结
| 分类 | file-level concurrency + file-level update | table-level concurrency + tuple-level update | file-level concurrency + tuple-level update | tuple-level concurrency + field-level update | unlimited concurrency + tuple-level update |
|---|---|---|---|---|---|
| 典型代表 | Hudi COW | Iceberg | Hudi MOR | Kudu | Doris MOR, ADB |
| 特点 | 读友好 | 批量更新友好,并发更新差 | 批量更新友好,并发更新中 | 单行更新友好,部分列更新友好,并发更新友好,批量更新一般 | 单行批量更新都友好,事务支持差(不支持并发更新或并发更新异常) |
广告
欢迎关注我的知乎和微信公众号:黄金架构师。

码字不易。如果您觉得我的文章对您有帮助,辛苦点赞收藏转发下,这是对我莫大的鼓励,非常感谢!
留下评论